Cloudera Hadoop Developer Certification Questions and Answer (Dumps and Practice Questions)
Question : We have extracted the data from
MySQL backend database of QuickTechie.com
website and stored in the
Hive table called MAINPROFILE as shown in image
with the sample data and also shown column datatype.
As this table is created from the data
which is already stored in a
warehouse directory of Hive.
Select the correct MapReduce
code which simulate
the following Query
SELECT USERID
FROM MAINPROFILE
WHERE FIRST_NAME = "PANKAJ";
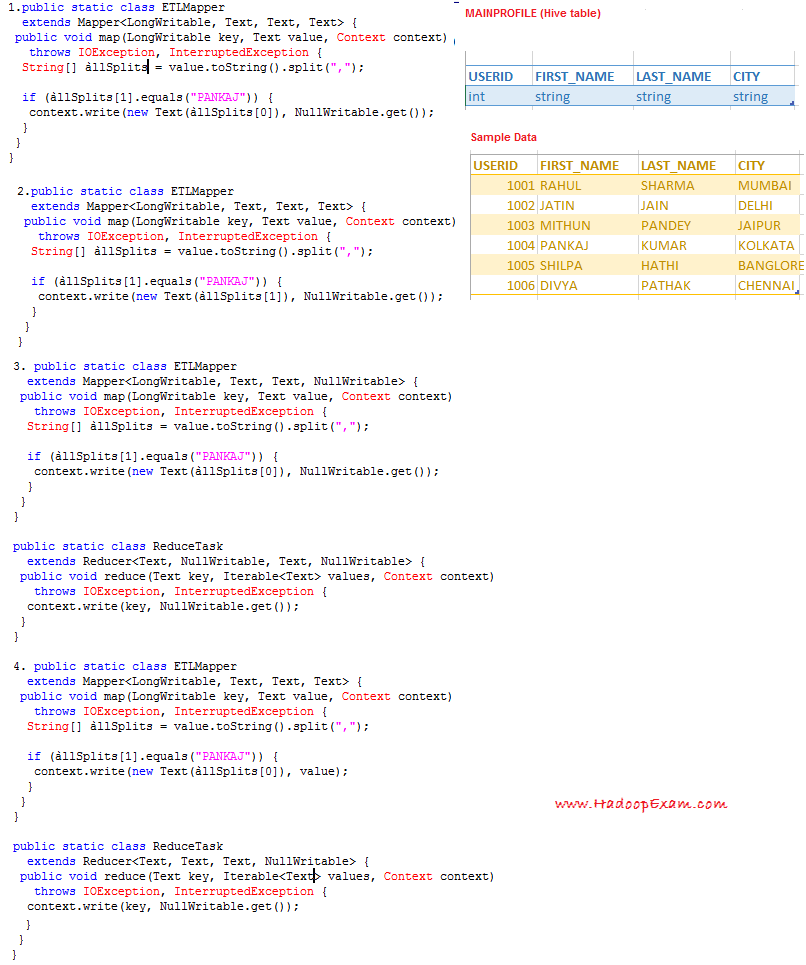
1. 1
2. 2
3. Access Mostly Uused Products by 50000+ Subscribers
4. 4
Correct Answer : Get Lastest Questions and Answer :
Explanation: Option:1 There may be reasons where Map-Only job is needed,Where there is no Reducer to execute.Here Map does all its task with its InputSplit and no job for Reducer.This can be achieved by setting job.setNumReduceTasks() to Zero in Configuration. So the no. of output files will be equal to no. of mappers and output files will be named as part-m-00000. And once Reducer task is set to Zero the result will be unsorted. If we are not specifying this property in Configuration, an Identity Reducer will get executed in which the same value is simply emitted along with the incoming key and the output file will be part-r-00000. In second option It is a wrong conditional check in the ETLreducer is testing whether the USERID field is equal to "PANKAJ". In option three it outputs only distinct USERIDs instead of all USERIDs. In the 4th option it outputs the USERID for all records that have "PANKAJ" in the FIRST_NAME field. all rows are in output, even if the USERIDs are repeating. The mapper emits the full record as the value.The job submitter's view of the Job. It allows the user to configure the job, submit it, control its execution, and query the state. The set methods only work until the job is submitted, afterwards they will throw an IllegalStateException.
Normally the user creates the application, describes various facets of the job via Job and then submits the job and monitor its progress.
Watch the training from http://hadoopexam.com/index.html/#hadoop-training
Related Questions
Question : We have extracted the data from
MySQL backend database of QuickTechie.com
website and stored in the
Hive table called MAINPROFILE as shown in image
with the sample data and also shown column datatype.
As this table is created from the data
which is already stored in a
warehouse directory of Hive.
Select the correct MapReduce
code which simulate
the following Query
SELECT USERID
FROM MAINPROFILE
WHERE FIRST_NAME = "PANKAJ";
1. 1
2. 2
3. Access Mostly Uused Products by 50000+ Subscribers
4. 4
Question : Which statement is true

1. Output of the reducer could be zero
2. Output of the reducer is written to the HDFS
3. In practice, the reducer usually emits a single key-value pair for each input key
4. All of the above
Question : What is data localization ?
1. Before processing the data, bringing them to the local node.
2. Hadoop will start the Map task on the node where data block is kept via HDFS
3. 1 and 2 both are correct
4. None of the 1 and 2 is correct
Question : All the mappers, have to communicate with all the reducers...
1. True
2. False