AWS Certified Solutions Architect - Professional Questions and Answers (Dumps and Practice Questions)
Question : Your firm has uploaded a large amount of aerial image data to S. In the past, in your on premises environment, you used a dedicated group of servers to often process
this data and used Rabbit MQ - An open source messaging system to get job information to the servers. Once processed the data would go to tape and be shipped offsite. Your manager
told you to stay with the current design, and leverage AWS archival storage and messaging services to minimize cost. Which is correct?

1. Use SQS for passing job messages use Cloud Watch alarms to terminate EC2 worker instances when they become idle. Once data is processed, change the storage class of
the S3 objects to Reduced Redundancy Storage.
2. Setup Auto-Scaled workers triggered by queue depth that use spot instances to process messages in SQS Once data is processed
3. Access Mostly Uused Products by 50000+ Subscribers
messages in SQS. Once data is processed, change the storage class of the S3 objects to Glacier.
4. Use SNS to pass job messages use Cloud Watch alarms to terminate spot worker instances when they become idle. Once data is processed, change the storage class of the
S3 object to Glacier.
Correct Answer : 3
Exp: We need storage archival, and Glacier is best fit. Hence option 2 is out. And best Queuing service from AWS is SQS, hence option 4 is out.
Q: What is RRS?
Reduced Redundancy Storage (RRS) is a new storage option within Amazon S3 that enables customers to reduce their costs by storing non-critical, reproducible data at lower levels of
redundancy than Amazon S3's standard storage. RRS provides a lower cost, less durable, highly available storage option that is designed to sustain the loss of data in a single
facility.
Q: Why would I choose to use RRS?
RRS is ideal for non-critical or reproducible data. For example, RRS is a cost-effective solution for sharing media content that is durably stored elsewhere. RRS also makes sense if
you are storing thumbnails and other resized images that can be easily reproduced from an original image.
Q: What is the durability of Amazon S3 when using RRS?
RRS is designed to provide 99.99% durability of objects over a given year. This durability level corresponds to an average annual expected loss of 0.01% of objects. For example, if
you store 10,000 objects using the RRS option, you can on average expect to incur an annual loss of a single object (i.e. 0.01% of 10,000 objects). This annual loss represents an
expected average and does not guarantee the loss of 0.01% of objects in a given year.
The RRS option stores objects on multiple devices across multiple facilities, providing 400 times the durability of a typical disk drive, but does not replicate objects as many times
as standard Amazon S3 storage, and thus is even more cost effective. In addition, RRS is designed to sustain the loss of data in a single facility.
Amazon Glacier is a secure, durable, and extremely low-cost storage service for data archiving and online backup
Question : A corporate web application is deployed within an Amazon Virtual Private Cloud (VPC) and is connected to the corporate data center via an iPsec VPN.
The application must authenticate against the on-premises LDAP server. After authentication, each logged-in user can only access an Amazon Simple Storage Space (S3) keyspace
specific to that user. Which two approaches can satisfy these objectives? (Choose 2 answers)
A. Develop an identity broker that authenticates against IAM security Token service to assume a IAM role in order to get temporary AWS security credentials. The application calls
the identity broker to get AWS temporary security credentials with access to the appropriate S3 bucket.
B. The application authenticates against LDAP and retrieves the name of an IAM role associated with the user. The application then calls the IAM Security Token Service to
assume that IAM role. The application can use the temporary credentials to access the appropriate S3 bucket.
C. Develop an identity broker that authenticates against LDAP and then calls IAM Security Token Service to get IAM federated user credentials. The application calls the identity
broker to get IAM federated user credentials with access to the appropriate S3 bucket.
D. The application authenticates against LDAP the application then calls the AWS identity and Access Management (IAM) Security service to log in to IAM using the LDAP
credentials the application can use the IAM temporary credentials to access the appropriate S3 bucket.
E. The application authenticates against IAM Security Token Service using the LDAP credentials the application uses those temporary AWS security credentials to access the
appropriate S3 bucket.
1. A,B
2. B,C
3. Access Mostly Uused Products by 50000+ Subscribers
4. D,E
5. A,E
Correct Answer : Get Lastest Questions and Answer :
Approach A does not even talk about LDAP , hence out.
C is correct appraoch
Identity Broker(C) and AssumeRole(B) are two approaches to access AWS resources.
AssumeRole
Returns a set of temporary security credentials (consisting of an access key ID, a secret access key, and a security token) that you can use to access AWS resources that you might
not normally have access to. Typically, you use AssumeRole for cross-account access or federation.
Identity Federation
Today we are enabling Identity Federation with IAM. This new capability allows existing identities (e.g. users) in your enterprise to access AWS APIs and resources using IAM's
fine-grained access controls, without the need to create an IAM user for each identity.
Applications can now request temporary security credentials that can be used to sign requests to AWS. The temporary security credentials are comprised of short lived (1-36 hour)
access keys and session tokens associated with the keys. Your enterprise users (or, to be a bit more precise, the AWS-powered applications that they run) can use the access keys the
same way as before, as long as they pass the token along in the calls that they make to the AWS APIs. The permissions associated with temporary security credentials are at most equal
to those of the IAM user who issued them; you can further restrict them by specifying explicit permissions as part of the request to create them. Moreover, there is no limit on the
number of temporary security credentials that can be issued.
Question : An organization is measuring the latency of an application every minute and storing data inside a file in the JSON format. The organization wants
to send all latency data to AWS CloudWatch. How can the organization achieve this?

1. The user has to parse the file before uploading data to CloudWatch
2. It is not possible to upload the custom data to CloudWatch
3. Access Mostly Uused Products by 50000+ Subscribers
4. The user can use the CloudWatch Import command to import data from the file to CloudWatch
Answer: 3
Explanation: AWS CloudWatch supports the custom metrics. The user can always capture the custom data and upload the data to CloudWatch using CLI or
APIs. The user has to always include the namespace as part of the request. If the user wants to upload the custom data from a file, he can supply
file name along with the parameter -- metric-data to command put-metric-data.
Related Questions
Question : You are designing network connectivity for your fat client application. The application is designed for business travelers who must be able to connect
to it from their hotel rooms, cafes, public Wi-Fi hotspots, and elsewhere on the Internet. You do not want to publish the application on the Internet.
Which network design meets the above requirements while minimizing deployment and operational costs?

1. Implement AWS Direct Connect, and create a private interface to your VPC. Create a public subnet and place your application servers in it.
2. Implement Elastic Load Balancing with an SSL listener that terminates the back-end connection to the application.
3. Access Mostly Uused Products by 50000+ Subscribers
4. Configure an SSL VPN solution in a public subnet of your VPC, then install and configure SSL VPN client software on all user computers. Create a private subnet in your
VPC and place your application servers in it.
Question : You are building a website that will retrieve and display highly sensitive information to users. The amount of traffic the site will receive is known
and not expected to fluctuate. The site will leverage SSL to protect the communication between the clients and the web servers. Due to the nature of the site you
are very concerned about the security of your SSL private key and want to ensure that the key cannot be accidentally or intentionally moved outside your
environment. Additionally, while the data the site will display is stored on an encrypted EBS volume, you are also concerned that the web servers' logs might
contain some sensitive information; therefore, the logs must be stored so that they can only be decrypted by employees of your company. Which of these architectures
meets all of the requirements?

1. Use Elastic Load Balancing to distribute traffic to a set of web servers. To protect the SSL private key, upload the key to the load balancer and configure the load
balancer to offload the SSL traffic. Write your web server logs to an ephemeral volume that has been encrypted using a randomly generated AES key.
2. Use Elastic Load Balancing to distribute traffic to a set of web servers. Use TCP load balancing on the load balancer and configure your web servers to retrieve the
private key from a private Amazon S3 bucket on boot. Write your web server logs to a private Amazon S3 bucket using Amazon S3 server-side encryption.
3. Access Mostly Uused Products by 50000+ Subscribers
SSL transactions, and write your web server logs to a private Amazon S3 bucket using Amazon S3 server-side encryption.
4. Use Elastic Load Balancing to distribute traffic to a set of web servers. Configure the load balancer to perform TCP load balancing, use an AWS CloudHSM to perform the
SSL transactions, and write your web server logs to an ephemeral volume that has been encrypted using a randomly generated AES key.
Question : Your company's on-premises content management system has the following architecture:
- Application Tier - Java code on a JBoss application server
- Database Tier - Oracle database regularly backed up to Amazon Simple Storage Service (S3) using the Oracle RMAN backup utility
- Static Content - stored on a 512GB gateway stored Storage Gateway volume attached to the application server via the iSCSI interface
Which AWS based disaster recovery strategy will give you the best RTO?

1. Deploy the Oracle database and the JBoss app server on EC2. Restore the RMAN Oracle backups from Amazon S3. Generate an EBS volume of static content from the Storage
Gateway and attach it to the JBoss EC2 server.
2. Deploy the Oracle database on RDS. Deploy the JBoss app server on EC2. Restore the RMAN Oracle backups from Amazon Glacier. Generate an EBS volume of static content
from the Storage Gateway and attach it to the JBoss EC2 server.
3. Access Mostly Uused Products by 50000+ Subscribers
Gateway running on Amazon EC2 as an iSCSI volume to the JBoss EC2 server.
4. Deploy the Oracle database and the JBoss app server on EC2. Restore the RMAN Oracle backups from Amazon S3. Restore the static content from an AWS Storage Gateway-VTL
running on Amazon EC2
Question : An ERP application is deployed in multiple Availability Zones in a single region. In the event of failure, the RTO must be less than hours, and the
RPO is 15 minutes. The customer realizes that data corruption occurred roughly 1.5 hours ago. Which DR strategy can be used to achieve this RTO and RPO in the event
of this kind of failure?

1. Take 15-minute DB backups stored in Amazon Glacier, with transaction logs stored in Amazon S3 every 5 minutes.
2. Use synchronous database master-slave replication between two Availability Zones.
3. Access Mostly Uused Products by 50000+ Subscribers
4. Take hourly DB backups to an Amazon EC2 instance store volume, with transaction logs stored in Amazon S3 every 5 minutes.
Question : QuickTechie.com is having a VPC for the Billing team, and another VPC for the Risk Team. The Billing team team requires access to all the instances
running in the Risk Team VPC while the Risk Team requires access to all the resources in the Billing Team. How can the QuickTechie.com setup this scenario?
1. Setup ACL with both VPCs which will allow traffic from the CIDR of the other VPC.
2. Setup VPC peering between the VPCs of Risk Team and Billing Team.
3. Access Mostly Uused Products by 50000+ Subscribers
4. Setup the security group with each VPC which allows traffic from the CIDR of another VPC
Question : VPC Peering Connection Lifecycle, please fill in the exception scenerio marked in red.
1. Failed
2. Expired
3. Access Mostly Uused Products by 50000+ Subscribers
4. Deleted
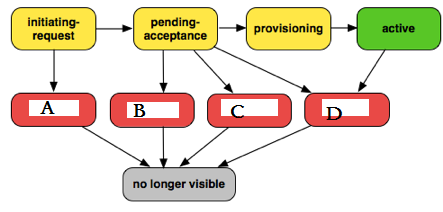
1. A-1, B-2, C-3, D-4
2. A-4, B-3, C-2, D-1
3. Access Mostly Uused Products by 50000+ Subscribers
4. A-2, B-1, C-4, D-3