Cloudera Hadoop Administrator Certification Certification Questions and Answer (Dumps and Practice Questions)
Question : You observed that the number of spilled records from Map tasks far exceeds the number of map output
records. Your child heap size is 1GB and your io.sort.mb value is set to 1000MB. How would you tune your io.
sort.mb value to achieve maximum memory to disk I/O ratio?

1. For a 1GB child heap size an io.sort.mb of 128 MB will always maximize memory to disk I/O
2. Increase the io.sort.mb to 1GB
3. Access Mostly Uused Products by 50000+ Subscribers
4. Tune the io.sort.mb value until you observe that the number of spilled records equals (or is as close to
equals) the number of map output records.
Correct Answer : Get Lastest Questions and Answer :
Explanation: MapReduce makes the guarantee that the input to every reducer is sorted by key. The process by which the system performs the sort—and transfers the map outputs to the reducers as inputs—is known as the shuffle.51 In this section, we look at how the shuffle works, as a basic understanding would be helpful, should you need to optimize a MapReduce program. The shuffle is an area of the codebase where refinements and improvements are continually being made, so the following description necessarily conceals many details (and may change over time, this is for version 0.20). In many ways, the shuffle is the heart of MapReduce and is where the "magic" happens.
The Map Side
When the map function starts producing output, it is not simply written to disk. The process is more involved, and takes advantage of buffering writes in memory and doing some presorting for efficiency reasons.
Each map task has a circular memory buffer that it writes the output to. The buffer is 100 MB by default, a size which can be tuned by changing the io.sort.mb property. When the contents of the buffer reaches a certain threshold size (io.sort.spill.percent, default 0.80, or 80%), a background thread will start to spill the contents to disk. Map outputs will continue to be written to the buffer while the spill takes place, but if the buffer fills up during this time, the map will block until the spill is complete.
Spills are written in round-robin fashion to the directories specified by the mapred.local.dir property, in a job-specific subdirectory.
Before it writes to disk, the thread first divides the data into partitions corresponding to the reducers that they will ultimately be sent to. Within each partition, the background thread performs an in-memory sort by key, and if there is a combiner function, it is run on the output of the sort.
Each time the memory buffer reaches the spill threshold, a new spill file is created, so after the map task has written its last output record there could be several spill files. Before the task is finished, the spill files are merged into a single partitioned and sorted output file. The configuration property io.sort.factor controls the maximum number of streams to merge at once; the default is 10.
If a combiner function has been specified, and the number of spills is at least three (the value of the min.num.spills.for.combine property), then the combiner is run before the output file is written. Recall that combiners may be run repeatedly over the input without affecting the final result. The point is that running combiners makes for a more compact map output, so there is less data to write to local disk and to transfer to the reducer.
It is often a good idea to compress the map output as it is written to disk, since doing so makes it faster to write to disk, saves disk space, and reduces the amount of data to transfer to the reducer. By default, the output is not compressed, but it is easy to enable by setting mapred.compress.map.output to true. The compression library to use is specified by mapred.map.output.compression.codec; see Compression for more on compression formats.
The output file’s partitions are made available to the reducers over HTTP. The number of worker threads used to serve the file partitions is controlled by the tasktracker.http.threads property—this setting is per tasktracker, not per map task slot. The default of 40 may need increasing for large clusters running large jobs.
Watch the training from http://hadoopexam.com/index.html/#hadoop-training
Question : You are running a Hadoop cluster with a NameNode on host mynamenode, a secondary NameNode on host
mysecondarynamenode and several DataNodes.
Which best describes how you determine when the last checkpoint happened?
1. Execute hdfs namenode report on the command line and look at the Last Checkpoint information
2. Execute hdfs dfsadmin saveNamespace on the command line which returns to you the last checkpoint
value in fstime file
3. Access Mostly Uused Products by 50000+ Subscribers
Checkpoint information
4. Connect to the web UI of the NameNode (http://mynamenode:50070) and look at the Last Checkpoint
information
Correct Answer : Get Lastest Questions and Answer :
Explanation: The Secondary NameNode’s Web UI contains information on when it last performed its checkpoint operation.
This is not displayed via the NameNode’s Web UI, and is not available via the hdfs dfsadmin command.
Watch the training from http://hadoopexam.com/index.html/#hadoop-training
Question : What does CDH packaging do on install to facilitate Kerberos security setup?
1. Automatically configures permissions for log files at &MAPRED_LOG_DIR/userlogs
2. Creates users for hdfs and mapreduce to facilitate role assignment
3. Access Mostly Uused Products by 50000+ Subscribers
4. Creates a set of pre-configured Kerberos keytab files and their permissions
5. Creates and configures your kdc with default cluster values
Correct Answer : Get Lastest Questions and Answer :
Explanation: Kerberos is a security system which provides authentication to the Hadoop cluster. It has nothing to do with data encryption, nor does it control login to the cluster nodes themselves. Instead, it concerns itself with ensuring that only authorized users can access the cluster via HDFS and MapReduce. (It also controls other access, such as via Hive, Sqoop etc.)
A number of special users are created by default when installing and using CDH & Cloudera Manager. Also corresponding Kerberos principals and keytab files that should be created when you configure Kerberos security on your cluster.
Note: The Kerberos principal names should be of the format, username/fully.qualified.domain.name@YOUR-REALM.COM, where the term username refers to the username of an existing UNIX account, such as hdfs or mapred. For example, the Kerberos principal for Apache Flume would be flume/fully.qualified.domain.name@YOUR-REALM.COM.
Watch the training Module 21 from http://hadoopexam.com/index.html/#hadoop-training
Related Questions
Question
What happens when you run the below job twice , having each input directory as one of the data file called data.csv.
with following command. Assuming there were no output directory exist
hadoop job HadoopExam.jar HadoopExam inputdata_1 output
hadoop job HadoopExam.jar HadoopExam inputdata_2 output
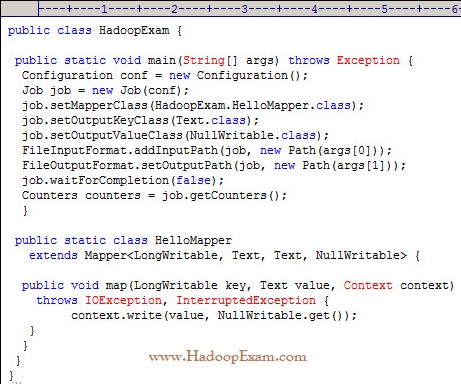
1. Both the job will write the output to output directoy and output will be appended
2. Both the job will fail, saying output directory does not exist.
3. Access Mostly Uused Products by 50000+ Subscribers
4. Both the job will successfully completes and second job will overwrite the output of first.
Ans : 3
Exp : First job will successfully run and second one will fail, because, if (output directory already exist then it will not run
and throws exception, complaining output directory already exist.
Question : You have a an EVENT table with following schema in the Oracle database.
PAGEID NUMBER
USER VARCHAR2
EVENTTIME DATE
PLACE VARCHAR2
Which of the following command creates the correct HIVE table named EVENT

1.
2.
3. Access Mostly Uused Products by 50000+ Subscribers
4.
Ans : 2
Exp : The above is correct because it correctly uses the Sqoop operation to create a Hive table that matches the database table.
Option 3rd is not correct because --hive-table option for Sqoop requires a parameter that names the target table in the database.
Question : Please find out the three correct functionalities of the ResourceManager in YARN or MRv Hadoop Cluster.
1. Monitoring the status of the ApplicationMaster container and restarting on failure
2. Negotiating cluster resource containers from the Scheduler, tracking containter status, and monitoring job progress
3. Monitoring and reporting container status for map and reduce tasks
4. Tracking heartbeats from the NodeManagers
5. Running a scheduler to determine how resources are allocated
6. Archiving the job history information and meta-data

1. 2,3,5
2. 3,4,5
3. Access Mostly Uused Products by 50000+ Subscribers
4. 1,4,5
5. 1,2,6
Question : In MRv YARN Hadoop Infrastructure where does MapReduce intermediate data as an output of Mappers will be stored.
1. In HDFS, in the job's output directory
2. In HDFS, in a temporary directory defined by mapred.tmp.dir
3. Access Mostly Uused Products by 50000+ Subscribers
4. On the underlying filesystem of the ResourceManager node
5. On the underlying filesystem of the local disk of the node on which the Reducer will run, as specified by the ResourceManager
Question : As part of QuickTechie Inc Hadoop Administrator you have upgraded your Hadoop cluster from MRv to MRv, Now you have
to report your manager that, how would you determine the number of Mappers required for a MapReduce job in a new cluster.
Select the correct one form below.
1. The number of Mappers is equal to the number of InputSplits calculated by the client submitting the job
2. The ApplicationMaster chooses the number based on the number of available nodes
3. Access Mostly Uused Products by 50000+ Subscribers
4. NodeManager where the job's HDFS blocks reside
5. The developer specifies the number in the job configuration
Question : Which of the following command will delete the Hive table nameed EVENTINFO
1. hive -e 'DROP TABLE EVENTINFO'
2. hive 'DROP TABLE EVENTINFO'
3. Access Mostly Uused Products by 50000+ Subscribers
4. hive -e 'TRASH TABLE EVENTINFO'
1.
2.
3. Access Mostly Uused Products by 50000+ Subscribers
4.
Ans :1
Exp : Sqoop does not offer a way to delete a table from Hive, although it will overwrite the table definition during
import if the table already exists and --hive-overwrite is specified. The correct HiveQL statement to drop a table
is "DROP TABLE tablename". In Hive, table names are all case insensitives
Question : There is no tables in Hive, which command will
import the entire contents of the EVENT table from
the database into a Hive table called EVENT
that uses commas (,) to separate the fields in the data files?

1.
2.
3. Access Mostly Uused Products by 50000+ Subscribers
4.
Ans :2
Exp : --fields-terminated-by option controls the character used to separate the fields in the Hive table's data files.
Question : You have a MapReduce job which is dependent on two external jdbc jars called ojdbc.jar and openJdbc.jar
which of the following command will correctly oncludes this external jars in the running Jobs classpath
1. hadoop jar job.jar HadoopExam -cp ojdbc6.jar,openJdbc6.jar
2. hadoop jar job.jar HadoopExam -libjars ojdbc6.jar,openJdbc6.jar
3. Access Mostly Uused Products by 50000+ Subscribers
4. hadoop jar job.jar HadoopExam -libjars ojdbc6.jar openJdbc6.jar
Ans : 2
Exp : The syntax for executing a job and including archives in the job's classpath is: hadoop jar -libjars ,[,...]
Question : You have a an EVENT table with following schema in the MySQL database.
PAGEID NUMBER
USER VARCHAR2
EVENTTIME DATE
PLACE VARCHAR2
Now that the database EVENT table has been imported and is stored in the dbimport directory in HDFS,
you would like to make the data available as a Hive table.
Which of the following statements is true? Assume that the data was imported in CSV format.
1. An Hive table can be created with the Hive CREATE command.
2. An external Hive table can be created with the Hive CREATE command that uses the data in the dbimport directory unchanged and in place.
3. Access Mostly Uused Products by 50000+ Subscribers
4. All of the above is correct.
Ans : 2
Exp : An external Hive table can be created that points to any file in HDFS.
The table can be configured to use arbitrary field and row delimeters or even extract fields via regular expressions.
Question : You have Sqoop to import the EVENT table from the database,
then write a Hadoop streaming job in Python to scrub the data,
and use Hive to write the new data into the Hive EVENT table.
How would you automate this data pipeline?
1. Using first Sqoop job and then remaining Part using MapReduce job chaining.
2. Define the Sqoop job, the MapReduce job, and the Hive job as an Oozie workflow job, and define an Oozie coordinator job to run the workflow job daily.
3. Access Mostly Uused Products by 50000+ Subscribers
4. Define the Sqoop job, the MapReduce job, and the Hive job as an Oozie workflow job,
and define an Zookeeper coordinator job to run the workflow job daily.
Ans :2
Exp : In Oozie, scheduling is the function of an Oozie coordinator job.
Oozie does not allow you to schedule workflow jobs
Oozie coordinator jobs cannot aggregate tasks or define workflows;
coordinator jobs are simple schedules of previously defined worksflows.
You must therefore assemble the various tasks into a single workflow
job and then use a coordinator job to execute the workflow job.
Question : Which of the following default character used by Sqoop as field delimiters in the Hive table data file?
1. 0x01
2. 0x001
3. Access Mostly Uused Products by 50000+ Subscribers
4. 0x011
Ans :1
Exp : By default Sqoop uses Hives default delimiters when doing a Hive table export, which is 0x01 (^A)
Question In a Sqoop job Assume $PREVIOUSREFRESH contains a date:time string for the last time the import was run, e.g., '-- ::'.
Which of the following import command control arguments prevent a repeating Sqoop job from downloading the entire EVENT table every day?
1. --incremental lastmodified --refresh-column lastmodified --last-value "$PREVIOUSREFRESH"
2. --incremental lastmodified --check-column lastmodified --last-time "$PREVIOUSREFRESH"
3. Access Mostly Uused Products by 50000+ Subscribers
4. --incremental lastmodified --check-column lastmodified --last-value "$PREVIOUSREFRESH"
Question : You have a log file loaded in HDFS, wich of of the folloiwng operation will allow you to create Hive table using this log file in HDFS.
1. Create an external table in the Hive shell to extract the column data from the logs
2. Create an external table in the Hive shell using org.apache.hadoop.hive.serde2.RegexSerDe to extract the column data from the logs
3. Access Mostly Uused Products by 50000+ Subscribers
4. Create an external table in the Hive shell using org.apache.hadoop.hive.serde2.CSVSerDe to extract the column data from the logs
Ans : 2
Exp : RegexSerDe uses regular expression (regex) to deserialize data.
It doesn't support data serialization. It can deserialize the data using regex and extracts groups as columns.
In deserialization stage, if a row does not match the regex, then all columns in the row will be NULL.
If a row matches the regex but has less than expected groups, the missing groups will be NULL.
If a row matches the regex but has more than expected groups, the additional groups are just ignored.
NOTE: Obviously, all columns have to be strings.
Users can use "CAST(a AS INT)" to convert columns to other types.
NOTE: This implementation is using String, and javaStringObjectInspector.
A more efficient implementation should use UTF-8 encoded Text and writableStringObjectInspector.
We should switch to that when we have a UTF-8 based Regex library.
When building a Hive table from log data, the column widths are not fixed,
so the only way to extract the data is with a regular expression.
The org.apache.hadoop.hive.serde2.RegexSerDe class reads data from a flat file and extracts column information
via a regular expression. The SerDe is specified as part of the table definition when the table is created.
Once the table is created, the LOAD command will add the log files to the table.
Question : You write a Sqoop job to pull the data from the USERS table, but your job pulls the
entire USERS table every day. Assume$LASTIMPORT contains a date:time string for the
last time the import was run, e.g., '2013-09-20 15:27:52'. Which import control
arguments prevent a repeating Sqoop job from downloading the entire USERS table every day?
1. --incremental lastmodified --last-value "$LASTIMPORT"
2. --incremental lastmodified --check-column lastmodified --last-value "$LASTIMPORT"
3. Access Mostly Uused Products by 50000+ Subscribers
4. --incremental "$LASTIMPORT" --check-column lastmodified --last-value "$LASTIMPORT"
Ans : 2
Exp : The --where import control argument lets you specify a select statement to use when importing data,
but it takes a full select statement and must include $CONDITIONS in the WHERE clause.
There is no --since option. The --incremental option does what we want.
Watch Module 22 : http://hadoopexam.com/index.html/#hadoop-training
And refer : http://sqoop.apache.org/docs/1.4.3/SqoopUserGuide.html
Question : Now that you have the USERS table imported into Hive, you need to make the log data available
to Hive so that you can perform a join operation. Assuming you have uploaded the log data into HDFS,
which approach creates a Hive table that contains the log data:
1. Create an external table in the Hive shell using org.apache.hadoop.hive.serde2.SerDeStatsStruct to extract the column data from the logs
2. Create an external table in the Hive shell using org.apache.hadoop.hive.serde2.RegexSerDe to extract the column data from the logs
3. Access Mostly Uused Products by 50000+ Subscribers
4. Create an external table in the Hive shell using org.apache.hadoop.hive.serde2.NullStructSerDe to extract the column data from the logs
Ans : 2
Exp : When building a Hive table from log data, the column widths are not fixed, so the only way to extract the data is with a regular expression. The org.apache.hadoop.hive.serde2.RegexSerDe class reads data from a flat file and extracts column information via a regular expression. The SerDe is specified as part of the table definition when the table is created. Once the table is created, the LOAD command will add the log files to the table. For more information about SerDes in Hive, see How-to: Use a SerDe in Apache Hive and chapter 12 in Hadoop: The Definitive Guide, 3rd Edition in the Tables: Storage Formats section.
Watch Module 12 and 13 : http://hadoopexam.com/index.html/#hadoop-training
And refer : https://hive.apache.org/javadocs/r0.10.0/api/org/apache/hadoop/hive/serde2/package-summary.html
Question :
The cluster block size is set to 128MB. The input file contains 170MB of valid input data
and is loaded into HDFS with the default block size. How many map tasks will be run during the execution of this job?
1. 1
2. 2
3. Access Mostly Uused Products by 50000+ Subscribers
4. 4
Question : For each YARN job, the Hadoop framework generates task log file. Where are Hadoop task log files stored?
1. Cached by the NodeManager managing the job containers, then written to a log directory on the NameNode
2. Cached in the YARN container running the task, then copied into HDFS on job completion
3. Access Mostly Uused Products by 50000+ Subscribers
4. On the local disk of the slave mode running the task