Cloudera Hadoop Developer Certification Questions and Answer (Dumps and Practice Questions)
Question : What is the default replication factor in the HDFS...

1. 1
2. 2
3. Access Mostly Uused Products by 50000+ Subscribers
4. 4
Correct Answer : Get Lastest Questions and Answer :
Each block is replicated multiple times
- Default is to replicate each block three times
- Replicas are stored on different nodes
- This ensures both reliability and availability
Question : Which of the following are MapReduce processing phases ?
1. Map
2. Reduce
3. Access Mostly Uused Products by 50000+ Subscribers
4. Sort
5. 1 and 2 only
Correct Answer : Get Lastest Questions and Answer :
Mapreduce Consists of two phases: Map, and then Reduce
- Between the two is a stage known as the shuffle and sort
Question : What is true about HDFS ?
1. HDFS is based of Google File System
2. HDFS is written in Java
3. Access Mostly Uused Products by 50000+ Subscribers
4. All above are correct
Correct Answer : Get Lastest Questions and Answer :
HDFS is a filesystem written in Java
- Based on Google GFS
Sits on top of a native filesystem
ext3, xfs etc
Related Questions
Please find the answer to this Question at following URL in detail with explaination.
www.hadoopexam.com/P5_A55.jpg
Dont Remember Answers, please understand MapReduce in Depth. It is needed to clear live Question Exam Pattern
Question You have given following input file data..
119:12,Hadoop,Exam,ccd410
312:44,Pappu,Pass,cca410
441:53,"HBasa","Pass","ccb410"
5611:01',"No Event",
7881:12,Hadoop,Exam,ccd410
3451:12,HadoopExam
Special characters . * + ? ^ $ { [ ( | ) \ have special meaning and must be escaped with \ to be used without the special meaning : \. \* \+ \? \^ \$ \{ \[ \( \| \) \\Consider the meaning of regular expression as well
. any char, exactly 1 time
* any char, 0-8 times
+ any char, 1-8 times
? any char, 0-1 time
^ start of string (or line if multiline mode)
$ end of string (or line if multiline mode)
| equivalent to OR (there is no AND, check the reverse of what you need for AND)
After running the following MapReduce job what will be the output printed at console

1. 2 , 3
2. 2 , 4
3. Access Mostly Uused Products by 50000+ Subscribers
4. 5 , 1
5. 0 , 6
Correct Ans : 5
Exp : Meaning of regex as . any char, exactly 1 time (Please remember the regex)
* any char, 0-8 times
+ any char, 1-8 times
? any char, 0-1 time
^ start of string (or line if multiline mode)
$ end of string (or line if multiline mode)
| equivalent to OR (there is no AND, check the reverse of what you need for AND). First Record passed the regular expression
Second record also pass the expression
third record does not pass the expression, because hours part is in single digit as you can sse in the expression
first two d's are there.
It is expected that each record should have at least all five character as digit. Which no record suffice.
Hence in total matching records are 0 and non-matching records are 6
Please learn java regular expression it is mandatrory. Consider using Hadoop Professional Training Provided by HadoopExam.com if you face the problem.
Question
What happens when you run the below job twice , having each input directory as one of the data file called data.csv.
with following command. Assuming there were no output directory exist
hadoop job HadoopExam.jar HadoopExam inputdata_1 output
hadoop job HadoopExam.jar HadoopExam inputdata_2 output
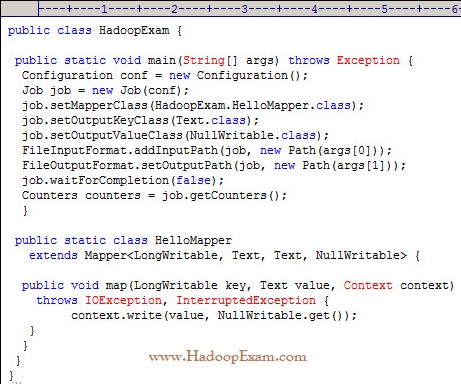
1. Both the job will write the output to output directoy and output will be appended
2. Both the job will fail, saying output directory does not exist.
3. Access Mostly Uused Products by 50000+ Subscribers
4. Both the job will successfully completes and second job will overwrite the output of first.
Ans : 3
Exp : First job will successfully run and second one will fail, because, if (output directory already exist then it will not run
and throws exception, complaining output directory already exist.
Question You have a an EVENT table with following schema in the Oracle database.
PAGEID NUMBER
USER VARCHAR2
EVENTTIME DATE
PLACE VARCHAR2
Which of the following command creates the correct HIVE table named EVENT

1.
2.
3. Access Mostly Uused Products by 50000+ Subscribers
4.
Ans : 2
Exp : The above is correct because it correctly uses the Sqoop operation to create a Hive table that matches the database table.
Option 3rd is not correct because --hive-table option for Sqoop requires a parameter that names the target table in the database.
Question : Which of the following command will delete the Hive table nameed EVENTINFO
1. hive -e 'DROP TABLE EVENTINFO'
2. hive 'DROP TABLE EVENTINFO'
3. Access Mostly Uused Products by 50000+ Subscribers
4. hive -e 'TRASH TABLE EVENTINFO'

1.
2.
3. Access Mostly Uused Products by 50000+ Subscribers
4.
Ans :1
Exp : Sqoop does not offer a way to delete a table from Hive, although it will overwrite the table definition during
import if the table already exists and --hive-overwrite is specified. The correct HiveQL statement to drop a table
is "DROP TABLE tablename". In Hive, table names are all case insensitives
Question There is no tables in Hive, which command will
import the entire contents of the EVENT table from
the database into a Hive table called EVENT
that uses commas (,) to separate the fields in the data files?

1.
2.
3. Access Mostly Uused Products by 50000+ Subscribers
4.
Ans :2
Exp : --fields-terminated-by option controls the character used to separate the fields in the Hive table's data files.
Question :
You have following data in a hive table
ID:INT,COLOR:TEXT,WIDTH:INT
1,green,190
2,blue,300
3,yellow,220
4,blue,199
5,green,199
6,yellow,299
7,green,799
Select the correct Mapper and Reducer which
can produce the output similar to following queries
Select id,color,width from table where width >=200;

1. 1
2. 2
3. Access Mostly Uused Products by 50000+ Subscribers
4. 4
Question :
You have following data in a hive table
ID:INT,COLOR:TEXT,WIDTH:INT
1,green,190
2,blue,300
3,yellow,220
4,blue,199
5,green,199
6,yellow,299
7,green,799
After running thje following MapReduce program, what output it will produces as first line.

1. 1,green,190
2. 4,blue,199
3. Access Mostly Uused Products by 50000+ Subscribers
4. it will through java.lang.ArrayIndexOutOfBoundsException
Question :
You have following data in a hive table
ID:INT,COLOR:TEXT,WIDTH:INT
1,green,190
2,blue,300
3,yellow,220
4,blue,199
5,green,199
6,yellow,299
7,green,799
Select the correct MapReduce program
which can produce the output similar
to below Hive Query.
Select color from table where width >=220;

1. 1
2. 2
3. Access Mostly Uused Products by 50000+ Subscribers
4. 4
Question :
You have following data in a hive table
ID:INT,COLOR:TEXT,WIDTH:INT
1,green,190
2,blue,300
3,yellow,220
4,blue,199
5,green,199
6,yellow,299
7,green,799
Select the correct MapReduce program which
can produce the output similar to below Hive Query.
Select id,color from table where width >=220;

1. 1
2. 2
3. Access Mostly Uused Products by 50000+ Subscribers
4. 4
Question :
You have following data in a hive table
ID:INT,COLOR:TEXT,WIDTH:INT
1,green,190
2,blue,300
3,yellow,220
4,blue,199
5,green,199
6,yellow,299
7,green,799
Select the correct MapReduce program which can produce
the output similar to below Hive Query
(Assuming single reducer is configured).
Select color,max(width) from table group by color;

1. 1
2. 2
3. Access Mostly Uused Products by 50000+ Subscribers
4. 4
Question :
You have following data in a hive table
ID:INT,COLOR:TEXT,WIDTH:INT
1,green,190
2,blue,300
3,yellow,220
4,blue,199
5,green,199
6,yellow,299
7,green,799
Select the correct MapReduce program
which can produce the output similar to below Hive Query
Select id,color,max(width) from table ;

1. 1
2. 2
3. Access Mostly Uused Products by 50000+ Subscribers
4. 4