Dell EMC Data Science and BigData Certification Questions and Answers
Question : You are using the Apriori algorithm to determine the likelihood that a person who owns a home
has a good credit score. You have determined that the confidence for the rules used in the
algorithm is > 75%. You calculate lift = 1.011 for the rule, "People with good credit are
homeowners". What can you determine from the lift calculation?

1. Support for the association is low
2. Leverage of the rules is low
3. Access Mostly Uused Products by 50000+ Subscribers
4. The rule is true
Correct Answer : Get Lastest Questions and Answer : Exp: Apriori is an algorithm for frequent item set mining and association rule learning over transactional databases. It proceeds by identifying the frequent individual items in the database and
extending them to larger and larger item sets as long as those item sets appear sufficiently often in the database. The frequent item sets determined by Apriori can be used to determine association rules which
highlight general trends in the database: this has applications in domains such as market basket analysis.
The whole point of the algorithm (and data mining, in general) is to extract useful information from large amounts of data. For example, the information that a customer who purchases a keyboard also tends to buy a
mouse at the same time is acquired from the association rule below:
Support: The percentage of task-relevant data transactions for which the pattern is true.
Support (Keyboard -> Mouse) = No. of Transactions containing both Keyboards and Mouse/No. of total transactions
Confidence: The measure of certainty or trustworthiness associated with each discovered pattern.
Confidence (Keyboard -> Mouse) = No. of Transactions containing both Keyboards and Mouse/No. of transactions containing (Keyboard)
The algorithm aims to find the rules which satisfy both a minimum support threshold and a minimum confidence threshold (Strong Rules).
Item: article in the basket.
Itemset: a group of items purchased together in a single transaction.
Question : What is an appropriate data visualization to use in a presentation for an analyst audience?

1. Pie chart
2. ROC curve
3. Access Mostly Uused Products by 50000+ Subscribers
4. Stacked bar chart
Correct Answer : Get Lastest Questions and Answer :
Exp: In a ROC curve the true positive rate (Sensitivity) is plotted in function of the false positive rate (100-Specificity) for different cut-off points of a parameter. Each point on the ROC curve represents a
sensitivity/specificity pair corresponding to a particular decision threshold. The area under the ROC curve (AUC) is a measure of how well a parameter can distinguish between two diagnostic groups (diseased/normal).
Logistic regression is often used as a classifier to assign class labels to a person, item, or transaction based on the predicted probability provided by the model. In the Churn example, a customer can be classified
with the label called Churn if the logistic model predicts a high probability that the customer will churn. Otherwise, a Remain label is assigned to the customer. Commonly, 0.5 is used as the default probability
threshold to distinguish between any two class labels. However, any threshold value can be used depending on the preference to avoid false positives (for example, to predict Churn when actually the customer will
Remain) or false negatives (for example, to predict Remain when the customer will actually Churn).
Question : Consider a database with transactions:
Transaction 1: {cheese, bread, milk}
Transaction 2: {soda, bread, milk}
Transaction 3: {cheese, bread}
Transaction 4: {cheese, soda, juice}
The minimum support is 25%. Which rule has a confidence equal to 50%?

1. {bread} => {milk}
2. {bread, milk} => {cheese}
3. Access Mostly Uused Products by 50000+ Subscribers
4. {bread} => {cheese}
Correct Answer : Get Lastest Questions and Answer : Exp: Only one time {cheese, bread, milk}
Related Questions
Question : You are using k-means clustering to discover groupings within a data set. You plot within-sum-ofsquares
(wss) of multiple cluster sizes. Based on the exhibit, how many clusters should you use in
your analysis?
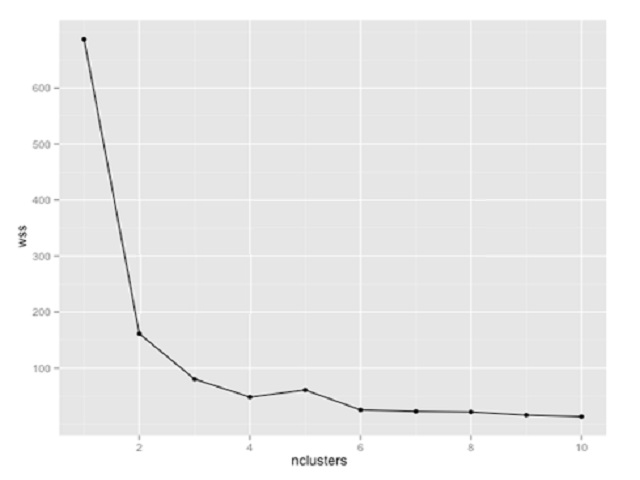
1. 2
2. 3
3. Access Mostly Uused Products by 50000+ Subscribers
4. 8
Question : Certain individuals are more susceptible to autism if they have particular combinations of genes
expressed in their DNA. Given a sample of DNA from persons who have autism and a sample of
DNA from persons who do not have autism, determine the best technique for predicting whether
or not a given individual is susceptible to developing autism?

1. Naive Bayes
2. Survival analysis
3. Access Mostly Uused Products by 50000+ Subscribers
4. Sequencealignment
Question : You are working with a logistic regression model to predict the probability that a user will click on
an ad. Your model has hundreds of features, and you're not sure if all of those features are
helping your prediction. Which regularization technique should you use to prune features that
aren't contributing to the model?
1. Convex
2. Uniform
3. Access Mostly Uused Products by 50000+ Subscribers
4. L1
Question : What is the most common reason for a k-means clustering algorithm to returns a sub-optimal
clustering of its input?
1. Non-negative values for the distance function
2. Input data set is too large
3. Access Mostly Uused Products by 50000+ Subscribers
4. Poor selection of the initial controls