Cloudera Databricks Data Science Certification Questions and Answers (Dumps and Practice Questions)
Question : You are using k-means clustering to discover groupings within a data set. You plot within-sum-ofsquares
(wss) of multiple cluster sizes. Based on the exhibit, how many clusters should you use in
your analysis?
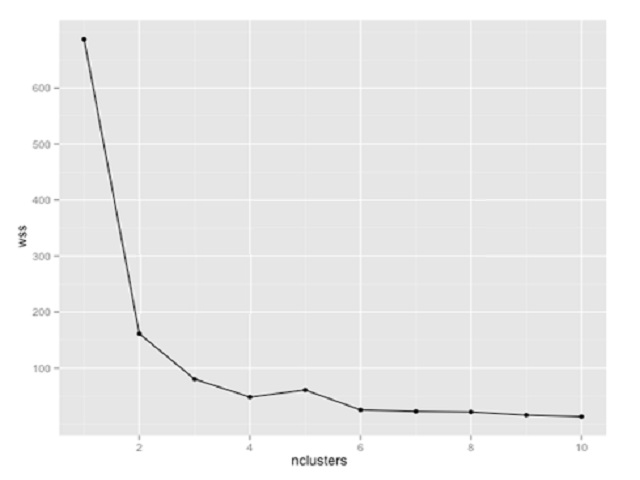
1. 2
2. 3
3. Access Mostly Uused Products by 50000+ Subscribers
4. 8
Correct Answer : Get Lastest Questions and Answer :
Explanation:
Question : Consider the training data set shown in the exhibit. What are the classification (Y = or ) and the
probability of the classification for the tupleX(0, 0, 1) using Naive Bayesian classifier?
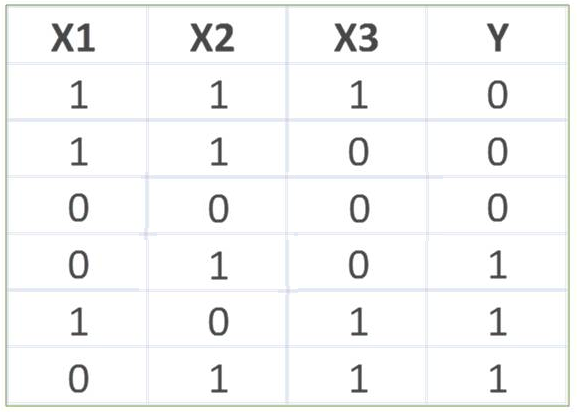
1. Classification Y = 0, Probability = 1/54
2. Classification Y = 1, Probability = 1/54
3. Access Mostly Uused Products by 50000+ Subscribers
4. Classification Y = 0, Probability = 4/54
Correct Answer : Get Lastest Questions and Answer :
Explanation:
Question : You have scored your Naive bayesian classifier model on a hold out test data for cross validation
and determined the way the samples scored and tabulated them as shown in the exhibit.
What are the the False Positive Rate (FPR) and the False Negative Rate (FNR) of the model?
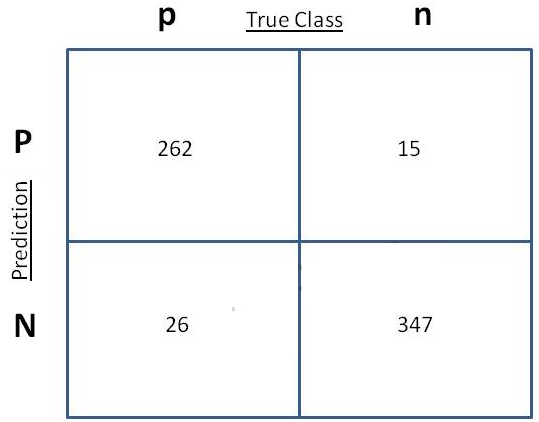
1. FPR = 262/15
FNR = 288/26
2. FPR = 26/288
FNR = 15/262
3. Access Mostly Uused Products by 50000+ Subscribers
FNR = 26/288
4. FPR = 288/26
FNR = 262/15
Correct Answer : Get Lastest Questions and Answer :
Please also read the revision notes provided by www.HadoopExam.com before appearing the real exam. And understand the each underline concepts and
Do not memorize the just answers.
HadoopExam Learning Resourcs is
Wishing you all the best for your real exam.

1. Soon we
2. want your
3. Access Mostly Uused Products by 50000+ Subscribers
4. Testimonial Page
Related Questions
Question :
You have following data in a hive table
ID:INT,COLOR:TEXT,WIDTH:INT
1,green,190
2,blue,300
3,yellow,220
4,blue,199
5,green,199
6,yellow,299
7,green,799
Select the correct MapReduce program which can produce
the output similar to below Hive Query
(Assuming single reducer is configured).
Select color,max(width) from table group by color;

1. 1
2. 2
3. Access Mostly Uused Products by 50000+ Subscribers
4. 4
Question : All HadoopExam website subscribers information is stored in the MySQL database,
Which tool is best suited to import a portion of a subscribers information every day as files into HDFS,
and generate Java classes to interact with that imported data?
1. Hive
2. Pig
3. Access Mostly Uused Products by 50000+ Subscribers
4. Flume
Question As part of HadoopExam consultency team, you have been given a requirement by a Hotel to create
a GUI apllication, so all the hotel's sales or booking you will add and edit the customer information, and you dont want to spend the
money on enterprize RDBMS, hence decided simple file as a storage and considered the csv file. So HDFS is the better choice for
storing such information in the file.
1. No, because HDFS is optimized for read-once, streaming access for relatively large files.
2. No, because HDFS is optimized for write-once, streaming access for relatively large files.
3. Access Mostly Uused Products by 50000+ Subscribers
4. Yes, because HDFS is optimized for write-once, streaming access for relatively large files.
Question : All HadoopExam website subscribers information is stored in the MySQL database,
Which tool is best suited to import a portion of a subscribers information every day as files into HDFS,
and generate Java classes to interact with that imported data?
1. Hive
2. Pig
3. Access Mostly Uused Products by 50000+ Subscribers
4. Flume
Question : You have run a linear regression model against your data, and have plotted true outcome versus
predicted outcome. The R-squared of your model is 0.75. What is your assessment of the model?
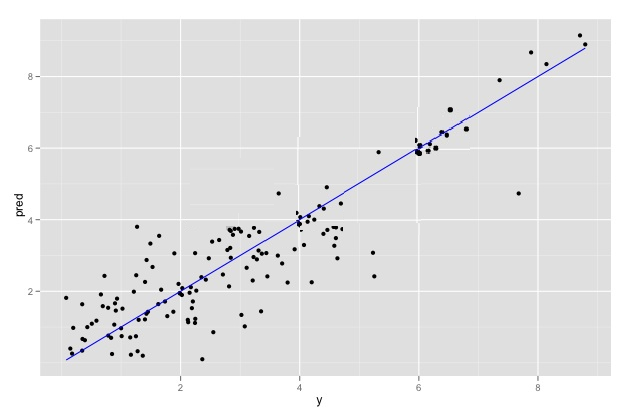
1. The R-squared may be biased upwards by the extreme-valued outcomes. Remove them and
refit to get a better idea of the model's quality over typical data.
2. The R-squared is good. The model should perform well.
3. Access Mostly Uused Products by 50000+ Subscribers
see if the R-squared improves over typical data.
4. The observations seem to come from two different populations, but this model fits them both
equally well.
Question : You are using K-means clustering to classify customer behavior for a large retailer. You need to
determine the optimum number of customer groups. You plot the within-sum-of-squares (wss)
data as shown in the exhibit. How many customer groups should you specify?
1. 2
2. 3
3. Access Mostly Uused Products by 50000+ Subscribers
4. 8