Cloudera Hadoop Developer Certification Questions and Answer (Dumps and Practice Questions)
Question : In word count MapReduce algorithm, why might using a combiner (Combiner, runs after the Mapper and before the Reducer. )
reduce the overall job running time?

1. combiners perform local filtering of repeated word, thereby reducing the number of key-value pairs that need to be shuffled across the network to the reducers.
2. combiners perform global aggregation of word counts, thereby reducing the number of key-value pairs that need to be shuffled across the network to the reducers.
3. Access Mostly Uused Products by 50000+ Subscribers
4. combiners perform local aggregation of word counts, thereby reducing the number of key-value pairs that need to be shuffled across the network to the reducers.
Correct Answer : Get Lastest Questions and Answer :
Explanation: Combiner: The pipeline showed earlier omits a processing step which can be used for optimizing bandwidth usage by your MapReduce job. Called the Combiner, this pass runs after the Mapper and before the Reducer. Usage of the Combiner is optional. If this pass is suitable for your job, instances of the Combiner class are run on every node that has run map tasks. The Combiner will receive as input all data emitted by the Mapper instances on a given node. The output from the Combiner is then sent to the Reducers, instead of the output from the Mappers. The Combiner is a "mini-reduce" process which operates only on data generated by one machine.
Word count is a prime example for where a Combiner is useful. The Word Count program in listings 1--3 emits a (word, 1) pair for every instance of every word it sees. So if the same document contains the word "cat" 3 times, the pair ("cat", 1) is emitted three times; all of these are then sent to the Reducer. By using a Combiner, these can be condensed into a single ("cat", 3) pair to be sent to the Reducer. Now each node only sends a single value to the reducer for each word -- drastically reducing the total bandwidth required for the shuffle process, and speeding up the job. The best part of all is that we do not need to write any additional code to take advantage of this! If a reduce function is both commutative and associative, then it can be used as a Combiner as well. You can enable combining in the word count program by adding the following line to the driver:
conf.setCombinerClass(Reduce.class);
The Combiner should be an instance of the Reducer interface. If your Reducer itself cannot be used directly as a Combiner because of commutativity or associativity, you might still be able to write a third class to use as a Combiner for your job.The only affect a combiner has is to reduce the number of records that are passed from the mappers to the reducers in the shuffle and sort phase. For more information on combiners, see chapter 2 of Hadoop: The Definitive Guide, 3rd Edition in the Scaling Out: Combiner Functions section.
Watch the training from http://hadoopexam.com/index.html/#hadoop-training
Question : The logical records that FileInputFormats define do not usually fit neatly into HDFS blocks. For example, a TextInputFormat's
logical records are lines, which will cross HDFS boundaries more often than not. This has no bearing on the functioning of your
program-lines are not missed or broken, for example-but it's worth knowing about, as it does mean that data-local maps (that is,
maps that are running on the same host as their input data) will perform some remote reads. The slight overhead this causes is not
normally significant. With the latest version of Hadoop provided by Cloudera, which also include MR2.
You submitted a job to process www.HadoopExam.com single log file , which is made up of two blocks, named BLOCKX and BLOCKY.
BLOCKX is on nodeA, and is being processed by a Mapper running on that node. BLOCKY is on nodeB.
A record spans the two blocks that is, the first part of the record is in BLOCKX,
but the end of the record is in BLOCKY. What happens as the record is being read by the Mapper on NODEA?
1. The remaining part of the record is streamed across the network from either nodeA or nodeB
2. The remaining part of the record is streamed across the network from nodeA
3. Access Mostly Uused Products by 50000+ Subscribers
4. The remaining part of the record is streamed across the network from nodeB
Correct Answer : Get Lastest Questions and Answer :
Explanation: Interesting question, I spent some time looking at the code for the details and here are my thoughts. The splits are handled by the client by InputFormat.getSplits, so a look at FileInputFormat gives the following info:For each input file, get the file length, the block size and calculate the split size as max(minSize, min(maxSize, blockSize)) where maxSize corresponds to mapred.max.split.size and minSize is mapred.min.split.size. Divide the file into different FileSplits based on the split size calculated above. What's important here is that each FileSplit is initialized with a start parameter corresponding to the offset in the input file. There is still no handling of the lines at that point. The relevant part of the code looks like this:
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(new FileSplit(path, length-bytesRemaining, splitSize, blkLocations[blkIndex].getHosts()));
bytesRemaining -= splitSize; } After that, if you look at the LineRecordReader which is defined by the TextInputFormat, that's where the lines are handled: When you initialize your LineRecordReader it tries to instantiate a LineReader which is an abstraction to be able to read lines over FSDataInputStream. There are 2 cases: If there is a CompressionCodec defined, then this codec is responsible for handling boundaries. Probably not relevant to your question. If there is no codec however, that's where things are interesting: if the start of your InputSplit is different than 0, then you backtrack 1 character and then skip the first line you encounter identified by \n or \r\n (Windows) ! The backtrack is important because in case your line boundaries are the same as split boundaries, this ensures you do not skip the valid line. Here is the relevant code: It is very typical for record boundaries not to coincide with block boundaries. If this is the case, the Mapper which is reading the block simply requests more of the file in order to read the rest of the record -- which results in that extra data being streamed across the network. Moving the block would take far longer and would be wasteful.
if (codec != null) { in = new LineReader(codec.createInputStream(fileIn), job);
end = Long.MAX_VALUE; } else { if (start != 0) {
skipFirstLine = true; --start;
fileIn.seek(start); }
in = new LineReader(fileIn, job); }
if (skipFirstLine) { // skip first line and re-establish "start".
start += in.readLine(new Text(), 0, (int)Math.min((long)Integer.MAX_VALUE, end - start)); } this.pos = start; So since the splits are calculated in the client, the mappers don't need to run in sequence, every mapper already knows if it neds to discard the first line or not. So basically if you have 2 lines of each 100Mb in the same file, and to simplify let's say the split size is 64Mb. Then when the input splits are calculated, we will have the following scenario: Split 1 containing the path and the hosts to this block. Initialized at start 200-200=0Mb, length 64Mb. Split 2 initialized at start 200-200+64=64Mb, length 64Mb. Split 3 initialized at start 200-200+128=128Mb, length 64Mb. Split 4 initialized at start 200-200+192=192Mb, length 8Mb. Mapper A will process split 1, start is 0 so don't skip first line, and read a full line which goes beyond the 64Mb limit so needs remote read. Mapper B will process split 2, start is != 0 so skip the first line after 64Mb-1byte, which corresponds to the end of line 1 at 100Mb which is still in split 2, we have 28Mb of the line in split 2, so remote read the remaining 72Mb. Mapper C will process split 3, start is != 0 so skip the first line after 128Mb-1byte, which corresponds to the end of line 2 at 200Mb, which is end of file so don't do anything. Mapper D is the same as mapper C except it looks for a newline after 192Mb-1byte. Watch the training from http://hadoopexam.com/index.html/#hadoop-training
Question : If you run the word count MapReduce program with m map tasks and r reduce tasks,
how many output files will you get at the end of the job, and how many key-value pairs will there be in each file?
Assume k is the number of unique words in the input files. (The word count program reads
text input and produces output that contains every distinct word and the number of times that word occurred anywhere in the text.)
1. There will be r files, each with approximately m/r key-value pairs.
2. There will be m files, each with approximately k/r key-value pairs.
3. Access Mostly Uused Products by 50000+ Subscribers
4. There will be r files, each with approximately k/m key-value pairs.
Correct Answer : Get Lastest Questions and Answer :
Explanation: The WordCount application is quite straightforward. The Mapper implementation, via the map method , processes one line at a time, as provided by the specified TextInputFormat. It then splits the line into tokens separated by whitespace, via the StringTokenizer, and emits a key-value pair of [word, 1].
For the given sample input the first map emits: [Hello, 1] [World, 1] [Bye, 1] [World, 1]
The second map emits: [Hello, 1] [Hadoop, 1] [Goodbye, 1] [Hadoop, 1]
We'll learn more about the number of maps spawned for a given job, and how to control them in a fine-grained manner, a bit later in the tutorial.
WordCount also specifies a combiner. Hence, the output of each map is passed through the local combiner (which is same as the Reducer as per the job configuration) for local aggregation, after being sorted on the keys.
The output of the first map: [Bye, 1] [Hello, 1] [World, 2]
The output of the second map: [Goodbye, 1] [Hadoop, 2] [Hello, 1]
The Reducer implementation, via the reduce method just sums up the values, which are the occurrence counts for each key (that is, words in this example).
Thus the output of the job is: [Bye, 1] [Goodbye, 1] [Hadoop, 2] [Hello, 2] [World, 2]
The run method specifies various facets of the job, such as the input/output paths (passed via the command line), key-value types, input/output formats etc., in the JobConf. It then calls the JobClient.runJob to submit the and monitor its progress.We'll learn more about JobConf, JobClient, Tool, and other interfaces and classes a bit later in the tutorial.The word count job emits each unique word once with the count of the number of occurences of that word. There will therefore be k total words in the output. As the job is executing with r reduce tasks, there will be r output files, one for each mapper. The word keys are distributed more or less evenly among the reducers, so each output file will contian roughly k/r words. Note that the number of map tasks is irrelevant, as the intermediate output from all map tasks is combined together as part of the shuffle phase.
To read more about the word count example, see the Word Count Example on the Hadoop Wiki. For more information about how intermediate and final output are generated the see chapter 2 in Hadoop: The Definitive Guide, 3rd Edition in the Scaling Out: Data Flow section.
Watch the training from http://hadoopexam.com/index.html/#hadoop-training
Related Questions
Please find the answer to this Question at following URL in detail with explaination.
www.hadoopexam.com/P5_A55.jpg
Dont Remember Answers, please understand MapReduce in Depth. It is needed to clear live Question Exam Pattern
Question You have given following input file data..
119:12,Hadoop,Exam,ccd410
312:44,Pappu,Pass,cca410
441:53,"HBasa","Pass","ccb410"
5611:01',"No Event",
7881:12,Hadoop,Exam,ccd410
3451:12,HadoopExam
Special characters . * + ? ^ $ { [ ( | ) \ have special meaning and must be escaped with \ to be used without the special meaning : \. \* \+ \? \^ \$ \{ \[ \( \| \) \\Consider the meaning of regular expression as well
. any char, exactly 1 time
* any char, 0-8 times
+ any char, 1-8 times
? any char, 0-1 time
^ start of string (or line if multiline mode)
$ end of string (or line if multiline mode)
| equivalent to OR (there is no AND, check the reverse of what you need for AND)
After running the following MapReduce job what will be the output printed at console

1. 2 , 3
2. 2 , 4
3. Access Mostly Uused Products by 50000+ Subscribers
4. 5 , 1
5. 0 , 6
Correct Ans : 5
Exp : Meaning of regex as . any char, exactly 1 time (Please remember the regex)
* any char, 0-8 times
+ any char, 1-8 times
? any char, 0-1 time
^ start of string (or line if multiline mode)
$ end of string (or line if multiline mode)
| equivalent to OR (there is no AND, check the reverse of what you need for AND). First Record passed the regular expression
Second record also pass the expression
third record does not pass the expression, because hours part is in single digit as you can sse in the expression
first two d's are there.
It is expected that each record should have at least all five character as digit. Which no record suffice.
Hence in total matching records are 0 and non-matching records are 6
Please learn java regular expression it is mandatrory. Consider using Hadoop Professional Training Provided by HadoopExam.com if you face the problem.
Question
What happens when you run the below job twice , having each input directory as one of the data file called data.csv.
with following command. Assuming there were no output directory exist
hadoop job HadoopExam.jar HadoopExam inputdata_1 output
hadoop job HadoopExam.jar HadoopExam inputdata_2 output
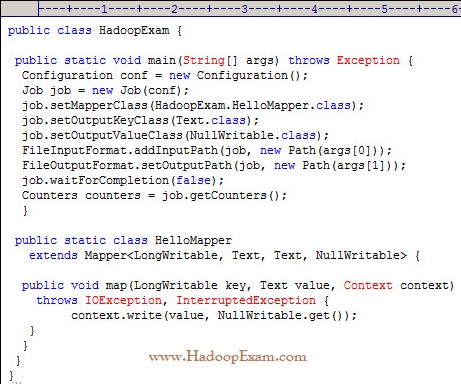
1. Both the job will write the output to output directoy and output will be appended
2. Both the job will fail, saying output directory does not exist.
3. Access Mostly Uused Products by 50000+ Subscribers
4. Both the job will successfully completes and second job will overwrite the output of first.
Ans : 3
Exp : First job will successfully run and second one will fail, because, if (output directory already exist then it will not run
and throws exception, complaining output directory already exist.
Question You have a an EVENT table with following schema in the Oracle database.
PAGEID NUMBER
USER VARCHAR2
EVENTTIME DATE
PLACE VARCHAR2
Which of the following command creates the correct HIVE table named EVENT

1.
2.
3. Access Mostly Uused Products by 50000+ Subscribers
4.
Ans : 2
Exp : The above is correct because it correctly uses the Sqoop operation to create a Hive table that matches the database table.
Option 3rd is not correct because --hive-table option for Sqoop requires a parameter that names the target table in the database.
Question : Which of the following command will delete the Hive table nameed EVENTINFO
1. hive -e 'DROP TABLE EVENTINFO'
2. hive 'DROP TABLE EVENTINFO'
3. Access Mostly Uused Products by 50000+ Subscribers
4. hive -e 'TRASH TABLE EVENTINFO'
1.
2.
3. Access Mostly Uused Products by 50000+ Subscribers
4.
Ans :1
Exp : Sqoop does not offer a way to delete a table from Hive, although it will overwrite the table definition during
import if the table already exists and --hive-overwrite is specified. The correct HiveQL statement to drop a table
is "DROP TABLE tablename". In Hive, table names are all case insensitives
Question There is no tables in Hive, which command will
import the entire contents of the EVENT table from
the database into a Hive table called EVENT
that uses commas (,) to separate the fields in the data files?

1.
2.
3. Access Mostly Uused Products by 50000+ Subscribers
4.
Ans :2
Exp : --fields-terminated-by option controls the character used to separate the fields in the Hive table's data files.
Question :
You have following data in a hive table
ID:INT,COLOR:TEXT,WIDTH:INT
1,green,190
2,blue,300
3,yellow,220
4,blue,199
5,green,199
6,yellow,299
7,green,799
Select the correct Mapper and Reducer which
can produce the output similar to following queries
Select id,color,width from table where width >=200;

1. 1
2. 2
3. Access Mostly Uused Products by 50000+ Subscribers
4. 4
Question :
You have following data in a hive table
ID:INT,COLOR:TEXT,WIDTH:INT
1,green,190
2,blue,300
3,yellow,220
4,blue,199
5,green,199
6,yellow,299
7,green,799
After running thje following MapReduce program, what output it will produces as first line.

1. 1,green,190
2. 4,blue,199
3. Access Mostly Uused Products by 50000+ Subscribers
4. it will through java.lang.ArrayIndexOutOfBoundsException
Question :
You have following data in a hive table
ID:INT,COLOR:TEXT,WIDTH:INT
1,green,190
2,blue,300
3,yellow,220
4,blue,199
5,green,199
6,yellow,299
7,green,799
Select the correct MapReduce program
which can produce the output similar
to below Hive Query.
Select color from table where width >=220;

1. 1
2. 2
3. Access Mostly Uused Products by 50000+ Subscribers
4. 4
Question :
You have following data in a hive table
ID:INT,COLOR:TEXT,WIDTH:INT
1,green,190
2,blue,300
3,yellow,220
4,blue,199
5,green,199
6,yellow,299
7,green,799
Select the correct MapReduce program which
can produce the output similar to below Hive Query.
Select id,color from table where width >=220;

1. 1
2. 2
3. Access Mostly Uused Products by 50000+ Subscribers
4. 4
Question :
You have following data in a hive table
ID:INT,COLOR:TEXT,WIDTH:INT
1,green,190
2,blue,300
3,yellow,220
4,blue,199
5,green,199
6,yellow,299
7,green,799
Select the correct MapReduce program which can produce
the output similar to below Hive Query
(Assuming single reducer is configured).
Select color,max(width) from table group by color;

1. 1
2. 2
3. Access Mostly Uused Products by 50000+ Subscribers
4. 4
Question :
You have following data in a hive table
ID:INT,COLOR:TEXT,WIDTH:INT
1,green,190
2,blue,300
3,yellow,220
4,blue,199
5,green,199
6,yellow,299
7,green,799
Select the correct MapReduce program
which can produce the output similar to below Hive Query
Select id,color,max(width) from table ;

1. 1
2. 2
3. Access Mostly Uused Products by 50000+ Subscribers
4. 4