Cloudera Hadoop Administrator Certification Certification Questions and Answer (Dumps and Practice Questions)
Question : You have GB of memory available in your cluster. The cluster's memory is shared between
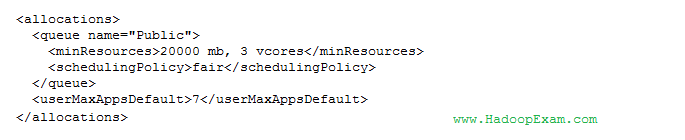
three different queues: public, manager and analyst. The following configuration file is also in place:
A job submitted to the public queue requires 10 GB, a job submitted to the maanger queue requires 30 GB,
and a job submitted to the analyst queue requires 25 GB. Given the above configuration,
how will the Fair Scheduler allocate resources for each queue?
1. 40 GB for Public queue, 0 GB for Manager queue and 0 GB for Analyst queue
2. 10 GB for Public queue, 30 GB for Manager queue and 0 GB for Analyst queue
3. Access Mostly Uused Products by 50000+ Subscribers
4. 20 GB for the Public queue, 10 GB for the Manager queue, and 10 GB for the Analyst queue
Correct Answer : Get Lastest Questions and Answer :
Fair scheduling is a method of assigning resources to applications such that all apps get, on average, an equal share of resources over time. Hadoop NextGen is capable of scheduling multiple resource types. By default, the Fair Scheduler bases scheduling fairness decisions only on memory. It can be configured to schedule with both memory and CPU, using the notion of Dominant Resource Fairness developed by Ghodsi et al. When there is a single app running, that app uses the entire cluster. When other apps are submitted, resources that free up are assigned to the new apps, so that each app eventually on gets roughly the same amount of resources. Unlike the default Hadoop scheduler, which forms a queue of apps, this lets short apps finish in reasonable time while not starving long-lived apps. It is also a reasonable way to share a cluster between a number of users. Finally, fair sharing can also work with app priorities - the priorities are used as weights to determine the fraction of total resources that each app should get.
The scheduler organizes apps further into "queues", and shares resources fairly between these queues. By default, all users share a single queue, named "default". If an app specifically lists a queue in a container resource request, the request is submitted to that queue. It is also possible to assign queues based on the user name included with the request through configuration. Within each queue, a scheduling policy is used to share resources between the running apps. The default is memory-based fair sharing, but FIFO and multi-resource with Dominant Resource Fairness can also be configured. Queues can be arranged in a hierarchy to divide resources and configured with weights to share the cluster in specific proportions.
In addition to providing fair sharing, the Fair Scheduler allows assigning guaranteed minimum shares to queues, which is useful for ensuring that certain users, groups or production applications always get sufficient resources. When a queue contains apps, it gets at least its minimum share, but when the queue does not need its full guaranteed share, the excess is split between other running apps. This lets the scheduler guarantee capacity for queues while utilizing resources efficiently when these queues don't contain applications.
The Fair Scheduler lets all apps run by default, but it is also possible to limit the number of running apps per user and per queue through the config file. This can be useful when a user must submit hundreds of apps at once, or in general to improve performance if running too many apps at once would cause too much intermediate data to be created or too much context-switching. Limiting the apps does not cause any subsequently submitted apps to fail, only to wait in the scheduler's queue until some of the user's earlier apps finish.
There are 40 GB available in the cluster. The public queue has a minimum share defined but demand is less than that minimum. The allocation of resources will not exceed the demand. The Manager and Analyst queues do not have any minimum share defined and will utilize, up to their demand, an even share of the remaining resources.
10 GB are allocated to Public queue to meet the demand. The remaining 30 GB are divided equally between Manager and Analyst's queues.
Question : You have configured the Fair Scheduler on your Hadoop cluster. You submit a Equity job so that ONLY job Equity is
running on the cluster. Equity Job requires more task resources than are available simultaneously on the cluster. Later you submit ETF job.
Now Equity and ETF are running on the cluster at the same time.
Identify aspects of how the Fair Scheduler will arbitrate cluster resources for these two jobs?
1. When job ETF gets submitted, it will be allocated task resources, while job Equity continues to run with fewer task resources available to it.
2. When job Equity gets submitted, it consumes all the task resources available on the cluster.
3. When job ETF gets submitted, job Equity has to finish first, before job ETF can be scheduled.
4. When job Equity gets submitted, it is not allowed to consume all the task resources on the cluster in case another job is submitted later.

1. 1,2,3
2. 2,3
3. Access Mostly Uused Products by 50000+ Subscribers
4. 1,2,4
5. 1,2
Correct Answer : Get Lastest Questions and Answer :
Explanation: The Fair Scheduler is designed to ensure that multiple jobs can run simultaneously on a cluster. If only one job is running on the cluster, it will consume as many task resources as it needs, up to the total capacity of the cluster. However, if another job is submitted, those jobs are then fair scheduled, so that each gets an even number of task resources.
The MRv1 Fair Scheduler allocates task resources based on available "slots". The maximum slots on a slave node is set in the configuration files. Administrators set those values based on the memory and cpu resources available for that system and taking into consideration the requirements of the average tasks run in that cluster. The JobTracker receives heartbeats to know the number of slots in use and available.
The YARN Fair Scheduler allocates containers to be used for tasks and containers are allocated based on available memory and/or vcores which are collectively called "resources". Each application may request a different amount of required resources. The maximum memory and vcores available for YARN on a particular system can be controlled in the config files by the administrator. An administrator may choose to reserve some memory or cpu resources for other processes such as HBase or Impala or even just for the local operating system. The Resource Manager receives heartbeats to know what resources are in use and available.
Fair scheduling is a method of assigning resources to applications such that all apps get, on average, an equal share of resources over time. Hadoop NextGen is capable of scheduling multiple resource types. By default, the Fair Scheduler bases scheduling fairness decisions only on memory. It can be configured to schedule with both memory and CPU, using the notion of Dominant Resource Fairness developed by Ghodsi et al. When there is a single app running, that app uses the entire cluster. When other apps are submitted, resources that free up are assigned to the new apps, so that each app eventually on gets roughly the same amount of resources. Unlike the default Hadoop scheduler, which forms a queue of apps, this lets short apps finish in reasonable time while not starving long-lived apps. It is also a reasonable way to share a cluster between a number of users. Finally, fair sharing can also work with app priorities - the priorities are used as weights to determine the fraction of total resources that each app should get.
The scheduler organizes apps further into "queues", and shares resources fairly between these queues. By default, all users share a single queue, named "default". If an app specifically lists a queue in a container resource request, the request is submitted to that queue. It is also possible to assign queues based on the user name included with the request through configuration. Within each queue, a scheduling policy is used to share resources between the running apps. The default is memory-based fair sharing, but FIFO and multi-resource with Dominant Resource Fairness can also be configured. Queues can be arranged in a hierarchy to divide resources and configured with weights to share the cluster in specific proportions.
In addition to providing fair sharing, the Fair Scheduler allows assigning guaranteed minimum shares to queues, which is useful for ensuring that certain users, groups or production applications always get sufficient resources. When a queue contains apps, it gets at least its minimum share, but when the queue does not need its full guaranteed share, the excess is split between other running apps. This lets the scheduler guarantee capacity for queues while utilizing resources efficiently when these queues don't contain applications.
Question : In the QuickTechie Inc. you have upgraded your Hadoop Cluster to MRv and in which you are
going to user FairScheduler. Using this scheduler you will which of the following benefit.
1. Run jobs at periodic times of the day.
2. Ensure data locality by ordering map tasks so that they run on data local map slots
3. Reduce job latencies in an environment with multiple jobs of different sizes.
4. Allow multiple users to share clusters in a predictable, policy-guided manner.
5. Reduce the total amount of computation necessary to complete a job.
6. Support the implementation of service-level agreements for multiple cluster users.
7. Allow short jobs to complete even when large, long jobs (consuming a lot of resources) are running.
1. 1,2,3,4
2. 2,4,5,7
3. Access Mostly Uused Products by 50000+ Subscribers
4. 3,4,6,7
5. 2,3,4,6
Correct Answer : Get Lastest Questions and Answer :
Fair scheduling is a method of assigning resources to applications such that all apps get, on average, an equal share of resources over time. Hadoop NextGen is capable of scheduling multiple resource types. By default, the Fair Scheduler bases scheduling fairness decisions only on memory. It can be configured to schedule with both memory and CPU, using the notion of Dominant Resource Fairness developed by Ghodsi et al. When there is a single app running, that app uses the entire cluster. When other apps are submitted, resources that free up are assigned to the new apps, so that each app eventually on gets roughly the same amount of resources. Unlike the default Hadoop scheduler, which forms a queue of apps, this lets short apps finish in reasonable time while not starving long-lived apps. It is also a reasonable way to share a cluster between a number of users. Finally, fair sharing can also work with app priorities - the priorities are used as weights to determine the fraction of total resources that each app should get.
The scheduler organizes apps further into "queues", and shares resources fairly between these queues. By default, all users share a single queue, named "default". If an app specifically lists a queue in a container resource request, the request is submitted to that queue. It is also possible to assign queues based on the user name included with the request through configuration. Within each queue, a scheduling policy is used to share resources between the running apps. The default is memory-based fair sharing, but FIFO and multi-resource with Dominant Resource Fairness can also be configured. Queues can be arranged in a hierarchy to divide resources and configured with weights to share the cluster in specific proportions.
In addition to providing fair sharing, the Fair Scheduler allows assigning guaranteed minimum shares to queues, which is useful for ensuring that certain users, groups or production applications always get sufficient resources. When a queue contains apps, it gets at least its minimum share, but when the queue does not need its full guaranteed share, the excess is split between other running apps. This lets the scheduler guarantee capacity for queues while utilizing resources efficiently when these queues don't contain applications.
The Fair Scheduler lets all apps run by default, but it is also possible to limit the number of running apps per user and per queue through the config file. This can be useful when a user must submit hundreds of apps at once, or in general to improve performance if running too many apps at once would cause too much intermediate data to be created or too much context-switching. Limiting the apps does not cause any subsequently submitted apps to fail, only to wait in the scheduler's queue until some of the user's earlier apps finish.
Related Questions
Question : You want to understand more about how users browse your public website. For example, you want to know
which pages they visit prior to placing an order. You have a server farm of 200 web servers hosting your
website. Which is the most efficient process to gather these web server across logs into your Hadoop cluster
analysis?
A. Sample the web server logs web servers and copy them into HDFS using curl
B. Ingest the server web logs into HDFS using Flume
C. Channel these clickstreams into Hadoop using Hadoop Streaming
D. Import all user clicks from your OLTP databases into Hadoop using Sqoop
E. Write a MapReeeduce job with the web servers for mappers and the Hadoop cluster nodes for reducers

1. A
2. B
3. Access Mostly Uused Products by 50000+ Subscribers
4. D
5. E
Question : You need to analyze ,, images stored in JPEG format, each of which is approximately KB.
Because you Hadoop cluster isn't optimized for storing and processing many small files, you decide to do the
following actions:
1. Group the individual images into a set of larger files
2. Use the set of larger files as input for a MapReduce job that processes them directly with python using
Hadoop streaming.
Which data serialization system gives the flexibility to do this?
A. CSV
B. XML
C. HTML
D. Avro
E. SequenceFiles
F. JSON
1. AB
2. AC
3. Access Mostly Uused Products by 50000+ Subscribers
4. CD
5. EF
Question : Identify two features/issues that YARN is designated to address:
A. Standardize on a single MapReduce API
B. Single point of failure in the NameNode
C. Reduce complexity of the MapReduce APIs
D. Resource pressure on the JobTracker
E. Ability to run framework other than MapReduce, such as MPI
F. HDFS latency
1. AB
2. AC
3. Access Mostly Uused Products by 50000+ Subscribers
4. CD
5. EF
Question : Which YARN daemon or service monitors and Controls per-application resource using (e.g., memory CPU)?
1. ApplicationMaster
2. NodeManager
3. Access Mostly Uused Products by 50000+ Subscribers
4. ResourceManager
Question : Which YARN process run as container of a submitted job and is responsible for resource qrequests?
1. ApplicationManager
2. JobTracker
3. Access Mostly Uused Products by 50000+ Subscribers
4. JobHistoryServer
5. ResoureManager
Question : Which scheduler would you deploy to ensure that your cluster allows short jobs to finish within a reasonable
time without starting long-running jobs?
1. Complexity Fair Scheduler (CFS)
2. Capacity Scheduler
3. Access Mostly Uused Products by 50000+ Subscribers
4. FIFO Scheduler