Cloudera Hadoop Developer Certification Questions and Answer (Dumps and Practice Questions)
Question :We have extracted the data from
MySQL backend database of QuickTechie.com
website and stored in the
Hive table called MAINPROFILE as shown in image
with the sample data and also shown column datatype.
As this table is created from the data
which is already stored in a
warehouse directory of Hive.
As this table is created from the data
which is already stored in a
warehouse directory of Hive.
Select the correct MapReduce
code which simulate
the following Query in a single file.
SELECT FIRST_NAME,CITY,LAST_NAME
FROM MAINPROFILE
ORDER BY CITY;

1. 1
2. 2
3. Access Mostly Uused Products by 50000+ Subscribers
4. 4
Correct Answer : Get Lastest Questions and Answer :
Explanation: here may be reasons where Map-Only job is needed,Where there is no Reducer to execute.Here Map does all its task with its InputSplit and no job for Reducer.This can be achieved by setting job.setNumReduceTasks() to Zero in Configuration. So the no. of output files will be equal to no. of mappers and output files will be named as part-m-00000. And once Reducer task is set to Zero the result will be unsorted. If we are not specifying this property in Configuration, an Identity Reducer will get executed in which the same value is simply emitted along with the incoming key and the output file will be part-r-00000. First option incorrect: the reducer calls methods from the String class on the Text value. In option 2 the mapper emits the CITY as the key with the remaining columns as the value, and the reducer reorders the columns before emitting them. In 3rd the reducer applies a DISTINCT operation that is not present in the Hive QL query.
In option 4 the reducer emits the columns out of order. It's also incorrect because under default submission parameters, the output delimiter is a tab, so when parsed as a CSV, the output will contain only two columns. It allows the user to configure the job, submit it, control its execution, and query the state. The set methods only work until the job is submitted, afterwards they will throw an IllegalStateException.
Normally the user creates the application, describes various facets of the job via Job and then submits the job and monitor its progress.
Watch the training from http://hadoopexam.com/index.html/#hadoop-training
Question : We have extracted the data from
MySQL backend database of QuickTechie.com
website and stored in the
Hive table called MAINPROFILE as shown in image
with the sample data and also shown column datatype.
As this table is created from the data
which is already stored in a
warehouse directory of Hive.
As this table is created from the data
which is already stored in a
warehouse directory of Hive.
Select the correct MapReduce
code which simulate
the following Query in a single file.
SELECT DISTINCT FIRST_NAME
FROM MAINPROFILE
WHERE CITY != "MUMBAI"

1. 1
2. 2
3. Access Mostly Uused Products by 50000+ Subscribers
4. 4
Correct Answer : Get Lastest Questions and Answer :
Explanation: Please refer Hadoop Professional Training from www.HadoopExam.com to understand MapReduce Job in detail.
Question : Given this data file: MAIN.PROFILE.log
1 Feeroz Fremon
2 Jay Jaipur
3 Amit Alwar
10 Banjara Banglore
11 Jayanti Jaipur
101 Sehwag Shimla
You write the following Pig script:
users = LOAD 'MAIN.PROFILE.log' AS (userid, username, city);
sortedusers = ORDER users BY id DESC;
DUMP sortedusers;
The output looks like this:
(3,Amit , Alwar)
(2,Jayanti, Jaipur)
(11,Jane, Jaipur)
(101,Sehwag, Shimla)
(10,Banjara, Banglore)
(1,Feeroz, Fremon)
Choose one line which, when modified as shown, would result in the output being displayed in descending ID order

1. DUMP sortedusers;
2. users = LOAD 'MAIN.PROFILE.log' AS (userid:int, usernamename,city);
3. Access Mostly Uused Products by 50000+ Subscribers
Correct Answer : Get Lastest Questions and Answer :
Explanation:In Pig, when you use an operator which triggers a reduce action, such as GROUP, JOIN, or DISTINCT, the reducer will sort the values according to one of two types of comparators:One optimized for speed, which first compares the byte-length and moves shorter values to the front. The outputs are not in lexicographical order :( One that deserializes the value into a Java object, then calls the compareTo method, producing outputs in lexicographical order :)
Unforunately, in nearly all of our use-cases, Pig will select the optimized comparator, producing output that it not in lexicographical order. This sucks when we are trying to sort-uniq Wayback CDX files. As far as I can tell, there's no easy was to override Pig's choice of comparator.
So, I hacked it: JobControlCompiler.java by adding a check of config property pig.forceTypedComparator to force the selection of the comparator that produces lexicographical order. If you do not specify the data type for fields, Pig assumes they are byte arrays. They will therefore be sorted in lexicographic order, meaning that 2 is considered to be a larger value than 11. One method you could use to fix this is to specify the data type of the id field as int during the load stage.
Watch the training from http://hadoopexam.com/index.html/#hadoop-training
Related Questions
Question : Which statement is true with respect to MapReduce . or YARN

1. It is the newer version of MapReduce, using this performance of the data processing can be increased.
2. The fundamental idea of MRv2 is to split up the two major functionalities of the JobTracker,
resource management and job scheduling or monitoring, into separate daemons.
3. Access Mostly Uused Products by 50000+ Subscribers
4. All of the above
5. Only 2 and 3 are correct
Ans : 5
Exp : MapReduce has undergone a complete overhaul in hadoop-0.23 and we now have, what we call, MapReduce 2.0 (MRv2) or YARN.
The fundamental idea of MRv2 is to split up the two major functionalities of the JobTracker,
resource management and job scheduling or monitoring, into separate daemons. The idea is to have a global ResourceManager (RM)
and per-application ApplicationMaster (AM). An application is either a single job in the classical sense of Map-Reduce jobs or a DAG of jobs.
You can also Refer/Consider Advance Hadoop YARN Training by HadoopExam.com
Question :
Which statement is true about ApplicationsManager

1. is responsible for accepting job-submissions
2. negotiating the first container for executing the application specific ApplicationMaster
and provides the service for restarting the ApplicationMaster container on failure.
3. Access Mostly Uused Products by 50000+ Subscribers
4. All of the above
5. 1 and 2 are correct
Ans : 5
Exp : The ApplicationsManager is responsible for accepting job-submissions,
negotiating the first container for executing the application specific ApplicationMaster and provides the
service for restarting the ApplicationMaster container on failure.
You can also Refer/Consider Advance Hadoop YARN Training by HadoopExam.com
Question :
Which tool is used to list all the blocks of a file ?
1. hadoop fs
2. hadoop fsck
3. Access Mostly Uused Products by 50000+ Subscribers
4. Not Possible
Ans : 2
Question : Identify the MapReduce v (MRv / YARN) daemon responsible for launching application containers and
monitoring application resource usage?
1. ResourceManager
2. NodeManager
3. Access Mostly Uused Products by 50000+ Subscribers
4. ApplicationMasterService
5. TaskTracker.
Ans : 3
Exp :The fundamental idea of MRv2(YARN)is to split up the two major functionalities of the JobTracker, resource
management and job scheduling/monitoring, into separate daemons. The idea is to have a global
ResourceManager (RM) and per-application ApplicationMaster (AM). An application is either a single job in the
classical sense of Map-Reduce jobs or a DAG of jobs.
You can also Refer/Consider Advance Hadoop YARN Training by HadoopExam.com
Question : Identify the tool best suited to import a portion of a relational database every day as files into HDFS, and
generate Java classes to interact with that imported data?
1. Oozie
2. Flume
3. Access Mostly Uused Products by 50000+ Subscribers
4. Hue
5. Sqoop
Ans : 5
Exp :Sqoop ("SQL-to-Hadoop") is a straightforward command-line tool with the following capabilities:
Imports individual tables or entire databases to files in HDFS Generates Java classes to allow you to interact
with your imported data Provides the ability to import from SQL databases straight into your Hive data
warehouse
Data Movement Between Hadoop and Relational Databases
Data can be moved between Hadoop and a relational database as a bulk data transfer, or relational tables can
be accessed from within a MapReduce map function.
Note:
* Cloudera's Distribution for Hadoop provides a bulk data transfer tool (i.e., Sqoop) that imports individual
tables or entire databases into HDFS files. The tool also generates Java classes that support interaction with
the imported data. Sqoop supports all relational databases over JDBC, and Quest Software provides a
connector (i.e., OraOop) that has been optimized for access to data residing in Oracle databases.
Question : Given no tables in Hive, which command will import the entire contents of the LOGIN table
from the database into a Hive table called LOGIN that uses commas (,) to separate the fields in the data files?
1. hive import --connect jdbc:mysql://dbhost/db --table LOGIN --terminated-by ',' --hive-import
2. hive import --connect jdbc:mysql://dbhost/db --table LOGIN --fields-terminated-by ',' --hive-import
3. Access Mostly Uused Products by 50000+ Subscribers
4. sqoop import --connect jdbc:mysql://dbhost/db --table LOGIN --fields-terminated-by ',' --hive-import
Ans : 4
Exp : Sqoop import to a Hive table requires the import option followed by the --table option to specify the database table name and the --hive-import option. If --hive-table is not specified, the Hive table will have the same name as the imported database table. If --hive-overwrite is specified, the Hive table will be overwritten if it exists. If the --fields-terminated-by option is set, it controls the character used to separate the fields in the Hive table's data files.
Watch Hadoop Professional training Module : 22 by www.HadoopExam.com
http://hadoopexam.com/index.html/#hadoop-training
Question : Which two daemons typically run on each slave node in a Hadoop cluster running MapReduce v (MRv) on YARN?
1. TaskTracker
2. Secondary NameNode
3. NodeManager
4. DataNode
5. ZooKeeper
6. JobTracker
7. NameNode
8. JournalNode

1. 1,2
2. 2,3
3. Access Mostly Uused Products by 50000+ Subscribers
4. 5,6
4. 7,8
Question : How does the Hadoop framework determine the number of Mappers required for a MapReduce job on a cluster running MapReduce v (MRv) on YARN?
1. The number of Mappers is equal to the number of InputSplits calculated by the client submitting the job
2. The ApplicationMaster chooses the number based on the number of available nodes
3. Access Mostly Uused Products by 50000+ Subscribers
4. NodeManager where the job's HDFS blocks reside
5. The developer specifies the number in the job configuration
Question : In a Sqoop job Assume $PREVIOUSREFRESH contains a date:time string for the last time the import was run, e.g., '-- ::'.
Which of the following import command control arguments prevent a repeating Sqoop job from downloading the entire EVENT table every day?
1. --incremental lastmodified --refresh-column lastmodified --last-value "$PREVIOUSREFRESH"
2. --incremental lastmodified --check-column lastmodified --last-time "$PREVIOUSREFRESH"
3. Access Mostly Uused Products by 50000+ Subscribers
4. --incremental lastmodified --check-column lastmodified --last-value "$PREVIOUSREFRESH"
Question :
The cluster block size is set to 128MB. The input file contains 170MB of valid input data
and is loaded into HDFS with the default block size. How many map tasks will be run during the execution of this job?
1. 1
2. 2
3. Access Mostly Uused Products by 50000+ Subscribers
4. 4
Question : You have a MapReduce job which is dependent on two external jdbc jars called ojdbc.jar and openJdbc.jar
which of the following command will correctly oncludes this external jars in the running Jobs classpath
1. hadoop jar job.jar HadoopExam -cp ojdbc6.jar,openJdbc6.jar
2. hadoop jar job.jar HadoopExam -libjars ojdbc6.jar,openJdbc6.jar
3. Access Mostly Uused Products by 50000+ Subscribers
4. hadoop jar job.jar HadoopExam -libjars ojdbc6.jar openJdbc6.jar
Ans : 2
Exp : The syntax for executing a job and including archives in the job's classpath is: hadoop jar -libjars ,[,...]
Question : You have a an EVENT table with following schema in the MySQL database.
PAGEID NUMBER
USER VARCHAR2
EVENTTIME DATE
PLACE VARCHAR2
you want to import the table data from the database into HDFS.
Which method is the most efficient way to copy all of the data in the EVENT table into a file in HDFS
1. Use the JDBC connector in the MapReduce job and copy all the data in single file using single reducer.
2. Use Sqoop with the MySQL connector to import the database table to HDFS.
3. Access Mostly Uused Products by 50000+ Subscribers
4. Using Apache Pig JDBCConnector to read data from Oracle and then in HDFS
Ans 2
Exp : The most efficient approach will be to use Sqoop with the MySQL connector.
Beneath the covers it uses the mysqldump command to achieve rapid data export in parallel
Question You have a an EVENT table with following schema in the MySQL database.
PAGEID NUMBER
USER VARCHAR2
EVENTTIME DATE
PLACE VARCHAR2
Now that the database EVENT table has been imported and is stored in the dbimport directory in HDFS,
you would like to make the data available as a Hive table.
Which of the following statements is true? Assume that the data was imported in CSV format.
1. An Hive table can be created with the Hive CREATE command.
2. An external Hive table can be created with the Hive CREATE command that uses the data in the dbimport directory unchanged and in place.
3. Access Mostly Uused Products by 50000+ Subscribers
4. All of the above is correct.
Ans : 2
Exp : An external Hive table can be created that points to any file in HDFS.
The table can be configured to use arbitrary field and row delimeters or even extract fields via regular expressions.
Question : You have Sqoop to import the EVENT table from the database,
then write a Hadoop streaming job in Python to scrub the data,
and use Hive to write the new data into the Hive EVENT table.
How would you automate this data pipeline?
1. Using first Sqoop job and then remaining Part using MapReduce job chaining.
2. Define the Sqoop job, the MapReduce job, and the Hive job as an Oozie workflow job, and define an Oozie coordinator job to run the workflow job daily.
3. Access Mostly Uused Products by 50000+ Subscribers
4. Define the Sqoop job, the MapReduce job, and the Hive job as an Oozie workflow job,
and define an Zookeeper coordinator job to run the workflow job daily.
Ans :2
Exp : In Oozie, scheduling is the function of an Oozie coordinator job.
Oozie does not allow you to schedule workflow jobs
Oozie coordinator jobs cannot aggregate tasks or define workflows;
coordinator jobs are simple schedules of previously defined worksflows.
You must therefore assemble the various tasks into a single workflow
job and then use a coordinator job to execute the workflow job.
Question : Which of the following default character used by Sqoop as field delimiters in the Hive table data file?
1. 0x01
2. 0x001
3. Access Mostly Uused Products by 50000+ Subscribers
4. 0x011
Ans :1
Exp : By default Sqoop uses Hives default delimiters when doing a Hive table export, which is 0x01 (^A)
Question In a Sqoop job Assume $PREVIOUSREFRESH contains a date:time string for the last time the import was run, e.g., '-- ::'.
Which of the following import command control arguments prevent a repeating Sqoop job from downloading the entire EVENT table every day?
1. --incremental lastmodified --refresh-column lastmodified --last-value "$PREVIOUSREFRESH"
2. --incremental lastmodified --check-column lastmodified --last-time "$PREVIOUSREFRESH"
3. Access Mostly Uused Products by 50000+ Subscribers
4. --incremental lastmodified --check-column lastmodified --last-value "$PREVIOUSREFRESH"
Question : You have a log file loaded in HDFS, wich of of the folloiwng operation will allow you to create Hive table using this log file in HDFS.
1. Create an external table in the Hive shell to extract the column data from the logs
2. Create an external table in the Hive shell using org.apache.hadoop.hive.serde2.RegexSerDe to extract the column data from the logs
3. Access Mostly Uused Products by 50000+ Subscribers
4. Create an external table in the Hive shell using org.apache.hadoop.hive.serde2.CSVSerDe to extract the column data from the logs
Ans : 2
Exp : RegexSerDe uses regular expression (regex) to deserialize data.
It doesn't support data serialization. It can deserialize the data using regex and extracts groups as columns.
In deserialization stage, if a row does not match the regex, then all columns in the row will be NULL.
If a row matches the regex but has less than expected groups, the missing groups will be NULL.
If a row matches the regex but has more than expected groups, the additional groups are just ignored.
NOTE: Obviously, all columns have to be strings.
Users can use "CAST(a AS INT)" to convert columns to other types.
NOTE: This implementation is using String, and javaStringObjectInspector.
A more efficient implementation should use UTF-8 encoded Text and writableStringObjectInspector.
We should switch to that when we have a UTF-8 based Regex library.
When building a Hive table from log data, the column widths are not fixed,
so the only way to extract the data is with a regular expression.
The org.apache.hadoop.hive.serde2.RegexSerDe class reads data from a flat file and extracts column information
via a regular expression. The SerDe is specified as part of the table definition when the table is created.
Once the table is created, the LOAD command will add the log files to the table.
Question : For transferring all the stored user profile of QuickTechie.com websites in Oracle Database under table called MAIN.PROFILE
to HDFS you wrote a Sqoop job, Assume $LASTFETCH contains a date:time string for the last time the import was run, e.g., '2015-01-01 12:00:00'.
Select the correct import arguments that prevent a next Sqoop job from transferring the entire MAIN.PROFILE table every day?
1. --incremental lastmodified --last-value "$LASTFETCH"
2. --incremental lastmodified --check-column lastmodified --last-value "$LASTFETCH"
3. Access Mostly Uused Products by 50000+ Subscribers
4. --incremental "$LASTFETCH" --check-column lastmodified --last-value "$LASTFETCH"
Ans : 2 Exp : Sqoop provides an incremental import mode which can be used to retrieve only rows newer than some previously-imported set of rows.
The following arguments control incremental imports:
Incremental import arguments:
Argument Description
--check-column (col) Specifies the column to be examined when determining which rows to import.
--incremental (mode) Specifies how Sqoop determines which rows are new. Legal values for mode include append and lastmodified.
--last-value (value) Specifies the maximum value of the check column from the previous import.
Sqoop supports two types of incremental imports: append and lastmodified. You can use the --incremental argument to specify the type of incremental import to perform. You should specify append mode when importing a table where new rows are continually being added with increasing row id values. You specify the column containing the row's id with --check-column. Sqoop imports rows where the check column has a value greater than the one specified with --last-value.
An alternate table update strategy supported by Sqoop is called lastmodified mode. You should use this when rows of the source table may be updated, and each such update will set the value of a last-modified column to the current timestamp. Rows where the check column holds a timestamp more recent than the timestamp specified with --last-value are imported. At the end of an incremental import, the value which should be specified as --last-value for a subsequent import is printed to the screen. When running a subsequent import, you should specify --last-value in this way to ensure you import only the new or updated data. This is handled automatically by creating an incremental import as a saved job, which is the preferred mechanism for performing a recurring incremental import. See the section on saved jobs later in this document for more information.The --where import control argument lets you specify a select statement to use when importing data,
but it takes a full select statement and must include $CONDITIONS in the WHERE clause.
There is no --since option. The --incremental option does what we want.
Watch Module 22 : http://hadoopexam.com/index.html/#hadoop-training
And refer : http://sqoop.apache.org/docs/1.4.3/SqoopUserGuide.html
Question : For transferring all the stored user profile of QuickTechie.com websites in Oracle Database under table called MAIN.PROFILE
to HDFS you wrote a Sqoop job, Assume $LASTFETCH contains a date:time string for the last time the import was run, e.g., '2015-01-01 12:00:00'.
Finally you have the MAIN.PROFILE table imported into Hive using Sqoop, you need to make this log data available to Hive to perform a join operation.
Assuming you have uploaded the MAIN.PROFILE.log into HDFS, select the appropriate way to creates a Hive table that contains the log data:
1. Create an external table in the Hive shell using org.apache.hadoop.hive.serde2.SerDeStatsStruct to extract the column data from the logs
2. Create an external table in the Hive shell using org.apache.hadoop.hive.serde2.RegexSerDe to extract the column data from the logs
3. Access Mostly Uused Products by 50000+ Subscribers
4. Create an external table in the Hive shell using org.apache.hadoop.hive.serde2.NullStructSerDe to extract the column data from the logs
Ans : 2
Exp : External Tables
The EXTERNAL keyword lets you create a table and provide a LOCATION so that Hive does not use a default location for this table. This comes in handy if you already have data generated. When dropping an EXTERNAL table, data in the table is NOT deleted from the file system.
An EXTERNAL table points to any HDFS location for its storage, rather than being stored in a folder specified by the configuration property hive.metastore.warehouse.dir.
CREATE EXTERNAL TABLE page_view(viewTime INT, userid BIGINT,
page_url STRING, referrer_url STRING,
ip STRING COMMENT 'IP Address of the User',
country STRING COMMENT 'country of origination')
COMMENT 'This is the staging page view table'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\054'
STORED AS TEXTFILE
LOCATION '(hdfs_location)';
You can use the above statement to create a page_view table which points to any hdfs location for its storage. But you still have to make sure that the data is delimited as specified in the CREATE statement above.When building a Hive table from log data, the column widths are not fixed, so the only way to extract the data is with a regular expression. The org.apache.hadoop.hive.serde2.RegexSerDe class reads data from a flat file and extracts column information via a regular expression. The SerDe is specified as part of the table definition when the table is created. Once the table is created, the LOAD command will add the log files to the table. For more information about SerDes in Hive, see How-to: Use a SerDe in Apache Hive and chapter 12 in Hadoop: The Definitive Guide, 3rd Edition in the Tables: Storage Formats section. RegexSerDe uses regular expression (regex) to serialize/deserialize.
It can deserialize the data using regex and extracts groups as columns. It can also serialize the row object using a format string. In deserialization stage, if a row does not match the regex, then all columns in the row will be NULL. If a row matches the regex but has less than expected groups, the missing groups will be NULL. If a row matches the regex but has more than expected groups, the additional groups are just ignored. In serialization stage, it uses java string formatter to format the columns into a row. If the output type of the column in a query is not a string, it will be automatically converted to String by Hive.
Watch Module 12 and 13 : http://hadoopexam.com/index.html/#hadoop-training
And refer : https://hive.apache.org/javadocs/r0.10.0/api/org/apache/hadoop/hive/serde2/package-summary.html
Question : We have extracted the data from
MySQL backend database of QuickTechie.com
website and stored in the
Hive table called MAINPROFILE as shown in image
with the sample data and also shown column datatype.
As this table is created from the data
which is already stored in a
warehouse directory of Hive.
As this table is created from the data
which is already stored in a
warehouse directory of Hive.
Select the correct MapReduce
code which simulate
the following Query in a single file.
SELECT FIRST_NAME, COUNT(FIRST_NAME)
FROM MAINPROFILE
GROUP BY FIRST_NAME;
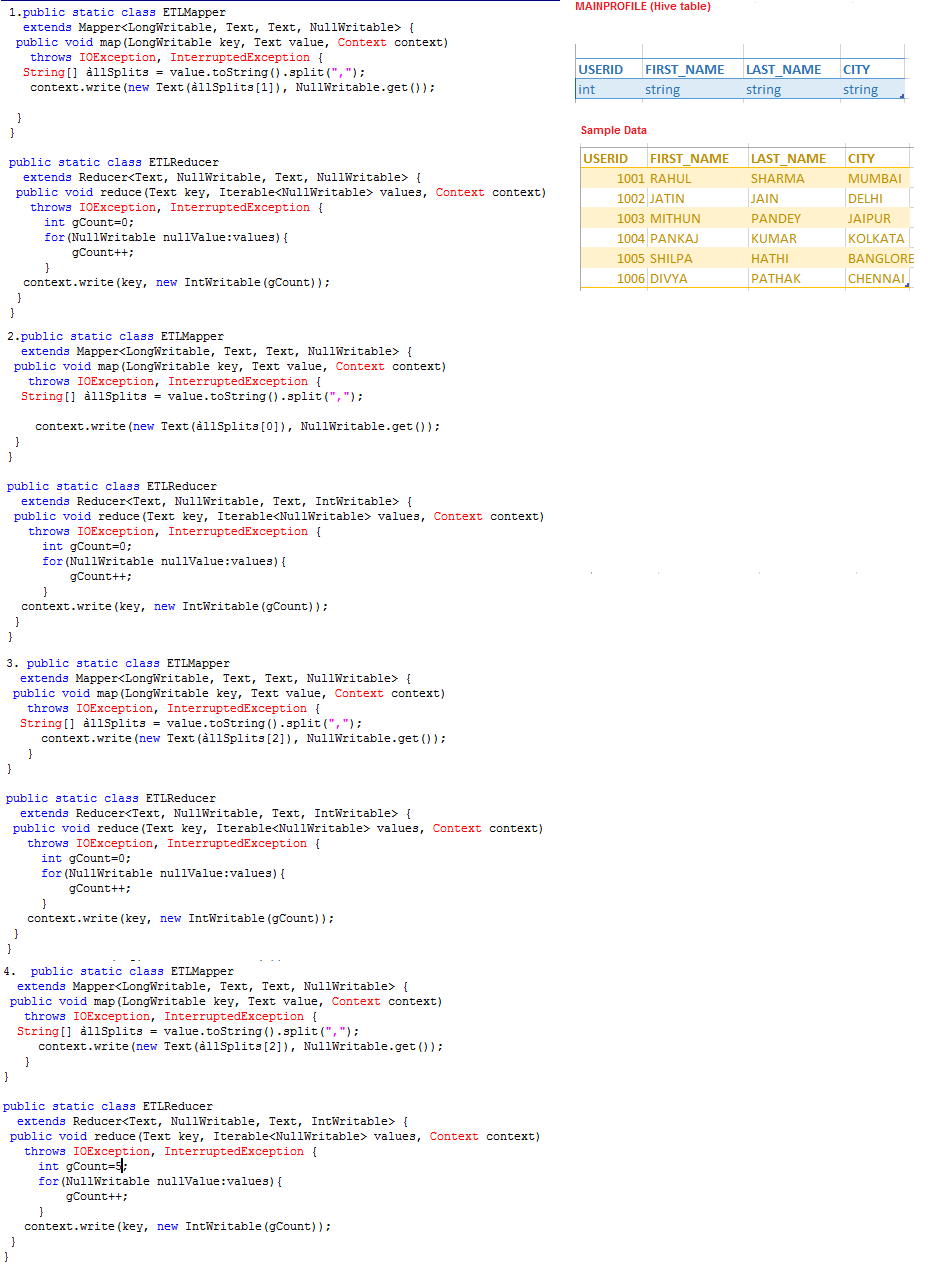
1. 1
2. 2
3. Access Mostly Uused Products by 50000+ Subscribers
4. 4