Cloudera Databricks Data Science Certification Questions and Answers (Dumps and Practice Questions)
Question : Laplacian smoothing is an algorithm to smooth a polygonal mesh. For each vertex in a mesh, a new position is chosen based on local information
(such as the position of neighbors) and the vertex is moved there. In the case that a mesh is topologically a rectangular grid (that is, each internal
vertex is connected to four neighbors) then this operation produces the Laplacian of the mesh.In Laplace smoothing, you:

1. Increase the probability mass of items seen zero times, and increase the probability mass of items seen at least once.
2. Decrease the probability mass of items seen zero times, and decrease the probability mass of items seen at least once.
3. Access Mostly Uused Products by 50000+ Subscribers
4. Increase the probability mass of items seen zero times, and decrease the probability mass of items seen at least once.
Correct Answer : Get Lastest Questions and Answer :
Explanation: Laplacian smoothing is an algorithm to smooth a polygonal mesh.[1][2] For each vertex in a mesh, a new position is chosen based on local information (such as the position of neighbors) and the vertex is moved there. In the case that a mesh is topologically a rectangular grid (that is, each internal vertex is connected to four neighbors) then this operation produces the Laplacian of the mesh. If you think about it, this is just a ratio of counts p(j) =n(jc) / n(c), where n(jc) denotes the number of times that word appears in a spam email and n(c) denotes the number of times that word appears in any email. Laplace Smoothing refers to the idea of replacing our straight-up estimate of p (j) with something a bit fancier:
Counts p(j) =n(jc)+A / n(c)+B
We might fix A=1 and B=10, for example, to prevent the possibility of getting 0 or 1 for a probability, getting with the word "viagra." In Laplace smoothing, the zero-probability items are given a small amount of probability mass that is taken away from all of the non-zero-probability items buy counting that every item has been seen exactly one more time than it actually has. The effect is that items seen zero times are assumed to have been seen once, giving them non-zero probabilities.
Question : Select the correct statements from the below.
1. The sum of errors will be larger than mean absolute error if errors are positive
2. The mean absolute error will, be larger than the sum if errors are negative
3. Access Mostly Uused Products by 50000+ Subscribers
4. RMSE will equal MAE if all errors are equally large
5. RMSE will be smaller if all errors are not equally large
6. RMSE will be larger if all errors are not equally large
1. 1,3,4,6
2. 1,2,4,6
3. Access Mostly Uused Products by 50000+ Subscribers
4. 2,3,5,6
Correct Answer : Get Lastest Questions and Answer :
Explanation: Mean Square Error: this is the average squared distance between the predicted and actual values.
RMSE: The square root of mean squared error.
MAE: This is a variation on mean squared error and is simply the average of the absolute value of the difference between the predicted and actual values.
Question : You are working in an ecommerce organization, where you are designing and evaluating a recommender system,
you need to select which of the following will always have the largest value?
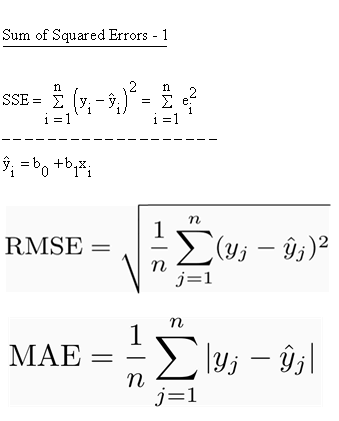
1. Root Mean Square Error
2. Sum of Squared Errors
3. Access Mostly Uused Products by 50000+ Subscribers
4. Both 1 and 2
5. Information is not good enough.
Correct Answer : Get Lastest Questions and Answer : Mean absolute error (MAE)
The MAE measures the average magnitude of the errors in a set of forecasts, without considering their direction. It measures accuracy for continuous variables. The equation is given in the library references. Expressed in words, the MAE is the average over the verification sample of the absolute values of the differences between forecast and the corresponding observation. The MAE is a linear score which means that all the individual differences are weighted equally in the average.
Root means squared error (RMSE)
The RMSE is a quadratic scoring rule which measures the average magnitude of the error. The equation for the RMSE is given in both of the references. Expressing the formula in words, the difference between forecast and corresponding observed values are each squared and then averaged over the sample. Finally, the square root of the average is taken. Since the errors are squared before they are averaged, the RMSE gives a relatively high weight to large errors. This means the RMSE is most useful when large errors are particularly undesirable.
The MAE and the RMSE can be used together to diagnose the variation in the errors in a set of forecasts. The RMSE will always be larger or equal to the MAE; the greater difference between them, the greater the variance in the individual errors in the sample. If the RMSE=MAE, then all the errors are of the same magnitude
Both the MAE and RMSE can range from 0 to ?. They are negatively-oriented scores: Lower values are better.
Mean Square Error: this is the average squared distance between the predicted and actual values.
RMSE: The square root of mean squared error.
MAE: This is a variation on mean squared error and is simply the average of the absolute value of the difference between the predicted and actual values.
1. The sum of errors will be larger than mean absolute error if errors are positive
2. The mean absolute error will, be larger than the sum if errors are negative
3. Access Mostly Uused Products by 50000+ Subscribers
4. RMSE will be larger if all errors are not equally large
Related Questions
Question : Select the correct pseudo function for the hashing trick

1.
2.
3.
4.
Question : What is the considerable difference between L and L regularization?
1. L1 regularization has more accuracy of the resulting model
2. Size of the model can be much smaller in L1 regularization than that produced by L2-regularization
3. L2-regularization can be of vital importance when the application is deployed in resource-tight environments such as cell-phones.
4. All of the above are correct
Question :
Which of the following could be features?
1. 1. Words in the document
2. 2. Symptoms of a diseases
3. 3. Characteristics of an unidentified object
4. 4. Only 1 and 2
5. 5. All 1,2 and 3 are possible
Question : Regularization is a very important technique in machine learning to prevent overfitting.
Mathematically speaking, it adds a regularization term in order to prevent the coefficients to fit so perfectly to overfit.
The difference between the L1 and L2 is_________
1. L2 is the sum of the square of the weights, while L1 is just the sum of the weights
2. L1 is the sum of the square of the weights, while L2 is just the sum of the weights
3. L1 gives Non-sparse output while L2 gives sparse outputs
4. None of the above
Question :

1.
2.
3.
4.
Question : Select the correct option which applies to L regularization
1. Computational efficient due to having analytical solutions
2. Non-sparse outputs
3. No feature selection
4. All of the above