IBM Certified Data Architect - Big Data Certification Questions and Answers (Dumps and Practice Questions)
Question : You have been given a below scenario. You have in total TB data. Your data scientists have written queries to access this data.
However,
- Out of 1000 queries 850 queries, access 25 TB data
- Out of 1000 queries only 100 queries will touch 25 TB data out of remaining 75 TB data
- Out of 1000 queries only 50 queries will touch 20TB data out of remaining 50 TB data
Hence, you can say 850 queries are frequently accessing 25TB data.
Which of the following would provide the best value (business benefit) and lowest TCO?

1. Place the entire set of data in a data warehouse with proper partitioning and indexing.
2. Place the entire set of data in a hadoop environment " using commodity HW.
3. Access Mostly Uused Products by 50000+ Subscribers
4. Place the top 25TB of data (used by 85TB of the query) in a data warehouse, and the rest in a hadoop environment.
Correct Answer : Get Lastest Questions and Answer :
Explanation: Because we are frequently accessing 25TB data, hence that should be kept in Data warehouse, which will have faster response time.
Relational databases and data warehouses are often a good fit for well-understood and frequently accessed queries and reports on high-value data. Increasingly, though, Hadoop is
taking on many of these workloads, particularly for queries that need to operate on volumes of data that are not economically or technically practical to process with traditional
systems
Question : You have lot of business critical data. Which should be available all the time for applying analytics on it. So you must have lower RPO (recovery point objective).
Which of the following will help you to do this easily.
1. Clustering
2. Database Shadowing
3. Access Mostly Uused Products by 50000+ Subscribers
4. Tape Backup
Correct Answer : Get Lastest Questions and Answer :
Explanation: The recovery point objective (RPO) is the age of files that must be recovered from backup storage for normal operations to resume if a computer, system,
or network goes down as a result of a hardware, program, or communications failure. The RPO is expressed backward in time (that is, into the past) from the instant at which the
failure occurs, and can be specified in seconds, minutes, hours, or days. It an important consideration in disaster recovery planning (DRP).
Remote journal management helps to efficiently replicate journal entries to one or more systems. You can use remote journal management with application programs to maintain a data
replica. A data replica is a copy of the original data that resides on another system or independent disk pool. The original data resides on a primary system. Applications make
changes to the original data during normal operations.
However, clustering will help to get data instantly, by having multiple copies of data across nodes like HDFS clustering.
Question : You need to provision a Hadoop cluster to perform data analysis on customer sales
data to predict which products are more popular. Which of the following solutions
will let you set up your cluster with the most stability in the platform?
1. Purchase specific products from multiple Independent Software Vendors (ISV)
for your requirements in order to take advantage of vendor-specific features
2. Develop your own platform of software components to allow for maximum
customization
3. Access Mostly Uused Products by 50000+ Subscribers
4. Leverage the Open Data Platform (ODP) core to provide a stable base against
which Big Data solutions providers can qualify solutions
Correct Answer : Get Lastest Questions and Answer :
Explanation: The Open Data Platform initiative brings industry leaders together to accelerate the adoption of ApacheTM Hadoop and related Big Data ecosystem
technologies and make it easier to rapidly develop applications. ODPi members represent a diverse group of Big Data solution providers and end users.
Related Questions
Question : IBM Cloudant is a managed NoSQL database service that moves application data closer to all the places it needs to be
1. True
2. False
Question : Which of the following is IBM NoSQL Fully managed DBaaS (database-as-a-service) tool?
1. Cloudant
2. HBase
3. Access Mostly Uused Products by 50000+ Subscribers
4. DB2
Question : Which of the following is true about Cloudant?
1. IBM Cloudant is a Fully managed DBaaS
2. Cloudant indexing is flexible and powerful, and includes real-time MapReduce, Apache Lucene-based full-text search, advanced Geospatial, and declaritive
Cloudant Query.
3. Access Mostly Uused Products by 50000+ Subscribers
4. 1 and 2
5. 1,2 and 3
Question : What occurs when you run a Hadoop job, specifying an output directory job output which already exists in HDFS?

1. An error will occur immediately, because the output directory must not already exist when a MapReduce job commences.
2. An error will occur after the Mappers have completed but before any Reducers begin to run, because the output path must not exist when the Reducers commence.
3. Access Mostly Uused Products by 50000+ Subscribers
4. The job will run successfully. Output from the Reducers will overwrite the contents of the existing directory.
Ans : 1
Exp : When a job is run, one of the first things done on the client is a check to ensure that the output directory does not already exist. If it does, the client will immediately
terminate. The job will not be submitted to the cluster; the check takes place on the client.
Question : Select the correct statement for OOzie workflow
1. OOzie workflow runs on a server which is typically outside of Hadoop Cluster
2. OOzie workflow definition are submitted via HTTP.
3. Access Mostly Uused Products by 50000+ Subscribers
4. All 1,2 and 3 are correct
5. Only 1 and 3 are correct
Ans : 4
Exp : Check the URL http://oozie.apache.org/docs/3.1.3-incubating/WorkflowFunctionalSpec.html
Question : What is the result when you execute: hadoop jar SampleJar.jar MyClass on a client machine?

1. SampleJar.jar is placed in a temporary directory in HDFS
2. An error will occur, because you have not provided input and output directories
3. Access Mostly Uused Products by 50000+ Subscribers
4. SampleJar.jar is sent directly to the JobTracker
Ans : 1
Exp : When a job is submitted to the cluster, it is placed in a temporary directory in HDFS and the JobTracker is notified of that location. The configuration for the job is
serialized to an XML file, which is also placed in a directory in HDFS. Some jobs require you to specify the input and output directories on the command line, but this is not a
Hadoop requirement.
Question : During a MapReduce v(MRv) job submission, there are a number of steps between the ResourceManager
receiving the job submission and the map tasks running on different nodes.
1. Order the following steps according to the flow of job submission in a YARN cluster:
2. The ResourceManager application manager asks a NodeManager to launch the ApplicationMaster
3. Access Mostly Uused Products by 50000+ Subscribers
4. The ApplicationMaster sends a request to the assigned NodeManagers to run the map tasks
5. The ResourceManager scheduler allocates a container for the ApplicationMaster
6. The ApplicationMaster determines the number of map tasks based on the input splits
7. The ResourceManager scheduler makes a decision where to run the map tasks based on the memory requirements and data locality

1. 3,4,6,5,1,2
2. 2,3,4,5,6,1
3. Access Mostly Uused Products by 50000+ Subscribers
4. 3,4,6,5,1,2
5. 6,5,3,4,1,2
Ans : 2
Exp : Link : http://hadoop.apache.org/docs/r2.3.0/hadoop-yarn/hadoop-yarn-site/YARN.html
MapReduce has undergone a complete overhaul in hadoop-0.23 and we now have, what we call, MapReduce 2.0 (MRv2) or YARN.
The fundamental idea of MRv2 is to split up the two major functionalities of the JobTracker, resource management and job scheduling/monitoring, into separate daemons. The idea is
to have a global ResourceManager (RM) and per-application ApplicationMaster (AM). An application is either a single job in the classical sense of Map-Reduce jobs or a DAG of jobs.
The ResourceManager and per-node slave, the NodeManager (NM), form the data-computation framework. The ResourceManager is the ultimate authority that arbitrates resources among all
the applications in the system.
The per-application ApplicationMaster is, in effect, a framework specific library and is tasked with negotiating resources from the ResourceManager and working with the
NodeManager(s) to execute and monitor the tasks.
The ResourceManager has two main components: Scheduler and ApplicationsManager.
The Scheduler is responsible for allocating resources to the various running applications subject to familiar constraints of capacities, queues etc. The Scheduler is pure scheduler
in the sense that it performs no monitoring or tracking of status for the application. Also, it offers no guarantees about restarting failed tasks either due to application failure
or hardware failures. The Scheduler performs its scheduling function based the resource requirements of the applications; it does so based on the abstract notion of a resource
Container which incorporates elements such as memory, cpu, disk, network etc. In the first version, only memory is supported.
The Scheduler has a pluggable policy plug-in, which is responsible for partitioning the cluster resources among the various queues, applications etc. The current Map-Reduce
schedulers such as the CapacityScheduler and the FairScheduler would be some examples of the plug-in.
The CapacityScheduler supports hierarchical queues to allow for more predictable sharing of cluster resources
The ApplicationsManager is responsible for accepting job-submissions, negotiating the first container for executing the application specific ApplicationMaster and provides the
service for restarting the ApplicationMaster container on failure.
The NodeManager is the per-machine framework agent who is responsible for containers, monitoring their resource usage (cpu, memory, disk, network) and reporting the same to the
ResourceManager/Scheduler.
The per-application ApplicationMaster has the responsibility of negotiating appropriate resource containers from the Scheduler, tracking their status and monitoring for progress.
MRV2 maintains API compatibility with previous stable release (hadoop-0.20.205). This means that all Map-Reduce jobs should still run unchanged on top of MRv2 with just a recompile.
Question : You decide to create a cluster which runs HDFS in High Availability mode with automatic failover, using Quorum-based Storage.
Which service keeps track of which NameNode is active at any given moment?
1. YARN ResourceManager
2. Secondary NameNode
3. Access Mostly Uused Products by 50000+ Subscribers
4. ZooKeeper
5. Individual JournalNode daemons
Ans : 4
Exp : When the first NameNode is started, it connects to ZooKeeper and registers itself as the Active NameNode. The next NameNode then sees that information and sets itself up in
Standby mode (in fact, the ZooKeeper Failover Controller is the software responsible for the actual communication with ZooKeeper). Clients never connect to ZooKeeper to discover
anything about the NameNodes. In an HDFS HA scenario, ZooKeeper is not used to keep track of filesystem changes. That is the job of the Quorum Journal Manager daemons.
Question : Which two daemons typically run on each slave node in a Hadoop cluster running MapReduce v (MRv) on YARN?
1. TaskTracker
2. Secondary NameNode
3. NodeManager
4. DataNode
5. ZooKeeper
6. JobTracker
7. NameNode
8. JournalNode
1. 1,2
2. 2,3
3. Access Mostly Uused Products by 50000+ Subscribers
4. 5,6
4. 7,8
Question : What happens under YARN if a Mapper on one node hangs while running a MapReduce job?
1. After a period of time, the ResourceManager will mark the map task attempt as failed and ask the NodeManager to terminate the container for the Map task
2. After a period of time, the NodeManager will mark the map task attempt as failed and ask the ApplicationMaster to terminate the container for the Map task
3. Access Mostly Uused Products by 50000+ Subscribers
4. After a period of time, the ApplicationMaster will mark the map task attempt as failed and ask the NodeManager to terminate the container for the Map task
Question
What happens when you run the below job twice , having each input directory as one of the data file called data.csv.
with following command. Assuming there were no output directory exist
hadoop job HadoopExam.jar HadoopExam inputdata_1 output
hadoop job HadoopExam.jar HadoopExam inputdata_2 output
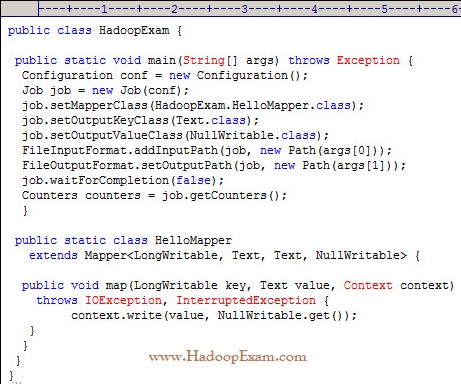
1. Both the job will write the output to output directory and output will be appended
2. Both the job will fail, saying output directory does not exist.
3. Access Mostly Uused Products by 50000+ Subscribers
4. Both the job will successfully completes and second job will overwrite the output of first.
Ans : 3
Exp : First job will successfully run and second one will fail, because, if (output directory already exist then it will not run
and throws exception, complaining output directory already exist.
Question : Which of the following model can help you to visually represent that how an organization delivers value to its customers or beneficiaries ?
1. Business Model
2. Operational Model
3. Access Mostly Uused Products by 50000+ Subscribers
4. Logical Model
5. Physical Model