Cloudera Databricks Data Science Certification Questions and Answers (Dumps and Practice Questions)
Question : Which data asset is an example of quasi-structured data?

1. Webserver log
2. XML data file
3. Access Mostly Uused Products by 50000+ Subscribers
4. News article
Ans : 1
Exp : Types of quasi-structured data and examples of each
totally unstructured data - google search results cover all websites, but are hard to further categorize without access the google database itself
intuitive-structure - my wordtree algorithm accepts any pasted text and yields a network map based on similarity of langauge within the text, as well as proximity of words to each other within the text. But it is not "tagged" the way youtube and flickr track content in images
emergent structure - algorithms to extract the main idea of groups of stories
pseudo-structuring - looking at content and assigning structure to all possible variations of a single document type, such as I did with the auditing tool.
guess, apply a rule, and refine - in this mode the algorithm tries an approach and refines it iteratively based on user feedback. IF the feedback is automated in the form of a score on the result, this approach becomes evolutionary programming.
(I am still figuring out how to describe this - so some of these above examples may be the same thing.)
These strategies for structuring Big Data have come about as a consequence of two trends. First - 100 times more content is added online each year than the sum of all books ever written in history. Second - most of this content is structured by institutions that for various reasons don't want to release the fully annotated version of the information. So pragmatic programmers like me build "wrappers" to restructure the parts that are available. Eventually there will be a universal wrapper for all content about financial records, and another one for all organization reports. These data sets will organize content into clusters that are similar enough for us to study patterns on a global scale. That's when "big data" begins to get interesting. Today, we're in the early stages of deconstructing the structure so that we can reconstruct larger data sets from the individual parts that each have unique yet "incompatible" structures. It is like taking apart all the cars in a junk yard so we can categorize all the parts and deliver them to customers that want to build fresh cars. You see cars go in and cars go out, but a lot happens in between.
Last year, if someone had asked you to track all the work you do on your computer, you would have probably filled out a survey (like the "time tracking" reports I fill out monthly at work). In the future your computer will fill them out for you and in greater detail, and these data will be "mashable" with other reporting systems. This will not happen because two systems are built to work together, but instead because someone build a third system that allows two systems to share information. Eventually we will build "genetic algorithms" that will write programs that can re-organize data into usable structures regardless of how the original data was structured. This is going to happen in the next ten years and we will ask ourselves why we didn't do it sooner.
Question : What would be considered "Big Data"?

1. An OLAP Cube containing customer demographic information about 100, 000, 000 customers
2. Daily Log files from a web server that receives 100, 000 hits per minute
3. Access Mostly Uused Products by 50000+ Subscribers
4. Spreadsheets containing monthly sales data for a Global 100 corporation
Ans : 2
Exp :
Question : A data scientist plans to classify the sentiment polarity of , product reviews collected from
the Internet. What is the most appropriate model to use? Suppose labeled training data is
available.
1. Naive Bayesian classifier
2. Linear regression
3. Access Mostly Uused Products by 50000+ Subscribers
4. K-means clustering
Ans : 1
Exp :
Question : In which lifecycle stage are test and training data sets created?
1. Model building
2. Model planning
3. Access Mostly Uused Products by 50000+ Subscribers
4. Data preparation
Ans : 1
Exp :
Question : Your company has different sales teams. Each team's sales manager has developed incentive
offers to increase the size of each sales transaction. Any sales manager whose incentive program
can be shown to increase the size of the average sales transaction will receive a bonus.
Data are available for the number and average sale amount for transactions offering one of the
incentives as well as transactions offering no incentive.
The VP of Sales has asked you to determine analytically if any of the incentive programs has
resulted in a demonstrable increase in the average sale amount. Which analytical technique would
be appropriate in this situation?
1. One-way ANOVA
2. Multi-way ANOVA
3. Access Mostly Uused Products by 50000+ Subscribers
4. Wilcoxson Rank Sum Test
Ans : 1
Exp :
Question : In data visualization, what is used to focus the audience on a key part of a chart?
1. Emphasis colors
2. Detailed text
3. Access Mostly Uused Products by 50000+ Subscribers
4. A data table
Ans : 1
Exp :
Question : Under which circumstance do you need to implement N-fold cross-validation after creating a
regression model?
1. There is not enough data to create a test set.
2. The data is unformatted.
3. Access Mostly Uused Products by 50000+ Subscribers
4. There are categorical variables in the model.
Ans : 1
Exp :
Question : What is an appropriate data visualization to use in a presentation for an analyst audience?
1. Pie chart
2. Area chart
3. Access Mostly Uused Products by 50000+ Subscribers
4. ROC curve
Ans : 4
Exp :
Question : Which type of numeric value does a logistic regression model estimate?
1. Probability
2. A p-value
3. Access Mostly Uused Products by 50000+ Subscribers
4. Any real number
Ans : 1
Exp :
Question : Your colleague, who is new to Hadoop, approaches you with a question. They want to know how
best to access their data. This colleague has a strong background in data flow languages and
programming. Which query interface would you recommend?
1. Pig
2. Hive
3. Access Mostly Uused Products by 50000+ Subscribers
4. HBase
Correct Answer : Get Lastest Questions and Answer :
Explanation:
The web analytics team uses Hadoop to process access logs. They now want to correlate this
data with structured user data residing in a production single-instance JDBC database. They
collaborate with the production team to import the data into Hadoop. Which tool should they use?
1. Sqoop
2. Pig
3. Access Mostly Uused Products by 50000+ Subscribers
4. Scribe
Ans : 1
Explanation:
Question : The web analytics team uses Hadoop to process access logs. They now want to correlate this
data with structured user data residing in their massively parallel database. Which tool should they
use to export the structured data from Hadoop?
1. Sqoop
2. Pig
3. Access Mostly Uused Products by 50000+ Subscribers
4. Scribe
Ans : 1
Exp :
Question : When would you prefer a Naive Bayes model to a logistic regression model for classification?
1. When you are using several categorical input variables with over 1000 possible values each.
2. When you need to estimate the probability of an outcome, not just which class it is in.
3. Access Mostly Uused Products by 50000+ Subscribers
4. When some of the input variables might be correlated.
Ans : 1
Exp :
Question : You have fit a decision tree classifier using input variables. The resulting tree used of the
variables, and is 5 levels deep. Some of the nodes contain only 3 data points. The AUC of the
model is 0.85. What is your evaluation of this model?
1. The tree is probably overfit. Try fitting shallower trees and using an ensemble method.
2. The AUC is high, and the small nodes are all very pure. This is an accurate model.
3. Access Mostly Uused Products by 50000+ Subscribers
accurate model
4. The AUC is high, so the overall model is accurate. It is not well-calibrated, because the small
nodes will give poor estimates of probability.
Ans : 1
Exp :
Question : If your intention is to show trends over time, which chart type is the most appropriate way to depict
the data?
1. Line chart
2. Bar chart
3. Access Mostly Uused Products by 50000+ Subscribers
4. Histogram
Ans : 1
Exp :
Question : In which phase of the data analytics lifecycle do Data Scientists spend the most time in a project?
1. Discovery
2. Data Preparation
3. Access Mostly Uused Products by 50000+ Subscribers
4. Communicate Results
Ans : 2
Exp :
Question : You are testing two new weight-gain formulas for puppies. The test gives the results:
Control group: 1% weight gain
Formula A. 3% weight gain
Formula B. 4% weight gain
A one-way ANOVA returns a p-value = 0.027
What can you conclude?
1. Either Formula A or Formula B is effective at promoting weight gain.
2. Formula B is more effective at promoting weight gain than Formula A.
3. Access Mostly Uused Products by 50000+ Subscribers
4. Formula A and Formula B are about equally effective at promoting weight gain.
Ans : 1
Exp :
Question : Data visualization is used in the final presentation of an analytics project. For what else is this
technique commonly used?
1. Data exploration
2. Descriptive statistics
3. Access Mostly Uused Products by 50000+ Subscribers
4. Model selection
Ans : 1
Exp :
Question : Which functionality do regular expressions provide?
1. text pattern matching
2. underflow prevention
3. Access Mostly Uused Products by 50000+ Subscribers
4. decreased processing complexity
Ans : 1
Exp :
Question : The average purchase size from your online sales site is $, . The customer experience team
believes a certain adjustment of the website will increase sales. A pilot study on a few hundred
customers showed an increase in average purchase size of $1.47, with a significance level of
p=0.1.
The team runs a larger study, of a few thousand customers. The second study shows an
increased average purchase size of $0.74, with a significance level of 0.03. What is your
assessment of this study?
1. The change in purchase size is not practically important, and the good p-value of the second
study is probably a result of the large study size.
2. The change in purchase size is small, but may aggregate up to a large increase in profits over
the entire customer base.
3. Access Mostly Uused Products by 50000+ Subscribers
should run another, larger study.
4. The p-value of the second study shows a statistically significant change in purchase size. The
new website is an improvement.
Ans : 1
Exp :
Question : Which word or phrase completes the statement? Business Intelligence is to monitoring trends as
Data Science is to ________ trends.

1. Predicting
2. Discarding
3. Access Mostly Uused Products by 50000+ Subscribers
4. Optimizing
Ans : 1
Exp :
Question : Consider a scale that has five () values that range from "not important" to "very important". Which
data classification best describes this data?
1. Ordinal
2. Nominal
3. Access Mostly Uused Products by 50000+ Subscribers
4. Ratio
Ans : 1
Exp :
Question : Which analytical method is considered unsupervised?
1. K-means clustering
2. Naive Bayesian classifier
3. Access Mostly Uused Products by 50000+ Subscribers
4. Linear regression
Ans : 1
Exp :
Question : You have used k-means clustering to classify behavior of , customers for a retail store.
You decide to use household income, age, gender and yearly purchase amount as measures. You
have chosen to use 8 clusters and notice that 2 clusters only have 3 customers assigned. What
should you do?
1. Decrease the number of clusters
2. Increase the number of clusters
3. Access Mostly Uused Products by 50000+ Subscribers
4. Identify additional measures to add to the analysis
Ans : 1
Exp :
Question For which class of problem is MapReduce most suitable?
1. Embarrassingly parallel
2. Minimal result data
3. Access Mostly Uused Products by 50000+ Subscribers
4. Non-overlapping queries
Ans : 1
Exp :
Question You are building a logistic regression model to predict whether a tax filer will be audited within the
next two years. Your training set population is 1000 filers. The audit rate in your training data is
4.2%. What is the sum of the probabilities that the model assigns to all the filers in your training set
that have been audited?
1. 42
2. 4.2
3. Access Mostly Uused Products by 50000+ Subscribers
4. 0.042
Ans : 1
Exp :
Question Refer to exhibit.
You are asked to write a report on how specific variables impact your client's sales using a data
set provided to you by the client. The data includes 15 variables that the client views as directly
related to sales, and you are restricted to these variables only.
After a preliminary analysis of the data, the following findings were made:
1. Multicollinearity is not an issue among the variables
2. Only three variables-A, B, and C-have significant correlation with sales
You build a linear regression model on the dependent variable of sales with the independent
variables of A, B, and C. The results of the regression are seen in the exhibit.
You cannot request additional datA. what is a way that you could try to increase the R2 of the
model without artificially inflating it?
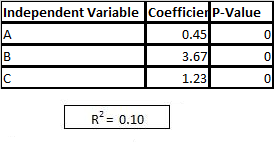
1. Create clusters based on the data and use them as model inputs
2. Force all 15 variables into the model as independent variables
3. Access Mostly Uused Products by 50000+ Subscribers
4. Break variables A, B, and C into their own univariate models
Ans : 1
Exp :
Question You are given , , user profile pages of an online dating site in XML files, and they are
stored in HDFS. You are assigned to divide the users into groups based on the content of their
profiles. You have been instructed to try K-means clustering on this data. How should you
proceed?
1. Run MapReduce to transform the data, and find relevant key value pairs.
2. Divide the data into sets of 1, 000 user profiles, and run K-means clustering in RHadoop iteratively.
3. Access Mostly Uused Products by 50000+ Subscribers
4. Partition the data by XML file size, and run K-means clustering in each partition.
Ans : 1
Exp :
Question : A call center for a large electronics company handles an average of , support calls a day.
The head of the call center would like to optimize the staffing of the call center during the rollout of
a new product due to recent customer complaints of long wait times. You have been asked to
create a model to optimize call center costs and customer wait times.
The goals for this project include:
1. Relative to the release of a product, how does the call volume change over time?
2. How to best optimize staffing based on the call volume for the newly released product, relative
to old products.
3. Access Mostly Uused Products by 50000+ Subscribers
4. Determine the frequency of calls by both product type and customer language.
Which goals are suitable to be completed with MapReduce?
1. 2,4
2. 1,3
3. Access Mostly Uused Products by 50000+ Subscribers
4. 2,3,4
Ans : 1
Exp :
Question : You are studying the behavior of a population, and you are provided with multidimensional data at
the individual level. You have identified four specific individuals who are valuable to your study,
and would like to find all users who are most similar to each individual. Which algorithm is the
most appropriate for this study?
1. K-means clustering
2. Linear regression
3. Access Mostly Uused Products by 50000+ Subscribers
4. Decision trees
Ans : 1
Exp :
Question A disk drive manufacturer has a defect rate of less than .% with % confidence. A quality
assurance team samples 1000 disk drives and finds 14 defective units. Which action should the
team recommend?
1. The manufacturing process should be inspected for problems.
2. A larger sample size should be taken to determine if the plant is functioning properly
3. Access Mostly Uused Products by 50000+ Subscribers
4. The manufacturing process is functioning properly and no further action is required.
Ans : 1
Exp :
Question A data scientist wants to predict the probability of death from heart disease based on three risk
factors: age, gender, and blood cholesterol level.
What is the most appropriate method for this project?
1. Linear regression
2. K-means clustering
3. Access Mostly Uused Products by 50000+ Subscribers
4. Logistic regression
Ans : 4
Exp :
Question : What are the characteristics of Big Data?
1. Data volume, business importance, and data structure variety.
2. Data volume, processing complexity, and data structure variety.
3. Access Mostly Uused Products by 50000+ Subscribers
4. Data volume, processing complexity, and business importance.
Ans : 2
Exp :
Question You are analyzing data in order to build a classifier model. You discover non-linear data and
discontinuities that will affect the model. Which analytical method would you recommend?
1. Logistic Regression
2. Decision Trees
3. Access Mostly Uused Products by 50000+ Subscribers
4. Linear Regression
Ans : 2
Exp :
Question : What is an appropriate data visualization to use in a presentation for a project sponsor?
1. Bar chart
2. Pie chart
3. Access Mostly Uused Products by 50000+ Subscribers
4. Density plot
Ans : 1
Question : Which process in text analysis can be used to reduce dimensionality?
1. Parsing
2. Digitizing
3. Access Mostly Uused Products by 50000+ Subscribers
4. Sorting
Ans : 3
Exp :
Question : What is the format of the output from the Map function of MapReduce?
1. Key-value pairs
2. Binary respresentation of keys concatenated with structured data
3. Access Mostly Uused Products by 50000+ Subscribers
4. Unique key record and separate records of all possible values
Ans : 1
Question : Which data type value is used for the observed response variable in a logistic regression model?
1. Any positive real number
2. Any integer
3. Access Mostly Uused Products by 50000+ Subscribers
4. Any real number
Ans : 3
Exp :
Question : In linear regression modeling, which action can be taken to improve the linearity of the relationship
between the dependent and independent variables?
1. Apply a transformation to a variable
2. Use a different statistical package
3. Access Mostly Uused Products by 50000+ Subscribers
4. Change the units of measurement on the independent variable
Ans : 1
Exp :
Question
What is the primary bottleneck in text classification?
1. The ability to parse unstructured text data.
2. The high dimensionality of text data.
3. Access Mostly Uused Products by 50000+ Subscribers
4. The fact that text corpora are dynamic.
Ans : 3
Exp :
Question : Your customer provided you with , unlabeled records and asked you to separate them into
three groups. What is the correct analytical method to use?

1. Logistic regression
2. Naive Bayesian classification
3. Access Mostly Uused Products by 50000+ Subscribers
4. K-means clustering
Ans : 4
Exp :
Question : How does Pig's use of a schema differ from that of a traditional RDBMS?

1. Pig's schema is optional
2. Pig's schema requires that the data is physically present when the schema is defined
3. Access Mostly Uused Products by 50000+ Subscribers
4. Pig's schema supports a single data type
Ans : 1
Exp :
Question :You are asked to create a model to predict the total number of monthly subscribers for a specific
magazine. You are provided with 1 year's worth of subscription and payment data, user
demographic data, and 10 years worth of content of the magazine (articles and pictures). Which
algorithm is the most appropriate for building a predictive model for subscribers?
1. Logistic regression
2. Decision trees
3. Access Mostly Uused Products by 50000+ Subscribers
4. Linear regression
Ans : 4
Exp :
Question : What describes a true property of Logistic Regression method?
1. It is robust with redundant variables and correlated variables.
2. It handles missing values well.
3. Access Mostly Uused Products by 50000+ Subscribers
4. It works well with variables that affect the outcome in a discontinuous way.
Ans :1
Exp :
Question : A data scientist is asked to implement an article recommendation feature for an on-line magazine.
The magazine does not want to use client tracking technologies such as cookies or reading
history. Therefore, only the style and subject matter of the current article is available for making
recommendations. All of the magazine's articles are stored in a database in a format suitable for
analytics.
Which method should the data scientist try first?
1. Association Rules
2. Naive Bayesian
3. Access Mostly Uused Products by 50000+ Subscribers
4. K Means Clustering
Ans : 4
Exp :
Question : While having a discussion with your colleague, this person mentions that they want to perform Kmeans
clustering on text file data stored in HDFS.
Which tool would you recommend to this colleague?
1. Sqoop
2. HBase
3. Access Mostly Uused Products by 50000+ Subscribers
4. Scribe
Ans : 3
Exp :
Question : What describes a true limitation of Logistic Regression method?
1. It does not handle redundant variables well.
2. It does not handle missing values well.
3. Access Mostly Uused Products by 50000+ Subscribers
4. It does not have explanatory values.
Ans : 2
Exp :
Question : You submit a MapReduce job to a Hadoop cluster and notice that although the job was
successfully submitted, it is not completing. What should you do?
1. Ensure that the JobTracker is running
2. Ensure that the TaskTracker is running.
3. Access Mostly Uused Products by 50000+ Subscribers
4. Ensure that a DataNode is running
Ans : 2
Exp :
Question : A disk drive manufacturer has a defect rate of less than .% with % confidence. A quality
assurance team samples 1000 disk drives and finds 14 defective units. Which action should the
team recommend?
1. A smaller sample size should be taken to determine if the plant is operating correctly
2. A larger sample size should be taken to determine if the plant is operating correctly
3. Access Mostly Uused Products by 50000+ Subscribers
4. There is a flaw in the quality assurance process and the sample should be repeated
Ans : 3
Exp :
Question : Your organization has a website where visitors randomly receive one of two coupons. It is also
possible that visitors to the website will not receive a coupon. You have been asked to determine if
offering a coupon to visitors to your website has any impact on their purchase decision.
Which analysis method should you use?
1. K-means clustering
2. Association rules
3. Access Mostly Uused Products by 50000+ Subscribers
4. One-way ANOVA
Ans : 4
Exp :
Question : What describes the use of UNION clause in a SQL statement?
1. Operates on queries and potentially increases the number of rows
2. Operates on queries and potentially decreases the number of rows
3. Access Mostly Uused Products by 50000+ Subscribers
4. Operates on both tables and queries and potentially increases both the number of rows and columns
Ans : 1
Exp :
Question : In the MapReduce framework, what is the purpose of the Reduce function?
1. It distributes the input to multiple nodes for processing
2. It writes the output of the Map function to storage
3. Access Mostly Uused Products by 50000+ Subscribers
4. It breaks the input into smaller components and distributes to other nodes in the cluster
Ans : 3
Exp :
Question : Which of the following is an example of quasi-structured data?
1. OLAP
2. OLTP
3. Access Mostly Uused Products by 50000+ Subscribers
4. Clickstream data
Ans : 4
Exp :
Question : Which data asset is an example of semi-structured data?
1. Database table
2. XML data file
3. Access Mostly Uused Products by 50000+ Subscribers
4. News article
Ans : 2
Exp :
Question : Your colleague, who is new to Hadoop, approaches you with a question. They want to know how
best to access their data. This colleague has previously worked extensively with SQL and
databases.
Which query interface would you recommend?
1. HBase
2. Crunch
3. Access Mostly Uused Products by 50000+ Subscribers
4. Hive
Correct Answer : Get Lastest Questions and Answer :
Explanation:
null
Related Questions
Question : You are using k-means clustering to discover groupings within a data set. You plot within-sum-ofsquares
(wss) of multiple cluster sizes. Based on the exhibit, how many clusters should you use in
your analysis?
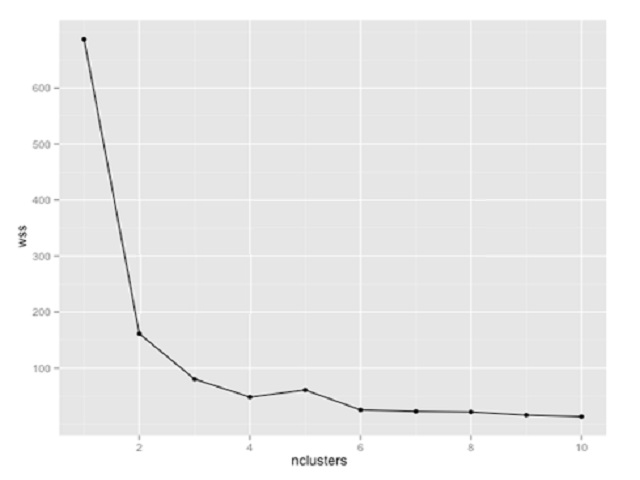
1. 2
2. 3
3. Access Mostly Uused Products by 50000+ Subscribers
4. 8
Question : Consider the training data set shown in the exhibit. What are the classification (Y = or ) and the
probability of the classification for the tupleX(0, 0, 1) using Naive Bayesian classifier?
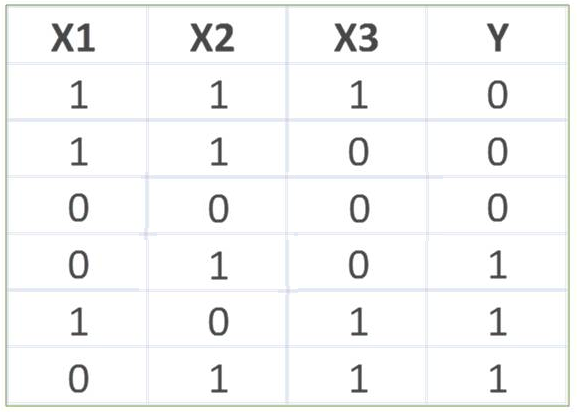
1. Classification Y = 0, Probability = 1/54
2. Classification Y = 1, Probability = 1/54
3. Access Mostly Uused Products by 50000+ Subscribers
4. Classification Y = 0, Probability = 4/54
Question : You have scored your Naive bayesian classifier model on a hold out test data for cross validation
and determined the way the samples scored and tabulated them as shown in the exhibit.
What are the the False Positive Rate (FPR) and the False Negative Rate (FNR) of the model?
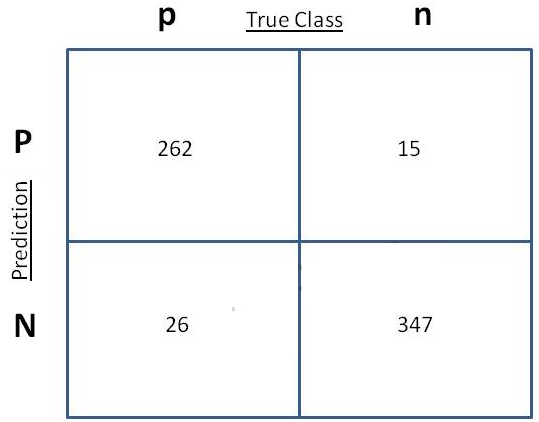
1. FPR = 262/15
FNR = 288/26
2. FPR = 26/288
FNR = 15/262
3. Access Mostly Uused Products by 50000+ Subscribers
FNR = 26/288
4. FPR = 288/26
FNR = 262/15
Question : Which data asset is an example of quasi-structured data?
1. Webserver log
2. XML data file
3. Access Mostly Uused Products by 50000+ Subscribers
4. News article
Ans : 1
Exp : Types of quasi-structured data and examples of each
totally unstructured data - google search results cover all websites, but are hard to further categorize without access the google database itself
intuitive-structure - my wordtree algorithm accepts any pasted text and yields a network map based on similarity of langauge within the text, as well as proximity of words to each other within the text. But it is not "tagged" the way youtube and flickr track content in images
emergent structure - algorithms to extract the main idea of groups of stories
pseudo-structuring - looking at content and assigning structure to all possible variations of a single document type, such as I did with the auditing tool.
guess, apply a rule, and refine - in this mode the algorithm tries an approach and refines it iteratively based on user feedback. IF the feedback is automated in the form of a score on the result, this approach becomes evolutionary programming.
(I am still figuring out how to describe this - so some of these above examples may be the same thing.)
These strategies for structuring Big Data have come about as a consequence of two trends. First - 100 times more content is added online each year than the sum of all books ever written in history. Second - most of this content is structured by institutions that for various reasons don't want to release the fully annotated version of the information. So pragmatic programmers like me build "wrappers" to restructure the parts that are available. Eventually there will be a universal wrapper for all content about financial records, and another one for all organization reports. These data sets will organize content into clusters that are similar enough for us to study patterns on a global scale. That's when "big data" begins to get interesting. Today, we're in the early stages of deconstructing the structure so that we can reconstruct larger data sets from the individual parts that each have unique yet "incompatible" structures. It is like taking apart all the cars in a junk yard so we can categorize all the parts and deliver them to customers that want to build fresh cars. You see cars go in and cars go out, but a lot happens in between.
Last year, if someone had asked you to track all the work you do on your computer, you would have probably filled out a survey (like the "time tracking" reports I fill out monthly at work). In the future your computer will fill them out for you and in greater detail, and these data will be "mashable" with other reporting systems. This will not happen because two systems are built to work together, but instead because someone build a third system that allows two systems to share information. Eventually we will build "genetic algorithms" that will write programs that can re-organize data into usable structures regardless of how the original data was structured. This is going to happen in the next ten years and we will ask ourselves why we didn't do it sooner.
Question : What would be considered "Big Data"?
1. An OLAP Cube containing customer demographic information about 100, 000, 000 customers
2. Daily Log files from a web server that receives 100, 000 hits per minute
3. Access Mostly Uused Products by 50000+ Subscribers
4. Spreadsheets containing monthly sales data for a Global 100 corporation
Ans : 2
Exp :
Question : A data scientist plans to classify the sentiment polarity of , product reviews collected from
the Internet. What is the most appropriate model to use? Suppose labeled training data is
available.
1. Naive Bayesian classifier
2. Linear regression
3. Access Mostly Uused Products by 50000+ Subscribers
4. K-means clustering
Ans : 1
Exp :
Question : In which lifecycle stage are test and training data sets created?
1. Model building
2. Model planning
3. Access Mostly Uused Products by 50000+ Subscribers
4. Data preparation
Ans : 1
Exp :
Question : Your company has different sales teams. Each team's sales manager has developed incentive
offers to increase the size of each sales transaction. Any sales manager whose incentive program
can be shown to increase the size of the average sales transaction will receive a bonus.
Data are available for the number and average sale amount for transactions offering one of the
incentives as well as transactions offering no incentive.
The VP of Sales has asked you to determine analytically if any of the incentive programs has
resulted in a demonstrable increase in the average sale amount. Which analytical technique would
be appropriate in this situation?
1. One-way ANOVA
2. Multi-way ANOVA
3. Access Mostly Uused Products by 50000+ Subscribers
4. Wilcoxson Rank Sum Test
Ans : 1
Exp :
Question : In data visualization, what is used to focus the audience on a key part of a chart?
1. Emphasis colors
2. Detailed text
3. Access Mostly Uused Products by 50000+ Subscribers
4. A data table
Ans : 1
Exp :
Question : Under which circumstance do you need to implement N-fold cross-validation after creating a
regression model?
1. There is not enough data to create a test set.
2. The data is unformatted.
3. Access Mostly Uused Products by 50000+ Subscribers
4. There are categorical variables in the model.
Ans : 1
Exp :
Question : What is an appropriate data visualization to use in a presentation for an analyst audience?
1. Pie chart
2. Area chart
3. Access Mostly Uused Products by 50000+ Subscribers
4. ROC curve
Ans : 4
Exp :
Question : Which type of numeric value does a logistic regression model estimate?
1. Probability
2. A p-value
3. Access Mostly Uused Products by 50000+ Subscribers
4. Any real number
Ans : 1
Exp :
Question : Your colleague, who is new to Hadoop, approaches you with a question. They want to know how
best to access their data. This colleague has a strong background in data flow languages and
programming. Which query interface would you recommend?
1. Pig
2. Hive
3. Access Mostly Uused Products by 50000+ Subscribers
4. HBase
Question : The web analytics team uses Hadoop to process access logs. They now want to correlate this
data with structured user data residing in their massively parallel database. Which tool should they
use to export the structured data from Hadoop?
1. Sqoop
2. Pig
3. Access Mostly Uused Products by 50000+ Subscribers
4. Scribe
Ans : 1
Exp :
Question : When would you prefer a Naive Bayes model to a logistic regression model for classification?
1. When you are using several categorical input variables with over 1000 possible values each.
2. When you need to estimate the probability of an outcome, not just which class it is in.
3. Access Mostly Uused Products by 50000+ Subscribers
4. When some of the input variables might be correlated.
Ans : 1
Exp :
Question : You have fit a decision tree classifier using input variables. The resulting tree used of the
variables, and is 5 levels deep. Some of the nodes contain only 3 data points. The AUC of the
model is 0.85. What is your evaluation of this model?
1. The tree is probably overfit. Try fitting shallower trees and using an ensemble method.
2. The AUC is high, and the small nodes are all very pure. This is an accurate model.
3. Access Mostly Uused Products by 50000+ Subscribers
accurate model
4. The AUC is high, so the overall model is accurate. It is not well-calibrated, because the small
nodes will give poor estimates of probability.
Ans : 1
Exp :
Question : If your intention is to show trends over time, which chart type is the most appropriate way to depict
the data?
1. Line chart
2. Bar chart
3. Access Mostly Uused Products by 50000+ Subscribers
4. Histogram
Ans : 1
Exp :
Question : In which phase of the data analytics lifecycle do Data Scientists spend the most time in a project?
1. Discovery
2. Data Preparation
3. Access Mostly Uused Products by 50000+ Subscribers
4. Communicate Results
Ans : 2
Exp :
Question : You are testing two new weight-gain formulas for puppies. The test gives the results:
Control group: 1% weight gain
Formula A. 3% weight gain
Formula B. 4% weight gain
A one-way ANOVA returns a p-value = 0.027
What can you conclude?
1. Either Formula A or Formula B is effective at promoting weight gain.
2. Formula B is more effective at promoting weight gain than Formula A.
3. Access Mostly Uused Products by 50000+ Subscribers
4. Formula A and Formula B are about equally effective at promoting weight gain.
Ans : 1
Exp :
Question : Data visualization is used in the final presentation of an analytics project. For what else is this
technique commonly used?
1. Data exploration
2. Descriptive statistics
3. Access Mostly Uused Products by 50000+ Subscribers
4. Model selection
Ans : 1
Exp :
Question : Which functionality do regular expressions provide?
1. text pattern matching
2. underflow prevention
3. Access Mostly Uused Products by 50000+ Subscribers
4. decreased processing complexity
Ans : 1
Exp :
Question : The average purchase size from your online sales site is $, . The customer experience team
believes a certain adjustment of the website will increase sales. A pilot study on a few hundred
customers showed an increase in average purchase size of $1.47, with a significance level of
p=0.1.
The team runs a larger study, of a few thousand customers. The second study shows an
increased average purchase size of $0.74, with a significance level of 0.03. What is your
assessment of this study?
1. The change in purchase size is not practically important, and the good p-value of the second
study is probably a result of the large study size.
2. The change in purchase size is small, but may aggregate up to a large increase in profits over
the entire customer base.
3. Access Mostly Uused Products by 50000+ Subscribers
should run another, larger study.
4. The p-value of the second study shows a statistically significant change in purchase size. The
new website is an improvement.
Ans : 1
Exp :
Question : Which word or phrase completes the statement? Business Intelligence is to monitoring trends as
Data Science is to ________ trends.
1. Predicting
2. Discarding
3. Access Mostly Uused Products by 50000+ Subscribers
4. Optimizing
Ans : 1
Exp :
Question : Consider a scale that has five () values that range from "not important" to "very important". Which
data classification best describes this data?
1. Ordinal
2. Nominal
3. Access Mostly Uused Products by 50000+ Subscribers
4. Ratio
Ans : 1
Exp :
Question : Which analytical method is considered unsupervised?
1. K-means clustering
2. Naive Bayesian classifier
3. Access Mostly Uused Products by 50000+ Subscribers
4. Linear regression
Ans : 1
Exp :
Question : You have used k-means clustering to classify behavior of , customers for a retail store.
You decide to use household income, age, gender and yearly purchase amount as measures. You
have chosen to use 8 clusters and notice that 2 clusters only have 3 customers assigned. What
should you do?
1. Decrease the number of clusters
2. Increase the number of clusters
3. Access Mostly Uused Products by 50000+ Subscribers
4. Identify additional measures to add to the analysis
Ans : 1
Exp :
Question For which class of problem is MapReduce most suitable?
1. Embarrassingly parallel
2. Minimal result data
3. Access Mostly Uused Products by 50000+ Subscribers
4. Non-overlapping queries
Ans : 1
Exp :
Question You are building a logistic regression model to predict whether a tax filer will be audited within the
next two years. Your training set population is 1000 filers. The audit rate in your training data is
4.2%. What is the sum of the probabilities that the model assigns to all the filers in your training set
that have been audited?
1. 42
2. 4.2
3. Access Mostly Uused Products by 50000+ Subscribers
4. 0.042
Ans : 1
Exp :
Question Refer to exhibit.
You are asked to write a report on how specific variables impact your client's sales using a data
set provided to you by the client. The data includes 15 variables that the client views as directly
related to sales, and you are restricted to these variables only.
After a preliminary analysis of the data, the following findings were made:
1. Multicollinearity is not an issue among the variables
2. Only three variables-A, B, and C-have significant correlation with sales
You build a linear regression model on the dependent variable of sales with the independent
variables of A, B, and C. The results of the regression are seen in the exhibit.
You cannot request additional datA. what is a way that you could try to increase the R2 of the
model without artificially inflating it?
1. Create clusters based on the data and use them as model inputs
2. Force all 15 variables into the model as independent variables
3. Access Mostly Uused Products by 50000+ Subscribers
4. Break variables A, B, and C into their own univariate models
Ans : 1
Exp :
Question You are given , , user profile pages of an online dating site in XML files, and they are
stored in HDFS. You are assigned to divide the users into groups based on the content of their
profiles. You have been instructed to try K-means clustering on this data. How should you
proceed?
1. Run MapReduce to transform the data, and find relevant key value pairs.
2. Divide the data into sets of 1, 000 user profiles, and run K-means clustering in RHadoop iteratively.
3. Access Mostly Uused Products by 50000+ Subscribers
4. Partition the data by XML file size, and run K-means clustering in each partition.
Ans : 1
Exp :
Question : A call center for a large electronics company handles an average of , support calls a day.
The head of the call center would like to optimize the staffing of the call center during the rollout of
a new product due to recent customer complaints of long wait times. You have been asked to
create a model to optimize call center costs and customer wait times.
The goals for this project include:
1. Relative to the release of a product, how does the call volume change over time?
2. How to best optimize staffing based on the call volume for the newly released product, relative
to old products.
3. Access Mostly Uused Products by 50000+ Subscribers
4. Determine the frequency of calls by both product type and customer language.
Which goals are suitable to be completed with MapReduce?
1. 2,4
2. 1,3
3. Access Mostly Uused Products by 50000+ Subscribers
4. 2,3,4
Ans : 1
Exp :
Question : You are studying the behavior of a population, and you are provided with multidimensional data at
the individual level. You have identified four specific individuals who are valuable to your study,
and would like to find all users who are most similar to each individual. Which algorithm is the
most appropriate for this study?
1. K-means clustering
2. Linear regression
3. Access Mostly Uused Products by 50000+ Subscribers
4. Decision trees
Ans : 1
Exp :
Question A disk drive manufacturer has a defect rate of less than .% with % confidence. A quality
assurance team samples 1000 disk drives and finds 14 defective units. Which action should the
team recommend?
1. The manufacturing process should be inspected for problems.
2. A larger sample size should be taken to determine if the plant is functioning properly
3. Access Mostly Uused Products by 50000+ Subscribers
4. The manufacturing process is functioning properly and no further action is required.
Ans : 1
Exp :
Question A data scientist wants to predict the probability of death from heart disease based on three risk
factors: age, gender, and blood cholesterol level.
What is the most appropriate method for this project?
1. Linear regression
2. K-means clustering
3. Access Mostly Uused Products by 50000+ Subscribers
4. Logistic regression
Ans : 4
Exp :
Question : What are the characteristics of Big Data?
1. Data volume, business importance, and data structure variety.
2. Data volume, processing complexity, and data structure variety.
3. Access Mostly Uused Products by 50000+ Subscribers
4. Data volume, processing complexity, and business importance.
Ans : 2
Exp :
Question You are analyzing data in order to build a classifier model. You discover non-linear data and
discontinuities that will affect the model. Which analytical method would you recommend?
1. Logistic Regression
2. Decision Trees
3. Access Mostly Uused Products by 50000+ Subscribers
4. Linear Regression
Ans : 2
Exp :
Question : What is an appropriate data visualization to use in a presentation for a project sponsor?
1. Bar chart
2. Pie chart
3. Access Mostly Uused Products by 50000+ Subscribers
4. Density plot
Ans : 1
Question : Which process in text analysis can be used to reduce dimensionality?
1. Parsing
2. Digitizing
3. Access Mostly Uused Products by 50000+ Subscribers
4. Sorting
Ans : 3
Exp :
Question : What is the format of the output from the Map function of MapReduce?
1. Key-value pairs
2. Binary respresentation of keys concatenated with structured data
3. Access Mostly Uused Products by 50000+ Subscribers
4. Unique key record and separate records of all possible values
Ans : 1
Question : Which data type value is used for the observed response variable in a logistic regression model?
1. Any positive real number
2. Any integer
3. Access Mostly Uused Products by 50000+ Subscribers
4. Any real number
Ans : 3
Exp :
Question : In linear regression modeling, which action can be taken to improve the linearity of the relationship
between the dependent and independent variables?
1. Apply a transformation to a variable
2. Use a different statistical package
3. Access Mostly Uused Products by 50000+ Subscribers
4. Change the units of measurement on the independent variable
Ans : 1
Exp :
Question
What is the primary bottleneck in text classification?
1. The ability to parse unstructured text data.
2. The high dimensionality of text data.
3. Access Mostly Uused Products by 50000+ Subscribers
4. The fact that text corpora are dynamic.
Ans : 3
Exp :
Question : Your customer provided you with , unlabeled records and asked you to separate them into
three groups. What is the correct analytical method to use?
1. Logistic regression
2. Naive Bayesian classification
3. Access Mostly Uused Products by 50000+ Subscribers
4. K-means clustering
Ans : 4
Exp :
Question : How does Pig's use of a schema differ from that of a traditional RDBMS?
1. Pig's schema is optional
2. Pig's schema requires that the data is physically present when the schema is defined
3. Access Mostly Uused Products by 50000+ Subscribers
4. Pig's schema supports a single data type
Ans : 1
Exp :
Question :You are asked to create a model to predict the total number of monthly subscribers for a specific
magazine. You are provided with 1 year's worth of subscription and payment data, user
demographic data, and 10 years worth of content of the magazine (articles and pictures). Which
algorithm is the most appropriate for building a predictive model for subscribers?
1. Logistic regression
2. Decision trees
3. Access Mostly Uused Products by 50000+ Subscribers
4. Linear regression
Ans : 4
Exp :
Question : What describes a true property of Logistic Regression method?
1. It is robust with redundant variables and correlated variables.
2. It handles missing values well.
3. Access Mostly Uused Products by 50000+ Subscribers
4. It works well with variables that affect the outcome in a discontinuous way.
Ans :1
Exp :
Question : A data scientist is asked to implement an article recommendation feature for an on-line magazine.
The magazine does not want to use client tracking technologies such as cookies or reading
history. Therefore, only the style and subject matter of the current article is available for making
recommendations. All of the magazine's articles are stored in a database in a format suitable for
analytics.
Which method should the data scientist try first?
1. Association Rules
2. Naive Bayesian
3. Access Mostly Uused Products by 50000+ Subscribers
4. K Means Clustering
Ans : 4
Exp :
Question : While having a discussion with your colleague, this person mentions that they want to perform Kmeans
clustering on text file data stored in HDFS.
Which tool would you recommend to this colleague?
1. Sqoop
2. HBase
3. Access Mostly Uused Products by 50000+ Subscribers
4. Scribe
Ans : 3
Exp :
Question : What describes a true limitation of Logistic Regression method?
1. It does not handle redundant variables well.
2. It does not handle missing values well.
3. Access Mostly Uused Products by 50000+ Subscribers
4. It does not have explanatory values.
Ans : 2
Exp :
Question : You submit a MapReduce job to a Hadoop cluster and notice that although the job was
successfully submitted, it is not completing. What should you do?
1. Ensure that the JobTracker is running
2. Ensure that the TaskTracker is running.
3. Access Mostly Uused Products by 50000+ Subscribers
4. Ensure that a DataNode is running
Ans : 2
Exp :
Question : A disk drive manufacturer has a defect rate of less than .% with % confidence. A quality
assurance team samples 1000 disk drives and finds 14 defective units. Which action should the
team recommend?
1. A smaller sample size should be taken to determine if the plant is operating correctly
2. A larger sample size should be taken to determine if the plant is operating correctly
3. Access Mostly Uused Products by 50000+ Subscribers
4. There is a flaw in the quality assurance process and the sample should be repeated
Ans : 3
Exp :
Question : Your organization has a website where visitors randomly receive one of two coupons. It is also
possible that visitors to the website will not receive a coupon. You have been asked to determine if
offering a coupon to visitors to your website has any impact on their purchase decision.
Which analysis method should you use?
1. K-means clustering
2. Association rules
3. Access Mostly Uused Products by 50000+ Subscribers
4. One-way ANOVA
Ans : 4
Exp :
Question : What describes the use of UNION clause in a SQL statement?
1. Operates on queries and potentially increases the number of rows
2. Operates on queries and potentially decreases the number of rows
3. Access Mostly Uused Products by 50000+ Subscribers
4. Operates on both tables and queries and potentially increases both the number of rows and columns
Ans : 1
Exp :
Question : In the MapReduce framework, what is the purpose of the Reduce function?
1. It distributes the input to multiple nodes for processing
2. It writes the output of the Map function to storage
3. Access Mostly Uused Products by 50000+ Subscribers
4. It breaks the input into smaller components and distributes to other nodes in the cluster
Ans : 3
Exp :
Question : Which of the following is an example of quasi-structured data?
1. OLAP
2. OLTP
3. Access Mostly Uused Products by 50000+ Subscribers
4. Clickstream data
Ans : 4
Exp :
Question : Which data asset is an example of semi-structured data?
1. Database table
2. XML data file
3. Access Mostly Uused Products by 50000+ Subscribers
4. News article
Ans : 2
Exp :
Question : Your colleague, who is new to Hadoop, approaches you with a question. They want to know how
best to access their data. This colleague has previously worked extensively with SQL and
databases.
Which query interface would you recommend?
1. HBase
2. Crunch
3. Access Mostly Uused Products by 50000+ Subscribers
4. Hive
null