Cloudera Hadoop Administrator Certification Certification Questions and Answer (Dumps and Practice Questions)
Question : As a QuickTechie Inc developer, you need to execute two MapReduce ETL job named QT and QT.
And the Hadoop cluster is configured with the YARN (MRv2 and Fair Scheduler enabled). And you submit a job QT1,
so that only job QT1 is running which almost take 5 hours to finish. After 1 Hour, you submit another Job QT2.
now Job QT1 and Job QT2 are running at the same time. Select the correct statement the way Fair Scheduler handle these two jobs?

1. When Job QT2 gets submitted, it will get assigned tasks, while job QT1 continues to run with fewer tasks
2. When Job QT2 gets submitted, Job QT1 has to finish first, before job QT1 can gets scheduled.
3. Access Mostly Uused Products by 50000+ Subscribers
4. When Job QT1 gets submitted, it consumes all the task slots.
Correct Answer : Get Lastest Questions and Answer :
Explanation: Fair scheduling is a method of assigning resources to applications such that all apps get, on average, an equal share of resources over time. Hadoop NextGen is capable of scheduling multiple resource types. By default, the Fair Scheduler bases scheduling fairness decisions only on memory. It can be configured to schedule with both memory and CPU, using the notion of Dominant Resource Fairness developed by Ghodsi et al. When there is a single app running, that app uses the entire cluster. When other apps are submitted, resources that free up are assigned to the new apps, so that each app eventually on gets roughly the same amount of resources. Unlike the default Hadoop scheduler, which forms a queue of apps, this lets short apps finish in reasonable time while not starving long-lived apps. It is also a reasonable way to share a cluster between a number of users. Finally, fair sharing can also work with app priorities - the priorities are used as weights to determine the fraction of total resources that each app should get.
The Fair Scheduler is designed to ensure that multiple jobs can run simultaneously on a cluster. If only one job is running on the cluster, it will consume as many task resources as it needs, up to the total capacity of the cluster. However, if another job is submitted, those jobs are then fair scheduled, so that each gets an even number of task resources.
The MRv1 Fair Scheduler allocates task resources based on available "slots". The maximum slots on a slave node is set in the configuration files. Administrators set those values based on the memory and cpu resources available for that system and taking into consideration the requirements of the average tasks run in that cluster. The JobTracker receives heartbeats to know the number of slots in use and available.
The YARN Fair Scheduler allocates containers to be used for tasks and containers are allocated based on available memory and/or vcores which are collectively called "resources". Each application may request a different amount of required resources. The maximum memory and vcores available for YARN on a particular system can be controlled in the config files by the administrator. An administrator may choose to reserve some memory or cpu resources for other processes such as HBase or Impala or even just for the local operating system. The Resource Manager receives heartbeats to know what resources are in use and available.
Fair scheduling is a method of assigning resources to applications such that all apps get, on average, an equal share of resources over time. Hadoop NextGen is capable of scheduling multiple resource types. By default, the Fair Scheduler bases scheduling fairness decisions only on memory. It can be configured to schedule with both memory and CPU, using the notion of Dominant Resource Fairness developed by Ghodsi et al. When there is a single app running, that app uses the entire cluster. When other apps are submitted, resources that free up are assigned to the new apps, so that each app eventually on gets roughly the same amount of resources. Unlike the default Hadoop scheduler, which forms a queue of apps, this lets short apps finish in reasonable time while not starving long-lived apps. It is also a reasonable way to share a cluster between a number of users. Finally, fair sharing can also work with app priorities - the priorities are used as weights to determine the fraction of total resources that each app should get.
The scheduler organizes apps further into "queues", and shares resources fairly between these queues. By default, all users share a single queue, named "default". If an app specifically lists a queue in a container resource request, the request is submitted to that queue. It is also possible to assign queues based on the user name included with the request through configuration. Within each queue, a scheduling policy is used to share resources between the running apps. The default is memory-based fair sharing, but FIFO and multi-resource with Dominant Resource Fairness can also be configured. Queues can be arranged in a hierarchy to divide resources and configured with weights to share the cluster in specific proportions.
In addition to providing fair sharing, the Fair Scheduler allows assigning guaranteed minimum shares to queues, which is useful for ensuring that certain users, groups or production applications always get sufficient resources. When a queue contains apps, it gets at least its minimum share, but when the queue does not need its full guaranteed share, the excess is split between other running apps. This lets the scheduler guarantee capacity for queues while utilizing resources efficiently when these queues don't contain applications.
Question : Each node in your Hadoop cluster, running YARN,
has 64GB memory and 24 cores. Your yarn.site.xml has
the following configuration:

1. A
2. B
3. Access Mostly Uused Products by 50000+ Subscribers
4. D
Correct Answer : Get Lastest Questions and Answer :
Exp: (64GB total RAM) / (16 # of Containers) = 4 GB minimum per Container
In a Hadoop cluster, its vital to balance the usage of RAM, CPU and disk so that processing is not constrained by any one of these cluster resources. As a general recommendation, we have found that allowing for 1-2 Containers per disk and per core gives the best balance for cluster utilization. So with our example cluster node with 12 disks and 12 cores, we will allow for 20 maximum Containers to be allocated to each node.
Each machine in our cluster has 48 GB of RAM. Some of this RAM should be reserved for Operating System usage. On each node, we will assign 40 GB RAM for YARN to use and keep 8 GB for the Operating System. The following property sets the maximum memory YARN can utilize on the node:
yarn-site.xml
name-->yarn.nodemanager.resource.memory-mb
value -->40960
The next step is to provide YARN guidance on how to break up the total resources available into Containers. You do this by specifying the minimum unit of RAM to allocate for a Container. We want to allow for a maximum of 20 Containers, and thus need (40 GB total RAM) / (20 # of Containers) = 2 GB minimum per container:
yarn-site.xml
name --> yarn.scheduler.minimum-allocation-mb
value -->2048
YARN will allocate Containers with RAM amounts greater than the yarn.scheduler.minimum-allocation-mb.
Question : YARN then provides processing capacity to each application by allocating Containers.
A Container is the basic unit of processing capacity in YARN, and is an encapsulation of resource elements
1. CPU
2. Memory
3. Access Mostly Uused Products by 50000+ Subscribers
4. Each Data Node of Hadoop Cluster
Correct Answer : Get Lastest Questions and Answer :
Explanation: YARN takes into account all the available compute resources on each machine in the cluster. Based on the available resources, YARN will negotiate resource requests from applications (such as MapReduce) running in the cluster. YARN then provides processing capacity to each application by allocating Containers. A Container is the basic unit of processing capacity in YARN, and is an encapsulation of resource elements (memory, cpu etc.).
Related Questions
Question : Your cluster is configured with HDFS and MapReduce version (MRv) on YARN. What is the result when
you execute: hadoop jar SampleJar MyClass on a client machine?

1. SampleJar.Jar is sent to the ApplicationMaster which allocates a container for SampleJar.Jar
2. Sample.jar is placed in a temporary directory in HDFS
3. Access Mostly Uused Products by 50000+ Subscribers
4. SampleJar.jar is serialized into an XML file which is submitted to the ApplicatoionMaster
Ans: 2
Exp : When a job is submitted to the cluster, it is placed in a temporary directory in HDFS and the JobTracker is notified of that location. The configuration for the job is serialized to an XML file, which is also placed in a directory in HDFS. Some jobs require you to specify the input and output directories on the command line, but this is not a Hadoop requirement.
Question : You are working on a project where you need to chain together MapReduce, Pig jobs. You also need the
ability to use forks, decision points, and path joins. Which ecosystem project should you use to perform these
actions?
1. Oozie
2. ZooKeeper
3. Access Mostly Uused Products by 50000+ Subscribers
4. Sqoop
5. HUE
Ans : 1
Exp : Oozie is a workflow system specifically built to work with Hadoop, MapReduce, and Pig job. An Oozie workflow is a collection of actions (i.e. Hadoop Map/Reduce jobs, Pig jobs) arranged in a control dependency DAG (Direct Acyclic Graph). "Control dependency" from one action to another means that the second action can't run until the first action has completed. Oozie workflows definitions are written in hPDL (a XML Process Definition Language similar to JBOSS JBPM jPDL). Users write workflows in an XML language that define one or more MapReduce jobs, their interdependencies, and what to do in the case of failures. These workflows are uploaded to the Oozie server where they are scheduled to run or executed immediately. When Oozie executes a MapReduce job as part of a workflow, it is run by the Oozie server, which keeps track of job-level failures and status.
Oozie workflow actions start jobs in remote systems (i.e. Hadoop, Pig). Upon action completion, the remote systems callback Oozie to notify the action completion, at this point Oozie proceeds to the next action in the workflow.
Question : Which process instantiates user code, and executes map and reduce tasks on a cluster running MapReduce v (MRv) on YARN?
1. NodeManager
2. ApplicationMaster
3. Access Mostly Uused Products by 50000+ Subscribers
4. JobTracker
5. NameNode
Ans : 2
Exp : ApplicationMaster : The ApplicationMaster is the master user job that manages all life-cycle aspects, including dynamically increasing and decreasing resources
consumption (i.e., containers), managing the flow of execution (e.g., in case of MapReduce jobs, running reducers against the output of maps), handling
faults and computation skew, and performing other local optimizations. The ApplicationMaster is designed to run arbitrary user code that can be written in
any programming language, as all communication with the ResourceManager and NodeManager is encoded using extensible network protocols (i.e.,
Google Protocol Buffers
ContainerAllocationExpirer
This component is in charge of ensuring that all allocated containers are eventually used by ApplicationMasters and subsequently launched on the
corresponding NodeManagers. ApplicationMasters run as untrusted user code and may potentially hold on to allocations without using them; as such, they
can lead to under-utilization and abuse of a clusters resources. To address this, the ContainerAllocationExpirer maintains a list of containers that are
allocated but still not used on the corresponding NodeManagers. For any container, if the corresponding NodeManager doesnt report to the
ResourceManager that the container has started running within a configured interval of time (by default, 10 minutes), the container is deemed dead and is
expired by the ResourceManager.
In addition, independently NodeManagers look at this expiry time, which is encoded in the ContainerToken tied to a container, and reject containers that
are submitted for launch after the expiry time elapses. Obviously, this feature depends on the system clocks being synchronized across the
ResourceManager and all NodeManagers in the system.
Question : Cluster Summary:
45 files and directories, 12 blocks = 57 total.
Heap size is 15.31 MB/193.38MB(7%)
Refer to the above screenshot.
You configure a Hadoop cluster with seven DataNodes and on of
your monitoring UIs displays the details
shown in the exhibit.
What does the this tell you?
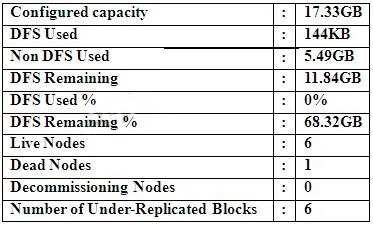
1. The DataNode JVM on one host is not active
2. Because your under-replicated blocks count matches the Live Nodes, one node is dead, and your DFS
Used % equals 0%, you can't be certain that your cluster has all the data you've written it.
3. Access Mostly Uused Products by 50000+ Subscribers
4. The HDFS cluster is in safe mode
Ans : 1
Exp : correct answer is 1. Because one node is shown as dead meaning that it is not connected to namenode and NN won't perform any writes to that DN. The command "hadoop dfsadmin -refrshNodes" might help bringing back the node to live.
Does the name-node stay in safe mode till all under-replicated files are fully replicated?
No. During safe mode replication of blocks is prohibited. The name-node awaits when all or majority of data-nodes report their blocks.
Depending on how safe mode parameters are configured the name-node will stay in safe mode until a specific percentage of blocks of the system is minimally replicated dfs.replication.min. If the safe mode threshold dfs.safemode.threshold.pct is set to 1 then all blocks of all files should be minimally replicated.
Minimal replication does not mean full replication. Some replicas may be missing and in order to replicate them the name-node needs to leave safe mode.
Refrence : http://wiki.apache.org/hadoop/FAQ
Question : Assuming a cluster running HDFS, MapReduce version (MRv) on YARN with all settings at their default,
what do you need to do when adding a new slave node to cluster?

1. Nothing, other than ensuring that the DNS (or/etc/hosts files on all machines) contains any entry for the new node.
2. Restart the NameNode and ResourceManager daemons and resubmit any running jobs.
3. Access Mostly Uused Products by 50000+ Subscribers
4. Restart the NameNode of dfs.number.of.nodes in hdfs-site.xml
Ans : 1
Exp : Dynamically adding a Slave Node
Configure slave1 node
Complete the previous steps on a to d for slave1 node for installing and configuring hadoop on slave node. And then proceed to the next step.
Configure slaves and includes file in Master Node (hadooplab)
Enter the slaves DNS name in both the files slaves and includes
hadooplab.bigdataleap.com
slave1.bigdataleap.com
Verify what all nodes are running under HDFS and YARN
Check yarn nodes running
yarn node -list -all
Check hdfs nodes running
hdfs dfsadmin -report
Refresh the slave dns names for allowing slave to join
hdfs dfsadmin -refreshNodes
yarn rmadmin -refreshNodes
Start the data node and node manager on slave1 machine
Go to $HADOOP_INSTALL/sbin directory and start both the following services
./hadoop-daemon.sh start datanode
./yarn-daemon.sh start nodemanager
Verify if the slave has joined the cluster
Check yarn nodes running
yarn node -list -all
Check hdfs nodes running
hdfs dfsadmin -report
Also verify usin the UI interface of both namenode and resource manager.
Question : Which YARN daemon or service negotiate map and reduce Containers from the Scheduler, tracking their
status and monitoring progress?
1. NodeManager
2. ApplicationMaster
3. Access Mostly Uused Products by 50000+ Subscribers
4. ResourceManager
Ans : 2
Exp : An ApplicationMaster for executing shell commands on a set of launched containers using the YARN framework.
This class is meant to act as an example on how to write yarn-based application masters.
The ApplicationMaster is started on a container by the ResourceManager's launcher. The first thing that the ApplicationMaster needs to do is to connect and register itself with the ResourceManager. The registration sets up information within the ResourceManager regarding what host:port the ApplicationMaster is listening on to provide any form of functionality to a client as well as a tracking url that a client can use to keep track of status/job history if needed. However, in the distributedshell, trackingurl and appMasterHost:appMasterRpcPort are not supported.
The ApplicationMaster needs to send a heartbeat to the ResourceManager at regular intervals to inform the ResourceManager that it is up and alive. The ApplicationMasterProtocol.allocate(org.apache.hadoop.yarn.api.protocolrecords.AllocateRequest) to the ResourceManager from the ApplicationMaster acts as a heartbeat.
For the actual handling of the job, the ApplicationMaster has to request the ResourceManager via AllocateRequest for the required no. of containers using ResourceRequest with the necessary resource specifications such as node location, computational (memory/disk/cpu) resource requirements. The ResourceManager responds with an AllocateResponse that informs the ApplicationMaster of the set of newly allocated containers, completed containers as well as current state of available resources.
For each allocated container, the ApplicationMaster can then set up the necessary launch context via ContainerLaunchContext to specify the allocated container id, local resources required by the executable, the environment to be setup for the executable, commands to execute, etc. and submit a StartContainerRequest to the ContainerManagementProtocol to launch and execute the defined commands on the given allocated container.
The ApplicationMaster can monitor the launched container by either querying the ResourceManager using ApplicationMasterProtocol.allocate(org.apache.hadoop.yarn.api.protocolrecords.AllocateRequest) to get updates on completed containers or via the ContainerManagementProtocol by querying for the status of the allocated container's ContainerId.
After the job has been completed, the ApplicationMaster has to send a FinishApplicationMasterRequest to the ResourceManager to inform it that the ApplicationMaster has been completed. Each Application Master is responsible for negotiating the appropriate resource containers from the scheduler, tracking their status, and monitoring their progress.
Question : During the execution of a MapReduce v (MRv) job on YARN, where does the Mapper place the intermediate
data of each Map Task?
1. The Mapper stores the intermediate data on the node running the Job's ApplicationMaster so that it is
available to YARN ShuffleService before the data is presented to the Reducer
2. The Mapper stores the intermediate data in HDFS on the node where the Map tasks ran in the HDFS /
usercache/&(user)/apache/application_&(appid) directory for the user who ran the job
3. Access Mostly Uused Products by 50000+ Subscribers
4. YARN holds the intermediate data in the NodeManager's memory (a container) until it is transferred to the
Reducer
5. The Mapper stores the intermediate data on the underlying filesystem of the local disk in the directories
yarn.nodemanager.local-dirs
Ans : 5
Exp : yarn.nodemanager.local-dirs : Comma-separated list of paths on the local filesystem where intermediate data is written. Multiple paths help spread disk i/o.
The local directory where MapReduce stores intermediate data files is specified by mapreduce.cluster.local.dir property. You can specify a comma-separated list of directories on different disks on the node in order to spread disk i/o. Directories that do not exist are ignored.
Question : On a cluster running CDH . or above, you use the hadoop fs -put command to write a MB file into a
previously empty directory using an HDFS block size of 64 MB. Just after this command has finished writing
200 MB of this file, what would another use see when they look in directory?
1. The directory will appear to be empty until the entire file write is completed on the cluster
2. They will see the file with a ._COPYING_ extension on its name. If they view the file, they will see contents
of the file up to the last completed block (as each 64MB block is written, that block becomes available)
3. Access Mostly Uused Products by 50000+ Subscribers
a ConcurrentFileAccessException until the entire file write is completed on the cluster
4. They will see the file with its original name. If they attempt to view the file, they will get a
ConcurrentFileAccessException until the entire file write is completed on the cluster
Ans : 2
Exp : FsShell copy/put creates staging files with '.COPYING' suffix. These files should be considered hidden by FileInputFormat. (A simple fix is to add the following conjunct to the existing hiddenFilter:
!name.endsWith("._COPYING_")
After upgrading to CDH 4.2.0 we encountered this bug. We have a legacy data loader which uses 'hadoop fs -put' to load data into hourly partitions. We also have intra-hourly jobs which are scheduled to execute several times per hour using the same hourly partition as input. Thus, as the new data is continuously loaded, these staging files (i.e., .COPYING) are breaking our jobs (since when copy/put completes staging files are moved).
As a workaround, we've defined a custom input path filter and loaded it with "mapred.input.pathFilter.class". Why are you running a Map/Reduce job with input from a directory that has not finished being copied? MR was not designed to run on data that is changing underneath it. When the job is done how do you know which of the input files were actually used to produce the output? This issue existed prior to 2.0 but was even worse without the .COPYING suffix. In those cases the files were opened in place and data started to be copied into them. You may have only even gotten a part of the file in your MR job, not all of it. The file could have disappeared out from under the MR job if an error occurred.
This is not behavior that I want to make a common park of Map/Reduce. If you want to do this and you know the risks then you can filter .COPYING files out of your list of input files to the MR job. But I don't want the framework to do it automatically for everyone.
As I've indicated above, we have jobs which execute as soon as new data is available for that (hdfs) partition. The external scheduler knows when new data has finished loading, namely when all pending hdfs 'put' operations complete.
(Think of it as a special type of job in the sense that it runs many times per hour, every time processing a superset of the input files.)
Your claim that MR was not designed to run on data that is changing underneath it seems rather putative. What is wrong with the above approach assuming that the intended semantics of 'put' is atomic transfer without (MR) observable side effect of .COPYING? (In other words, if MR is oblivious to .COPYING, then data it not changing underneath it.)
Question : Which command does Hadoop offer to discover missing or corrupt HDFS data?
1. Hdfs fs -u
2. Hdfs fsck
3. Access Mostly Uused Products by 50000+ Subscribers
4. The map-only checksum
5. Hadoop does not provide any tools to discover missing or corrupt data; there is not need because three
replicas are kept for each data block
Ans : 2
Exp :In its standard form, hadoop fsck / will return information about the cluster including the number of DataNodes and the number of under-replicated blocks.
To view a list of all the files in the cluster, the command would be hadoop fsck / -files
To view a list of all the blocks, and the locations of the blocks, the command would be hadoop fsck / -files -blocks -locations
Additionally, the -racks option would display the rack topology information for each block
You can use
hadoop fsck /
to determine which files are having problems. Look through the output for missing or corrupt blocks (ignore under-replicated blocks for now). This command is really verbose especially on a large HDFS filesystem so I normally get down to the meaningful output with
hadoop fsck / | egrep -v '^\.+$' | grep -v eplica
which ignores lines with nothing but dots and lines talking about replication.
Once you find a file that is corrupt
hadoop fsck /path/to/corrupt/file -locations -blocks -files
Use that output to determine where blocks might live. If the file is larger than your block size it might have multiple blocks.
You can use the reported block numbers to go around to the datanodes and the namenode logs searching for the machine or machines on which the blocks lived. Try looking for filesystem errors on those machines. Missing mount points, datanode not running, file system reformatted/reprovisioned. If you can find a problem in that way and bring the block back online that file will be healthy again.
Lather rinse and repeat until all files are healthy or you exhaust all alternatives looking for the blocks.
Once you determine what happened and you cannot recover any more blocks, just use the
hadoop fs -rm /path/to/file/with/permanently/missing/blocks
command to get your HDFS filesystem back to healthy so you can start tracking new errors as they occur.
Question : You are planning a Hadoop cluster and considering implementing Gigabit Ethernet as the network fabric.
Which workloads benefit the most from faster network fabric?
1. When your workload generates a large amount of output data, significantly larger than the amount of
intermediate data
2. When your workload consumes a large amount of input data, relative to the entire capacity if HDFS
3. Access Mostly Uused Products by 50000+ Subscribers
4. When your workload consists of processor-intensive tasks
5. When your workload generates a large amount of intermediate data, on the order of the input data itself
Ans : 4
Exp :
Question : Your cluster is running MapReduce version (MRv) on YARN. Your ResourceManager is configured to use
the FairScheduler. Now you want to configure your scheduler such that a new user on the cluster can submit
jobs into their own queue application submission. Which configuration should you set?
1. You can specify new queue name when user submits a job and new queue can be created dynamically if
the property yarn.scheduler.fair.allow-undecleared-pools = true
2. Yarn.scheduler.fair.user.fair-as-default-queue = false and yarn.scheduler.fair.allow- undecleared-pools =
true
3. Access Mostly Uused Products by 50000+ Subscribers
yarn .schedule.fair.user-as-default-queue = false
4. You can specify new queue name per application in allocations.xml file and have new jobs automatically
assigned to the application queue
Ans : 1
Exp : Properties that can be placed in yarn-site.xml
yarn.scheduler.fair.allocation.file ?Path to allocation file. An allocation file is an XML manifest describing queues and their properties, in addition to certain policy defaults. This file must be in the XML format described in the next section. If a relative path is given, the file is searched for on the classpath (which typically includes the Hadoop conf directory). Defaults to fair-scheduler.xml.
yarn.scheduler.fair.user-as-default-queue ?Whether to use the username associated with the allocation as the default queue name, in the event that a queue name is not specified. If this is set to "false" or unset, all jobs have a shared default queue, named "default". Defaults to true. If a queue placement policy is given in the allocations file, this property is ignored.
yarn.scheduler.fair.preemption ?Whether to use preemption. Note that preemption is experimental in the current version. Defaults to false.
yarn.scheduler.fair.sizebasedweight ?Whether to assign shares to individual apps based on their size, rather than providing an equal share to all apps regardless of size. When set to true, apps are weighted by the natural logarithm of one plus the app's total requested memory, divided by the natural logarithm of 2. Defaults to false.
yarn.scheduler.fair.assignmultiple ?Whether to allow multiple container assignments in one heartbeat. Defaults to false.
yarn.scheduler.fair.max.assign ?If assignmultiple is true, the maximum amount of containers that can be assigned in one heartbeat. Defaults to -1, which sets no limit.
yarn.scheduler.fair.locality.threshold.node ?For applications that request containers on particular nodes, the number of scheduling opportunities since the last container assignment to wait before accepting a placement on another node. Expressed as a float between 0 and 1, which, as a fraction of the cluster size, is the number of scheduling opportunities to pass up. The default value of -1.0 means don't pass up any scheduling opportunities.
yarn.scheduler.fair.locality.threshold.rack ?For applications that request containers on particular racks, the number of scheduling opportunities since the last container assignment to wait before accepting a placement on another rack. Expressed as a float between 0 and 1, which, as a fraction of the cluster size, is the number of scheduling opportunities to pass up. The default value of -1.0 means don't pass up any scheduling opportunities.
yarn.scheduler.fair.allow-undeclared-pools ?If this is true, new queues can be created at application submission time, whether because they are specified as the application's queue by the submitter or because they are placed there by the user-as-default-queue property. If this is false, any time an app would be placed in a queue that is not specified in the allocations file, it is placed in the "default" queue instead. Defaults to true. If a queue placement policy is given in the allocations file, this property is ignored.
Question : A slave node in your cluster has TB hard drives installed ( x TB). The DataNode is configured to store
HDFS blocks on all disks. You set the value of the dfs.datanode.du.reserved parameter to 100 GB. How does
this alter HDFS block storage?

1. 25GB on each hard drive may not be used to store HDFS blocks
2. 100GB on each hard drive may not be used to store HDFS blocks
3. Access Mostly Uused Products by 50000+ Subscribers
node
4. A maximum if 100 GB on each hard drive may be used to store HDFS blocks
null
Question : Which of the following responsibilities of JobTracker were splited in YARN architecture?
1. Resource Management
2. Job Monitoring
3. Data Distribution
4. 1 and 2
5. All 1, 2 and 3
Question : Cloudera distribution of CDH, is designed to work both MRv and YARN on the same nodes, but not the default Hadoop . by Apache Hadoop
1. True
2. False
3. True, you have to configure CDH5 while setup
4. False, MRv1 is not supported from Hadoop 2.0
Question : Which of the following is not supported in the CDH for HA ?
1. Quorum-based storage is the only supported HDFS HA
2. HA with NFS shared storage
3. Both 1 and 2
4. Both 1 and 2 are supported