Dell EMC Data Science Associate Certification Questions and Answers (Dumps and Practice Questions)
Question : Which characteristic applies mainly to Data Science as opposed to Business Intelligence?

1. Data dashboards
2. Focus on structured data
3. Access Mostly Uused Products by 50000+ Subscribers
4. Advanced analytical methods
Correct Answer : Get Lastest Questions and Answer :
Explanation: Data Science is different than the traditional Business Analytics in some key areas. For example, data science:
uses predictive and prescriptive analytics to predict what might happen using probabilities and confidence levels, not just report tools to report on what did happen.
Note: when we're dealing with historical data, there is a strong desire and need for the data to be 100% accurate. If you have your financial results wrong for the past quarter, folks are likely to go to jail. However predicting performance for the next quarter is usually measured in probabilities and confidence levels (e.g., "There is a 95% confidence that our revenues will come in next quarter between $200M to $212M).
is used for dealing with and mitigating the uncertainty in the data. It uses several analytic and visualization techniques to understand where uncertainty may lay in the data, and then uses data transformation techniques to massage the data into a workable form - not perfect, but again not necessary when dealing with probabilities and not absolutes.
is able to create as-needed data transformations (versus the traditional ETL process) to put the data into a format so that it can be combined with other data sources in search in insights about customers, products and operations.
Question : Which word or phrase completes the statement?
Theater actor is to "Artistic and Expressive" as Data Scientist is to ________________
1. Introverted and Technical
2. Logical and Steadfast
3. Access Mostly Uused Products by 50000+ Subscribers
4. Communicative and Collaborative
Correct Answer : Get Lastest Questions and Answer :
Exp: Data scientists are generally thought of as having five main sets of skills and behavioral characteristics.
Quantitative skill: such as mathematics or statistics
Technical aptitude: namely, software engineering, machine learning, and
programming skills
Skeptical mind-set and critical thinking: It is important that data scientists can
examine their work critically rather than in a one-sided way.
Curious and creative: Data scientists are passionate about data and finding creative
ways to solve problems and portray information.
Communicative and collaborative: Data scientists must be able to articulate the
business value in a clear way and collaboratively work with other groups, including
project sponsors and key stakeholders.
Question : Which process in text analysis can be used to reduce dimensionality?
1. Parsing
2. Stemming
3. Access Mostly Uused Products by 50000+ Subscribers
4. Sorting
Correct Answer : Get Lastest Questions and Answer :
Exp: Stemming is the term used in linguistic morphology and information retrieval to describe the process for reducing inflected (or sometimes derived) words to their word stem, base or root form-generally a written word form. The stem needs not to be identical to the morphological root of the word; it is usually sufficient that related words map to the same stem, even if this stem is not in itself a valid root. Algorithms for stemming have been studied in computer science since the 1960s. Many search engines treat words with the same stem as synonyms as a kind of query expansion, a process called conflation.
Stemming programs are commonly referred to as stemming algorithms or stemmers. A stemmer for English, for example, should identify the string "cats" (and possibly "catlike", "catty" etc.) as based on the root "cat", and "stemmer", "stemming", "stemmed" as based on "stem". A stemming algorithm reduces the words "fishing", "fished", and "fisher" to the root word, "fish". On the other hand, "argue", "argued", "argues", "arguing", and "argus" reduce to the stem "argu" (illustrating the case where the stem is not itself a word or root) but "argument" and "arguments" reduce to the stem "argument".
A stemming algorithm is a process of linguistic normalisation, in which the variant forms of a word are reduced to a common form, for example,
connection
connections
connective ---> connect
connected
connecting
It is important to appreciate that we use stemming with the intention of improving the performance of IR systems. It is not an exercise in etymology or grammar. In fact from an etymological or grammatical viewpoint, a stemming algorithm is liable to make many mistakes. In addition, stemming algorithms - at least the ones presented here - are applicable to the written, not the spoken, form of the language.
For some of the world's languages, Chinese for example, the concept of stemming is not applicable, but it is certainly meaningful for the many languages of the Indo-European group. In these languages words tend to be constant at the front, and to vary at the end:
-ion
-ions
connect-ive
-ed
-ing
The variable part is the 'ending', or 'suffix'. Taking these endings off is called 'suffix stripping' or 'stemming', and the residual part is called the stem.
Related Questions
Question : You are using k-means clustering to discover groupings within a data set. You plot within-sum-ofsquares
(wss) of multiple cluster sizes. Based on the exhibit, how many clusters should you use in
your analysis?
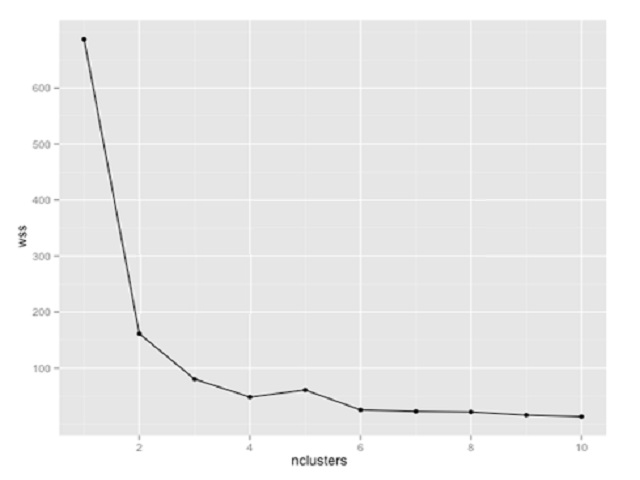
1. 2
2. 3
3. Access Mostly Uused Products by 50000+ Subscribers
4. 8
Question : Certain individuals are more susceptible to autism if they have particular combinations of genes
expressed in their DNA. Given a sample of DNA from persons who have autism and a sample of
DNA from persons who do not have autism, determine the best technique for predicting whether
or not a given individual is susceptible to developing autism?

1. Naive Bayes
2. Survival analysis
3. Access Mostly Uused Products by 50000+ Subscribers
4. Sequencealignment
Question : You are working with a logistic regression model to predict the probability that a user will click on
an ad. Your model has hundreds of features, and you're not sure if all of those features are
helping your prediction. Which regularization technique should you use to prune features that
aren't contributing to the model?
1. Convex
2. Uniform
3. Access Mostly Uused Products by 50000+ Subscribers
4. L1
Question : What is the most common reason for a k-means clustering algorithm to returns a sub-optimal
clustering of its input?
1. Non-negative values for the distance function
2. Input data set is too large
3. Access Mostly Uused Products by 50000+ Subscribers
4. Poor selection of the initial controls