Cloudera Hadoop Developer Certification Questions and Answer (Dumps and Practice Questions)
Question :
In which scenerio MapReduce is not suitable..

1. text mining on the unstructured documents
2. Analyzing web documents
3. Access Mostly Uused Products by 50000+ Subscribers
4. for a large computation of finacial risk modeling and performance analysis.
Correct Answer : Get Lastest Questions and Answer :
Question : How can you use binary data in MapReduce?
1. Binary data can be used directly by a map-reduce job. Often binary data is added to a sequence file
2. Binary data cannot be used by Hadoop fremework. Binary data should be converted to a Hadoop compatible format prior to loading
3. Access Mostly Uused Products by 50000+ Subscribers
4. Hadoop can freely use binary files with map-reduce jobs so long as the files have headers
Correct Answer : Get Lastest Questions and Answer :
Explanation: Binary data can be packaged in sequence files. Hadoop cluster does not work very well with large numbers of small files. Therefore, small files should be combined into bigger ones..
Question : What is map - side join?
1. Map-side join is done in the map phase and done in memory
2. Map-side join is a technique in which data is eliminated at the map step
3. Access Mostly Uused Products by 50000+ Subscribers
4. None of these answers are correct
Correct Answer : Get Lastest Questions and Answer :
Explanation: The map-side join is a techinique that allows for splitting map file between different data nodes. The data will be loaded into memory. This technique allow very fast performance for the join
Related Questions
Question : We have extracted the data from
MySQL backend database of QuickTechie.com
website and stored in the
Hive table called MAINPROFILE as shown in image
with the sample data and also shown column datatype.
As this table is created from the data
which is already stored in a
warehouse directory of Hive.
Select the correct MapReduce
code which simulate
the following Query
SELECT USERID
FROM MAINPROFILE
WHERE FIRST_NAME = "PANKAJ";
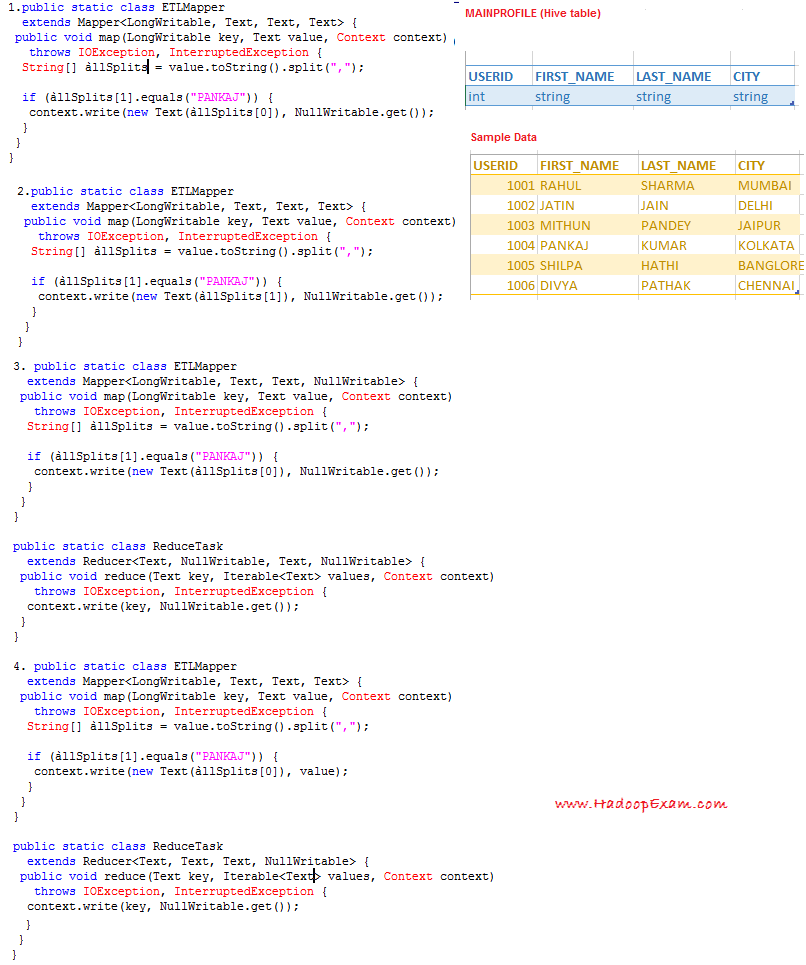
1. 1
2. 2
3. Access Mostly Uused Products by 50000+ Subscribers
4. 4
Question : Which statement is true
1. Output of the reducer could be zero
2. Output of the reducer is written to the HDFS
3. In practice, the reducer usually emits a single key-value pair for each input key
4. All of the above
Question : What is data localization ?
1. Before processing the data, bringing them to the local node.
2. Hadoop will start the Map task on the node where data block is kept via HDFS
3. 1 and 2 both are correct
4. None of the 1 and 2 is correct
Question : All the mappers, have to communicate with all the reducers...
1. True
2. False