Cloudera Hadoop Developer Certification Questions and Answer (Dumps and Practice Questions)
Question : What are the core components of the Hadoop framework

1. HDFS (Hadoop Distributed File System)
2. MapReduce
3. Access Mostly Uused Products by 50000+ Subscribers
4. 1 nad 2 both are correct
Correct Answer : Get Lastest Questions and Answer :
Hadoop consists of two core components
- The Hadoop Distributed File System (HDFS)
- MapReduce
Question : Which project is the part of Hadoop Ecosystem ?
1. Pig
2. Hive
3. Access Mostly Uused Products by 50000+ Subscribers
4. 1 and 2
5. All of the above
Correct Answer : Get Lastest Questions and Answer :
There are many other projects based around core Hadoop
- Often referred to as the Hadoop Ecosystem
- Pig, Hive, HBase, Flume, Oozie, Sqoop, etc
- Many are discussed later in the course
Question : What is the possible data block size in hadoop
1. 64 MB
2. 128 MB
3. Access Mostly Uused Products by 50000+ Subscribers
4. Both 1 and 2 are correct
Correct Answer : Get Lastest Questions and Answer :
Data is split into blocks and distributed across multiple nodes in
the cluster
- Each block is typically 64Mb or 128Mb in size
Related Questions
Question :What is HBASE?

1. Hbase is separate set of the Java API for Hadoop cluster
2. Hbase is a part of the Apache Hadoop project that provides interface for scanning large amount of data using Hadoop infrastructure
3. Access Mostly Uused Products by 50000+ Subscribers
4. HBase is a part of the Apache Hadoop project that provides a SQL like interface for data processing.
Question :What is the role of the namenode?
1. Namenode splits big files into smaller blocks and sends them to different datanodes
2. Namenode is responsible for assigning names to each slave node so that they can be identified by the clients
3. Access Mostly Uused Products by 50000+ Subscribers
4. Both 2 and 3 are valid answers
Question : What happen on the namenode when a client tries to read a data file?
1. The namenode will look up the information about file in the edit file and then retrieve the remaining
information from filesystem memory snapshot
2. The namenode is not involved in the retrieving data file since the data is stored on datanodes
3. Access Mostly Uused Products by 50000+ Subscribers
4. None of these answers are correct
Ans : 1
Exp : Since the namenode needs to support a large number of the clients, the primary namenode will only send information back for the data location. The datanode itselt is responsible for the retrieval.
Question :What mode(s) can Hadoop code be run in?
1. Hadoop can be deployed in distributed mode only
2. Hadoop can be deployed in stand-alone mode or distributed mode
3. Access Mostly Uused Products by 50000+ Subscribers
4. None of these are applicable modes for Hadoop
Ans: 3
Exp : Hadoop was specifically designed to be deployed on multi-node cluster. However, it also can be deployed on single machine and as a single process for testing purposes.
Question :What is the role of the secondary namenode?
1. Secondary namenode is a backup namenode that will serve requests if primary namenode goes down
2. Secondary namenode performs CPU intensive operation of combining edit logs and current filesystem snapshots
3. Access Mostly Uused Products by 50000+ Subscribers
4. There is no secondary namenode
Ans : 2
Exp : The secondary namenode was separated out as a process due to having CPU intensive operations and additional requirements for metadata back-up.
Question :What are the side effects of not running a secondary name node?
1. The cluster performance will degrade over time since edit log will grow bigger and bigger
2. The primary namenode will become overloaded and response time be slower.
3. Access Mostly Uused Products by 50000+ Subscribers
4. The only possible impact is when there is an outage a failover to the secondary namenode will not occur. This is a rare occurence
Ans :1
Exp : If the secondary namenode is not running at all, the edit log will grow significantly and it will slow the system down. Also, the system will go into safemode for an extended time since the namenode needs to combine the edit log and the current filesystem checkpoint image.
Question :What happen if a datanode loses network connection for a few minutes?
1. The namenode will detect that a datanode is not responsive and will start replication of the data from remaining replicas. When datanode comes back online, administrator will need to manually delete the extra replicas
2. All data will be lost on that node. The administrator has to make sure the proper data distribution between nodes
3. Access Mostly Uused Products by 50000+ Subscribers
4. The namenode will detect that a datanode is not responsive and will start replication of the data from remaining replicas. When datanode comes back online, the extra replicas will be deleted
Ans : 4
Exp : The replication factor is actively maintained by the namenode. The namenode monitors the status of all datanodes and keeps track which blocks are located on that node. The moment the datanode is not avaialble it will trigger replication of the data from the existing replicas. However, if the datanode comes back up, overreplicated data will be deleted. Note: the data might be deleted from the original datanode.
Question :What happen if one of the datanodes has much slower CPU? How will it effect the performance of the cluster?
1. The task execution will be as fast as the slowest worker.
However, if speculative execution is enabled, the slowest worker will not have such big impact
2. The slowest worker will significantly impact job execution time. It will slow everything down
3. Access Mostly Uused Products by 50000+ Subscribers
4. It depends on the level of priority assigned to the task. All high priority tasks are executed in parallel twice. A slower datanode would therefore be bypassed. If task is not high priority, however, performance will be affected.
Ans : 1
Exp : Hadoop was specifically designed to work with commodity hardware. The speculative execution helps to offset the slow workers. The multiple instances of the same task will be created and job tracker will take the first result into consideration and the second instance of the task will be killed
Question :
If you have a file 128M size and replication factor is set to 3, how many blocks can you find on the cluster that will correspond to that file (assuming the default apache and cloudera configuration)?
1. 3
2. 6
3. Access Mostly Uused Products by 50000+ Subscribers
4. 12
Ans : 2
Exp : Based on the configuration settings the file will be divided into multiple blocks according to the default block size of 64M. 128M / 64M = 2 . Each block will be replicated according to replication factor settings (default 3). 2 * 3 = 6 .
Question :
What is replication factor?
1. Replication factor controls how many times the namenode replicates its metadata
2. Replication factor creates multiple copies of the same file to be served to clients
3. Access Mostly Uused Products by 50000+ Subscribers
4. None of these answers are correct.
Ans : 3
Exp : Data is replicated in the Hadoop cluster based on the replication factor. The high replication factor guarantees data availability in the event of failure.
Question :
What daemons run on Master nodes?
1. NameNode, DataNode, JobTracker and TaskTracker
2. NameNode, DataNode and JobTracker
3. Access Mostly Uused Products by 50000+ Subscribers
4. NameNode, Secondary NameNode, JobTracker, TaskTracker and DataNode
Ans : 3
Exp : Hadoop is comprised of five separate daemons and each of these daemon run in its own JVM. NameNode, Secondary NameNode and JobTracker run on Master nodes. DataNode and TaskTracker run on each Slave nodes.
Question :
What is the role of the jobtracker in an Hadoop cluster?
1. The jobtracker is responsible for scheduling tasks on slave nodes, collecting results, retrying failed tasks
2. The job tracker is responsible for job monitoring on the cluster, sending alerts to master nodes
3. Access Mostly Uused Products by 50000+ Subscribers
4. Both 1 and 3 are valid answers
Ans :1
Exp : The job tracker is the main component of the map-reduce execution. It control the division of the job into smaller tasks, submits tasks to individual tasktracker, tracks the progress of the jobs and reports results back to calling code
Question :
How does the Hadoop cluster tolerate datanode failures?
1. Failures are anticipated. When they occur, the jobs are re-executed.
2. Datanodes talk to each other and figure out what need to be re-replicated if one of the nodes goes down
3. Access Mostly Uused Products by 50000+ Subscribers
4. Since Hadoop is design to run on commodity hardware, the datanode failures are expected. Namenode keeps track of all available datanodes and actively maintains replication factor on all data.
Ans : 4
Exp : The namenode actively tracks the status of all datanodes and acts immediately if the datanodes become non-responsive. The namenode is the central "brain" of the HDFS and starts replication of the data the moment a disconnect is detected.
Question :
In the Reducer, the MapReduce API has an iterator over writable values. Calling the next() method
1. Returns a reference to a different Writable object each time.
2. Returns a reference to a writable object from an object pool.
3. Access Mostly Uused Products by 50000+ Subscribers
4. Returns a reference to a same writable object if the next value is the same as the previous value,or a new writable object otherwise.
Question :
When is the Reduce Method is called in a MapReduce Job ?
1. reducers start copying immediate key-value pairs from each mappers as soon as it has completed. The reduce method is called only after
all intermediate data has been copied and sorted.
2. Reduce methods and Map methods all start at the beginning of a Job, in order to provide optimal performance for map-only or reduce only job.
3. Access Mostly Uused Products by 50000+ Subscribers
as the intermdiate key-value pairs atart to arrive.
4. It depends on the configuration which is done in JobConf object
Ans :1
Question :
What types of algorithms are difficult to express as MapReduce
1. Large scale graph algorithm
2. When data needs to be shared among the node
3. Access Mostly Uused Products by 50000+ Subscribers
4. For text Analysis on large web data
Ans 3
Exp : Hadoop was designed to run on a large number of machines that dont share memory or disks, like the shared-nothing model. All processing would be done in self contained units within the cluster, communicating over a common network but sharing no computing resources. The software breaks large datasets in smaller pieces and spreads it across the different servers. You run a job by querying each of the servers in the cluster, which compile the data and deliver it back to you, leveraging each servers processing power
Question :
you have written a Mapper which invokes the following calls to the outputcollector.collect() :
output.collect(new Text("Square"), new Text("Red");
output.collect(new Text("Circle"), new Text("Yellow");
output.collect(new Text("Square"), new Text("Yellow");
output.collect(new Text("Trangle"), new Text("Red");
output.collect(new Text("square"), new Text("Green");
How many times it is going to call reduce method.
1. 2
2. 3
3. Access Mostly Uused Products by 50000+ Subscribers
4. 5
Ans : 4
Exp : Here small s intentionally used.
Question :
While writing a combiner which takes as Input Text keys, IntWritable values and emits Text as a key and IntWritable values Which interface requires to be implemeted
1. Reducer ( Text, IntWritable,Text, IntWritable )
2. Mapper ( Text, IntWritable,Text, IntWritable )
3. Combiner ( Text, IntWritable,Text, IntWritable)
4. Reducer (Text, IntWritable,Text, Text )
1. 1
2. 2
3. Access Mostly Uused Products by 50000+ Subscribers
4. 4
Ans :1
Question :
There is a hadoop cluster with the 10 Data Nodes, each with a single 10 TB hard drive, and it utilizes all disk capacity for HDFS,
no space for MapReduce, with replication setting as 3 what is the storage capacity for full cluster.
1. 10 TB
2. 20 TB
3. Access Mostly Uused Products by 50000+ Subscribers
4. It can be between 10 TB to 30 TB
Ans : 3
Question :
Which of the following tool, defines a SQL like language..
1. Pig
2. Hive
3. Access Mostly Uused Products by 50000+ Subscribers
4. Flume
Ans 2
Question :
Which of the following is correct for TextInputFormat class ..
1. An InputFormat for plain text files. Files are broken into lines.
Either linefeed or carriage-return are used to signal end of line. Keys are the position in the file, and values are the line of text..
2. It can also work for binary file
3. Access Mostly Uused Products by 50000+ Subscribers
4. It is unable to find the end of the line.
Ans :1
Question :
What reducer emit..
1. Finale key-value pairs as configured in JobConf object
2. One final key value pair based per input key
3. Access Mostly Uused Products by 50000+ Subscribers
4. None of the above
Ans : 2
Question :
Hadoop framework provides a mechanism for copying with machine issues such as faulty configuration or impeding hardware failure. MapReduce detects
that one or a number of machines are performing poorly and starts more copies of a map or reduce task. all the task run simulteneously
and the task taht finishes first are used. Which term describe this behaviour..
1. Partitioning
2. Cobining
3. Access Mostly Uused Products by 50000+ Subscribers
4. Speculative Execution
Ans : 4
Question :
By using hadoop fs -put command to write a 500 MB file using 64 MB blcok, but while the file is half written, can other user read the already written block
1. It will throw an exception
2. File block would be accessible which are already written
3. Access Mostly Uused Products by 50000+ Subscribers
4. Until the whole file is copied nothing can be accessible.
Ans :4
Exp : While writing the file of 528MB size using following command
hadoop fs -put tragedies_big4 /user/training/shakespeare/
We tried to read the file using following command and output is below.
[hadoopexam@localhost ~]$ hadoop fs -cat /user/training/shakespeare/tragedies_big4 cat: "/user/training/shakespeare/tragedies_big4": No such file or directory [hadoopexam@localhost ~]$ hadoop fs -cat /user/training/shakespeare/tragedies_big4 cat: "/user/training/shakespeare/tragedies_big4": No such file or directory [training@localhost ~]$ hadoop fs -cat /user/training/shakespeare/tragedies_big4 cat: "/user/training/shakespeare/tragedies_big4": No such file or directory [training@localhost ~]$
Once the put command finishes then only we are able to "cat" this file.
Question :
What happens when keys and values passed to the reducers during standard sort and shuffle phase of MapReduce ?
1. Keys are presented to the reducer in sorted order.
2. Keys and Values both are presented in sorted order.
3. Access Mostly Uused Products by 50000+ Subscribers
4. Keys and values both are presented in Random Order.
Ans : 1
Question :
In which scenerio MapReduce is not suitable..
1. text mining on the unstructured documents
2. Analyzing web documents
3. Access Mostly Uused Products by 50000+ Subscribers
4. for a large computation of finacial risk modeling and performance analysis.
Ans : 3
Question :
What is a BloomFilter
1. It is a data structure
2. A bloom filter is a compect representation of a set that support only conatin query.
3. Access Mostly Uused Products by 50000+ Subscribers
4. All of the above
Question :
Which statement is true with respect to MapReduce 2.0 or YARN

1. It is the newer version of MapReduce, using this performance of the data processing can be increased.
2. The fundamental idea of MRv2 is to split up the two major functionalities of the JobTracker,
resource management and job scheduling or monitoring, into separate daemons.
3. Access Mostly Uused Products by 50000+ Subscribers
4. All of the above
5. Only 2 and 3 are correct
Ans : 5
Exp : MapReduce has undergone a complete overhaul in hadoop-0.23 and we now have, what we call, MapReduce 2.0 (MRv2) or YARN.
The fundamental idea of MRv2 is to split up the two major functionalities of the JobTracker,
resource management and job scheduling or monitoring, into separate daemons. The idea is to have a global ResourceManager (RM)
and per-application ApplicationMaster (AM). An application is either a single job in the classical sense of Map-Reduce jobs or a DAG of jobs.
Question : Which is the component of the ResourceManager

1. 1. Scheduler
2. 2. Applications Manager
3. Access Mostly Uused Products by 50000+ Subscribers
4. 4. All of the above
5. Only 1 and 2 are correct
Ans : 5
Exp : The ResourceManager has two main components: Scheduler and ApplicationsManager.
The Scheduler is responsible for allocating resources to the various running applications subject to familiar constraints of capacities,
queues etc. The Scheduler is pure scheduler in the sense that it performs no monitoring or tracking of status for the application.
Question :
Schduler of Resource Manager guarantees about restarting failed tasks either due to application failure or hardware failures.
1. True
2. False
1. True
2. False
Ans : 2
Exp : The Scheduler is responsible for allocating resources to the various running applications subject to familiar constraints of
capacities, queues etc. The Scheduler is pure scheduler in the sense that it performs no monitoring or tracking of status
for the application. Also, it offers no guarantees about restarting failed tasks either due to application failure or hardware
failures. The Scheduler performs its scheduling function based the resource requirements of the applications;
it does so based on the abstract notion of a resource Container which incorporates elements such as memory,
cpu, disk, network etc.
Question :
Which statement is true about ApplicationsManager
1. is responsible for accepting job-submissions
2. negotiating the first container for executing the application specific ApplicationMaster
and provides the service for restarting the ApplicationMaster container on failure.
3. Access Mostly Uused Products by 50000+ Subscribers
4. All of the above
5. 1 and 2 are correct
Ans : 5
Exp : The ApplicationsManager is responsible for accepting job-submissions,
negotiating the first container for executing the application specific ApplicationMaster and provides the
service for restarting the ApplicationMaster container on failure.
Question :
Which java class represent a directory or file to get the metadata information e.g BlockSizw, replication factor, ownership and permission etc.
1. FileSystem
2. FileStatus
3. Access Mostly Uused Products by 50000+ Subscribers
4. FileDirectory
5. 1 and 2 are correct
Ans : 2
Question :
Which is Parent abstract class of HDFS Filesystem
1. org.apache.hadoop.fs.AbstractFileSystem
2. org.apache.hadoop.fs.FileSystem
3. Access Mostly Uused Products by 50000+ Subscribers
4. org.apache.hadoop.fs.ItFileSystem
Ans : 2
Question :
What is the default value of dfs.replication in case of pseudo distributed cluster..
1. 1
2. 2
3. Access Mostly Uused Products by 50000+ Subscribers
4. 0
Ans : 1
Question :
NameNode store block locations persistently ?
1. True
2. Flase
Ans : 2
Exp : NameNode does not store block locations persistently, since this information is reconstructed from datanodes when system starts.
Question :
Which tool is used to list all the blocks of a file ?
1. hadoop fs
2. hadoop fsck
3. Access Mostly Uused Products by 50000+ Subscribers
4. Not Possible
Ans : 2
Question : HDFS can not store a file which size is greater than one node disk size :
1. True
2. False
Ans : 2
Exp : It can store because it is divided in block and block can be stored anywhere..
Question : When is the earliest point at which the reduce method of a given Reducer can be called?
1. As soon as at least one mapper has finished processing its input split.
2. As soon as a mapper has emitted at least one record.
3. Access Mostly Uused Products by 50000+ Subscribers
4. It depends on the InputFormat used for the job.
Ans : 3
Exp : In a MapReduce job reducers do not start executing the reduce method until the all Map
jobs have completed. You can customize when the reducers startup by changing the default value of
mapred.reduce.slowstart.completed.maps in mapred-site.xml. A value of 1.00 will wait
for all the mappers to finish before starting the reducers. A value of 0.0 will start the
reducers right away. A value of 0.5 will start the reducers when half of the mappers are
complete. You can also change mapred.reduce.slowstart.completed.maps on a job-byjob
basis.
Typically, keep mapred.reduce.slowstart.completed.maps above 0.9 if the system ever
has multiple jobs running at once. This way the job doesn't hog up reducers when they
aren't doing anything but copying data. If you only ever have one job running at a time,
doing 0.1 would probably be appropriate.
Question :Which describes how a client reads a file from HDFS?
1. The client queries the NameNode for the block locations. The NameNode returns
the block locations to the client. The client reads the data directory off the
DataNodes.
2. The client queries all DataNodes in parallel. The DataNode that contains the
requested data responds directly to the client. The client reads the data directly off the
DataNode.
3. Access Mostly Uused Products by 50000+ Subscribers
queries the DataNodes for block locations. The DataNodes respond to the NameNode,
and the NameNode redirects the client to the DataNode that holds the requested data
blocks. The client then reads the data directly off the DataNode.
4. The client contacts the NameNode for the block locations. The NameNode contacts
the DataNode that holds the requested data block. Data is transferred from the DataNode
to the NameNode, and then from the NameNode to the client.
Ans : 1
Exp : The Client communication to HDFS happens using Hadoop HDFS API. Client
applications talk to the NameNode whenever they wish to locate a file, or when they
want to add or copy or move ordelete a file on HDFS. The NameNode responds the successful
requests by returning a list of relevant DataNode servers where the data lives. Client
applications can talk directly to a DataNode, once the NameNode has provided the
location of the data.
Question : You are developing a combiner that takes as input Text keys, IntWritable values, and
emits Text keys, IntWritable values. Which interface should your class implement?
1. Combiner {Text, IntWritable, Text, IntWritable}
2. Mapper {Text, IntWritable, Text, IntWritable}
3. Access Mostly Uused Products by 50000+ Subscribers
4. Reducer {Text, IntWritable, Text, IntWritable}
5. Combiner {Text, Text, IntWritable, IntWritable}
Ans : 4
Question : Indentify the utility that allows you to create and run MapReduce jobs with any
executable or script as the mapper and/or the reducer?
1. Oozie
2. Sqoop
3. Access Mostly Uused Products by 50000+ Subscribers
4. Hadoop Streaming
5. mapred
Ans : 4
Question : How are keys and values presented and passed to the reducers during a standard sort and
shuffle phase of MapReduce?
1. Keys are presented to reducer in sorted order; values for a given key are not sorted.
2. Keys are presented to reducer in sorted order; values for a given key are sorted in
ascending order.
3. Access Mostly Uused Products by 50000+ Subscribers
sorted.
4. Keys are presented to a reducer in random order; values for a given key are sorted in
ascending order.
Ans : 1
Explanation:
Reducer has 3 primary phases:
1.Shuffle
The Reducer copies the sorted output from each Mapper using HTTP across the
network.
2.Sort
The framework merge sorts Reducer inputs by keys (since different Mappers may have
output the same key).
The shuffle and sort phases occur simultaneously i.e. while outputs are being fetched
they are merged.
SecondarySort
To achieve a secondary sort on the values returned by the value iterator, the application
should extend the key with the secondary key and define a grouping comparator. The
keys will be sorted using the entire key, but will be grouped using the grouping
comparator to decide which keys and values are sent in the same call to reduce.
3. Access Mostly Uused Products by 50000+ Subscribers
In this phase the reduce(Object, Iterable, Context) method is called for each {key,
(collection of values)}in the sorted inputs.
The output of the reduce task is typically written to a RecordWriter via
TaskInputOutputContext.write(Object, Object).
The output of the Reducer is not re-sorted.
Reference:
org.apache.hadoop.mapreduce,Class
Reducer{KEYIN,VALUEIN,KEYOUT,VALUEOUT}
Question : You wrote a map function that throws a runtime exception when it encounters a control
character in input data. The input supplied to your mapper contains twelve such
characters totals, spread across five file splits. The first four file splits each have two
control characters and the last split has four control characters. Indentify the number of
failed task attempts you can expect when you run the job with
mapred.max.map.attempts set to 4
1. You will have forty-eight failed task attempts
2. You will have seventeen failed task attempts
3. Access Mostly Uused Products by 50000+ Subscribers
4. You will have twelve failed task attempts
5. You will have twenty failed task attempts
Ans : 5
There will be four failed task attempts for each of the five file splits.
Question : You want to populate an associative array in order to perform a map-side join. You’ve decided
to put this information in a text file, place that file into the DistributedCache and read it in your
Mapper before any records are processed.
Indentify which method in the Mapper you should use to implement code for reading the file and
populating the associative array?
1. combine
2. map
3. Access Mostly Uused Products by 50000+ Subscribers
4. configure
Ans : 4
Question : You are running a job that will process a single InputSplit on a cluster which has no other jobs
currently running. Each node has an equal number of open Map slots. On which node will Hadoop first attempt to run the Map task?
1. The node with the most memory
2. The node with the lowest system load
3. Access Mostly Uused Products by 50000+ Subscribers
4. The node with the most free local disk space
Ans : 3
Exp : Hadoop tries data localization processing, it means whenever there is a possibility JobTracker will
try to start the task where data block is available.
Question : Assuming default settings, which best describes the order of data provided to a reducer’s
reduce method
1. The keys given to a reducer aren’t in a predictable order, but the values associated with those
keys always are.
2. Both the keys and values passed to a reducer always appear in sorted order.
3. Access Mostly Uused Products by 50000+ Subscribers
4. The keys given to a reducer are in sorted order but the values associated with each key are in
no predictable order
Ans : 4
Exp :
Question : In a MapReduce job which process millions of input records and generated the same amount of key-value pairs (In millions).
The data is not uniformly distributed. Hence MapReduce job is going to create a significant
amount of intermediate data that it needs to transfer between mappers and reduces which is a potential
bottleneck. A custom implementation of which interface is most likely to reduce the amount of
intermediate data transferred across the network?
1. Partitioner
2. OutputFormat
3. Access Mostly Uused Products by 50000+ Subscribers
4. Combiner
Ans : 4
Exp : Using the combiner (Which is genrally same code as Reducer) we can reduce the transfer of data over the
network during shuffle step.
Question : Joining of two large datasets in MapReduce is possible like RDBMS tables sharing a key? Assume that the
two datasets are in CSV format stored in HDFS.
1. Yes
2. Yes, but only if one of the tables fits into memory
3. Access Mostly Uused Products by 50000+ Subscribers
4. No, MapReduce cannot perform relational operations.
5. No, but it can be done with either Pig or Hive.
Ans : 1
Exp :Yes, it is possible to join large datasets in Hadoop MapReduce, there are various approaches available for
Joining the data in MapReduce e.g. Map-Side, Reduce-side and using Distributed Cache etc.
Question : You have just executed a MapReduce job. Where is intermediate data written to after being emitted from the
Mapper's map method?
1. Intermediate data in streamed across the network from Mapper to the Reduce and is never written to disk
2. Into in-memory buffers on the TaskTracker node running the Mapper that spill over and are written into HDFS.
3. Access Mostly Uused Products by 50000+ Subscribers
4. Into in-memory buffers that spill over to the local file system (outside HDFS) of the TaskTracker node running the Reducer
5. Into in-memory buffers on the TaskTracker node running the Reducer that spill over and are written into HDFS.
Ans : 3
Exp :The mapper output (intermediate data) is stored on the Local file system (NOT HDFS) of each individual
mapper nodes. This is typically a temporary directory location which can be setup in config by the hadoop
administrator. The intermediate data is cleaned up after the Hadoop Job completes
Question : You want to understand more about how users browse your public website, such as which pages they visit
prior to placing an order. You have a farm of 200 web servers hosting your website. How will you gather this
data for your analysis?
1. Ingest the server web logs into HDFS using Flume.
2. Write a MapReduce job, with the web servers for mappers, and the Hadoop cluster nodes for reduces.
3. Access Mostly Uused Products by 50000+ Subscribers
4. Channel these clickstreams inot Hadoop using Hadoop Streaming.
5. Sample the weblogs from the web servers, copying them into Hadoop using curl.
Ans : 1
Exp :Hadoop MapReduce for Parsing Weblogs
Here are the steps for parsing a log file using Hadoop MapReduce:
Load log files into the HDFS location using this Hadoop command:
hadoop fs -put (local file path of weblogs) (hadoop HDFS location) The Opencsv2.3.jar framework is used
for parsing log records.
Below is the Mapper program for parsing the log file from the HDFS location.
public static class ParseMapper
extends Mapper(Object, Text, NullWritable,Text ){
private Text word = new Text();
public void map(Object key, Text value, Context context ) throws IOException, InterruptedException {
CSVParser parse = new CSVParser(' ','\"');
String sp[]=parse.parseLine(value.toString());
int spSize=sp.length;
StringBuffer rec= new StringBuffer();
for(int i=0;i lessthan spSize;i++){
rec.append(sp[i]);
if(i!=(spSize-1))
rec.append(",");
}
word.set(rec.toString());
context.write(NullWritable.get(), word);
}}
The command below is the Hadoop-based log parse execution. TheMapReduce program is attached in this
article. You can add extra parsing methods in the class. Be sure to create a new JAR with any change and
move it to the Hadoop distributed job tracker system.
hadoop jar (path of logparse jar) (hadoop HDFS logfile path) (output path of parsed log file) The output file
is stored in the HDFS location, and the output file name starts with "part-".
Question : You need to run the same job many times with minor variations. Rather than hardcoding all job configuration
options in your drive code, you've decided to have your Driver subclass org.apache.hadoop.conf.Configured
and implement the org.apache.hadoop.util.Tool interface.
Indentify which invocation correctly passes.mapred.job.name with a value of Example to Hadoop?
1. hadoop "mapred.job.name=Example" MyDriver input output
2. hadoop MyDriver mapred.job.name=Example input output
3. Access Mostly Uused Products by 50000+ Subscribers
4. hadoop setproperty mapred.job.name=Example MyDriver input output
5. hadoop setproperty ("mapred.job.name=Example") MyDriver input output
Ans : 3
Exp :Configure the property using the -D key=value notation:
-D mapred.job.name='My Job'
You can list a whole bunch of options by calling the streaming jar with just the -info argument
Python hadoop streaming : Setting a job name
Question : You are developing a MapReduce job for sales reporting. The mapper will process input keys representing the
year (IntWritable) and input values representing product indentifies (Text).
Indentify what determines the data types used by the Mapper for a given job.
1. The key and value types specified in the JobConf.setMapInputKeyClass and JobConf.setMapInputValuesClass methods
2. The data types specified in HADOOP_MAP_DATATYPES environment variable
3. Access Mostly Uused Products by 50000+ Subscribers
4. The InputFormat used by the job determines the mapper's input key and value types.
Ans : 4
Exp :
The input types fed to the mapper are controlled by the InputFormat used. The default input format,
"TextInputFormat," will load data in as (LongWritable, Text) pairs. The long value is the byte offset of the line in
the file. The Text object holds the string contents of the line of the file.
Note:The data types emitted by the reducer are identified by setOutputKeyClass() andsetOutputValueClass().
The data types emitted by the reducer are identified by setOutputKeyClass() and setOutputValueClass().
By default, it is assumed that these are the output types of the mapper as well. If this is not the case, the
methods setMapOutputKeyClass() and setMapOutputValueClass() methods of the JobConf class will override
these.
Question : Identify the MapReduce v (MRv / YARN) daemon responsible for launching application containers and
monitoring application resource usage?
1. ResourceManager
2. NodeManager
3. Access Mostly Uused Products by 50000+ Subscribers
4. ApplicationMasterService
5. TaskTracker.
Ans : 3
Exp :The fundamental idea of MRv2(YARN)is to split up the two major functionalities of the JobTracker, resource
management and job scheduling/monitoring, into separate daemons. The idea is to have a global
ResourceManager (RM) and per-application ApplicationMaster (AM). An application is either a single job in the
classical sense of Map-Reduce jobs or a DAG of jobs.
Question : For each input key-value pair, mappers can emit:
1. As many intermediate key-value pairs as designed. There are no restrictions on the types of those keyvalue
pairs (i.e., they can be heterogeneous).
2. As many intermediate key-value pairs as designed, but they cannot be of the same type as the input keyvalue pair.
3. Access Mostly Uused Products by 50000+ Subscribers
4. One intermediate key-value pair, but of the same type.
5. As many intermediate key-value pairs as designed, as long as all the keys have the same types and all the
values have the same type.
Ans : 5
Exp : Mapper maps input key/value pairs to a set of intermediate key/value pairs.
Maps are the individual tasks that transform input records into intermediate records. The transformed
intermediate records do not need to be of the same type as the input records. A given input pair may map to
zero or many output pairs.
Question : You have the following key-value pairs as output from your Map task:
(the, 1)
(fox, 1)
(faster, 1)
(than, 1)
(the, 1)
(dog, 1)
How many keys will be passed to the Reducer's reduce method?
1. Six
2. Five
3. Access Mostly Uused Products by 50000+ Subscribers
4. Two
5. One
Ans : 2
Exp :
Question : You have user profile records in your OLPT database, that you want to join with web logs you have already
ingested into the Hadoop file system. How will you obtain these user records?
1. HDFS command
2. Pig LOAD command
3. Access Mostly Uused Products by 50000+ Subscribers
4. Hive LOAD DATA command
5. Ingest with Flume agents
Ans : 3
Exp :Apache Hadoop and Pig provide excellent tools for extracting and analyzing data from very large Web logs.
We use Pig scripts for sifting through the data and to extract useful information from the Web logs.
We load the log file into Pig using the LOAD command.
raw_logs = LOAD 'apacheLog.log' USING TextLoader AS (line:chararray);
Note 1:
Data Flow and Components
*Content will be created by multiple Web servers and logged in local hard discs. This content will then be pushed to HDFS using FLUME framework.
FLUME has agents running on Web servers; these are machines that collect data intermediately using collectors and finally push that data to HDFS.
*Pig Scripts are scheduled to run using a job scheduler (could be cron or any sophisticated batch job solution). These scripts actually analyze
the logs on various dimensions and extract the results. Results from Pig are by default inserted into HDFS, but we can use storage implementation
for other repositories also such as HBase, MongoDB, etc. We have also tried the solution with HBase (please see the implementation section). Pig
Scripts can either push this data to HDFS and then MR jobs will be required to read and push this data into HBase, or Pig scripts can push this data into HBase directly. In this article, we use scripts to push data onto HDFS, as we are showcasing the Pig framework applicability for log analysis at large scale. *The database HBase will have the data processed by Pig scripts ready for reporting and further slicing and dicing. *The data-access Web service is a REST-based service that eases the access and integrations with data clients. The client can be in any language to access REST-based API. These clients could be BI- or UI-based
clients.
Note 2:
The Log Analysis Software Stack
*Hadoop is an open source framework that allows users to process very large data in parallel. It's based on the framework that supports Google search engine. The Hadoop core is mainly divided into two modules: 1.HDFS is the Hadoop Distributed File System. It allows you to store large amounts of data using multiple
commodity servers connected in a cluster. 2.Map-Reduce (MR) is a framework for parallel processing of large data sets. The default implementation is
bonded with HDFS. *The database can be a NoSQL database such as HBase. The advantage of a NoSQL database is that it provides scalability for the reporting module as well, as we can keep historical processed data for reporting purposes. HBase is an open source columnar DB or NoSQL DB, which uses HDFS. It can also use MR jobs to process data. It gives real-time, random read/write access to very large data sets -- HBase can save very large tables having million of rows. It's a distributed database and can also keep multiple versions of a single row. *The Pig framework is an open source platform for analyzing large data sets and is implemented as a layered language over the Hadoop Map-Reduce framework. It is built to ease the work of developers who write code in the Map-Reduce format, since code in Map-Reduce format needs to be written in Java. In contrast, Pig enables users to write code in a scripting language. *Flume is a distributed, reliable and available service for collecting, aggregating and moving a large amount of log data (src flume-wiki). It was built to push large logs into Hadoop-HDFS for further processing. It's a data flow solution, where there is an originator and destination for each node and is divided into Agent and Collector tiers for collecting logs and pushing them to destination storage.
Question : What is the disadvantage of using multiple reducers with the default HashPartitioner and distributing your
workload across you cluster?
1. You will not be able to compress the intermediate data.
2. You will longer be able to take advantage of a Combiner.
3. Access Mostly Uused Products by 50000+ Subscribers
4. There are no concerns with this approach. It is always advisable to use multiple reduces.
Ans : 3
Exp :your sort job runs with multiple reducers (either because mapreduce.job.reduces in mapred- site.xml has
been set to a number larger than 1, or because you've used the -r option to specify the number of reducers on
the command-line), then by default Hadoop will use the HashPartitioner to distribute records across the
reducers. Use of the HashPartitioner means that you can't concatenate your output files to create a single
sorted output file. To do this you'll need total ordering,
Question : Given a directory of files with the following structure: line number, tab character, string:
Example:
1abialkjfjkaoasdfjksdlkjhqweroij
2kadfjhuwqounahagtnbvaswslmnbfgy
3kjfteiomndscxeqalkzhtopedkfsikj
You want to send each line as one record to your Mapper. Which InputFormat should you use to complete the
line: conf.setInputFormat (____.class) ; ?
1. SequenceFileAsTextInputFormat
2. SequenceFileInputFormat
3. Access Mostly Uused Products by 50000+ Subscribers
4. BDBInputFormat
Ans : 3
Exp :KeyValueTextInputFormat
TextInputFormats keys, being simply the offset within the file, are not normally very useful.It is
common for each line in a file to be a key value pair, separated by
a delimiter such as a tab character. For exammple, this is ths output produced by TextOutputFormat.
Hadoop File System defaul output format. To interpret such files correctly, KeyValueTextInputFormat
is appropriate.
You can specify the separator via the mapreduce.input.keyvaluelinerecordreader.key.value.separator
property or key.value.separator.in.input.line in the old API
It is a tab character by default. Consider the following input file, where space represent a horizontal
tab character
line1 On the top of the Crumpetty Tree
line2 The Quangle Wangle sat,
line3 But his face you could not see,
line4 On account of his Beaver Hat.
Like in the TextInputFormat case, the input is in a single split comprising four records,although this
time the keys are the Text sequences before the tab in each line:
(line1, On the top of the Crumpetty Tree)
(line2, The Quangle Wangle sat,)
(line3, But his face you could not see,)
(line4, On account of his Beaver Hat.)
SequenceFileInputFormat
To use data from sequence files as the input to MapReduce, you use SequenceFileInputFormat. The
keys and values are determined by the sequence file, and you need to
make sure that your map input types correspond
Question : For each intermediate key, each reducer task can emit:
1. As many final key-value pairs as desired. There are no restrictions on the types of those key- value pairs (i.
e., they can be heterogeneous).
2. As many final key-value pairs as desired, but they must have the same type as the intermediate key-value
pairs.
3. Access Mostly Uused Products by 50000+ Subscribers
have the same type.
4. One final key-value pair per value associated with the key; no restrictions on the type.
5. One final key-value pair per key; no restrictions on the type.
Ans : 3
Exp :Reducer reduces a set of intermediate values which share a key to a smaller set of values.
Reducing lets you aggregate values together. A reducer function receives an iterator of input values from an
input list. It then combines these values together, returning a single output value.
Question : What data does a Reducer reduce method process?
1. All the data in a single input file.
2. All data produced by a single mapper.
3. Access Mostly Uused Products by 50000+ Subscribers
4. All data for a given value, regardless of which mapper(s) produced it.
Ans : 3
Exp :Reducing lets you aggregate values together. A reducer function receives an iterator of input values from an
input list. It then combines these values together, returning a single output value.
All values with the same key are presented to a single reduce task.
Question : All keys used for intermediate output from mappers must:
1. Implement a splittable compression algorithm
2. Be a subclass of FileInputFormat.
3. Access Mostly Uused Products by 50000+ Subscribers
4. Override isSplitable.
5. Implement a comparator for speedy sorting.
Ans : 3
Exp :The MapReduce framework operates exclusively on (key, value) pairs, that is, the framework views the
input to the job as a set of (key, value) pairs and produces a set of (key, value) pairs as the output of the job,
conceivably of different types.
The key and value classes have to be serializable by the framework and hence need to implement the
Writable interface. Additionally, the key classes have to implement the WritableComparable interface to
facilitate sorting by the framework.
Question : On a cluster running MapReduce v (MRv), a TaskTracker heartbeats into the JobTracker on your cluster,
and alerts the JobTracker it has an open map task slot.
What determines how the JobTracker assigns each map task to a TaskTracker?
1. The amount of RAM installed on the TaskTracker node.
2. The amount of free disk space on the TaskTracker node.
3. Access Mostly Uused Products by 50000+ Subscribers
4. The average system load on the TaskTracker node over the past fifteen (15) minutes.
5. The location of the InsputSplit to be processed in relation to the location of the node.
Ans : 5
Exp :The TaskTrackers send out heartbeat messages to the JobTracker, usually every few minutes, to reassure
the JobTracker that it is still alive. These message also inform the JobTracker of the number of available slots,
so the JobTracker can stay up to date with where in the cluster work can be delegated. When the JobTracker
tries to find somewhere to schedule a task within the MapReduce operations, it first looks for an empty slot on
the same server that hosts the DataNode containing the data, and if not, it looks for an empty slot on a
machine in the same rack.
Question : A client application creates an HDFS file named foo.txt with a replication factor of . Identify which best
describes the file access rules in HDFS if the file has a single block that is stored on data nodes A, B and C?
1. The file will be marked as corrupted if data node B fails during the creation of the file.
2. Each data node locks the local file to prohibit concurrent readers and writers of the file.
3. Access Mostly Uused Products by 50000+ Subscribers
4. Each data node stores a copy of the file in the local file system with the same name as the HDFS file.
5. The file can be accessed if at least one of the data nodes storing the file is available.
Ans : 5
Exp :HDFS keeps three copies of a block on three different datanodes to protect against true data corruption.
HDFS also tries to distribute these three replicas on more than one rack to protect against data availability
issues. The fact that HDFS actively monitors any failed datanode(s) and upon failure detection immediately
schedules re-replication of blocks (if needed) implies that three copies of data on three different nodes is
sufficient to avoid corrupted files.
Note:
HDFS is designed to reliably store very large files across machines in a large cluster. It stores each file as a
sequence of blocks; all blocks in a file except the last block are the same size. The blocks of a file are
replicated for fault tolerance. The block size and replication factor are configurable per file. An application can
specify the number of replicas of a file. The replication factor can be specified at file creation time and can be
changed later. Files in HDFS are write-once and have strictly one writer at any time. The NameNode makes all
decisions regarding replication of blocks. HDFS uses rack-aware replica placement policy. In default
configuration there are total 3 copies of a datablock on HDFS, 2 copies are stored on datanodes on same rack
and 3rd copy on a different rack.
Question : Which process describes the lifecycle of a Mapper?
1. The JobTracker calls the TaskTracker's configure () method, then its map () method and finally its close () method.
2. The TaskTracker spawns a new Mapper to process all records in a single input split.
3. Access Mostly Uused Products by 50000+ Subscribers
4. The JobTracker spawns a new Mapper to process all records in a single file.
Ans : 3
Exp :For each map instance that runs, the TaskTracker creates a new instance of your mapper.
Note:
*The Mapper is responsible for processing Key/Value pairs obtained from the InputFormat. The mapper may
perform a number of Extraction and Transformation functions on the Key/Value pair before ultimately
outputting none, one or many Key/Value pairs of the same, or different Key/Value type.
*With the new Hadoop API, mappers extend the org.apache.hadoop.mapreduce.Mapper class. This class
defines an 'Identity' map function by default - every input Key/Value pair obtained from the InputFormat is
written out.
Examining the run() method, we can see the lifecycle of the mapper:
/**
* Expert users can override this method for more complete control over the
* execution of the Mapper.
* @param context
* @throws IOException
*/
public void run(Context context) throws IOException, InterruptedException { setup(context);
while (context.nextKeyValue()) {
map(context.getCurrentKey(), context.getCurrentValue(), context); }
cleanup(context);
}
setup(Context) - Perform any setup for the mapper. The default implementation is a no-op method. map(Key,
Value, Context) - Perform a map operation in the given Key / Value pair. The default implementation calls
Context.write(Key, Value)
cleanup(Context) - Perform any cleanup for the mapper. The default implementation is a no-op method.
Question : To process input key-value pairs, your mapper needs to lead a MB data file in memory. What is the best
way to accomplish this?
1. Serialize the data file, insert in it the JobConf object, and read the data into memory in the configure method of the mapper.
2. Place the data file in the DistributedCache and read the data into memory in the map method of the mapper.
3. Access Mostly Uused Products by 50000+ Subscribers
4. Place the data file in the DistributedCache and read the data into memory in the configure method of the mapper.
Ans : 4
Exp :Hadoop has a distributed cache mechanism to make available file locally that may be needed by Map/
Reduce jobs Use Case
Lets understand our Use Case a bit more in details so that we can follow-up the code snippets. We have a
Key-Value file that we need to use in our Map jobs. For simplicity, lets say we need to replace all keywords
that we encounter during parsing, with some other value.
So what we need is A key-values files (Lets use a Properties files)
The Mapper code that uses the code Write the Mapper code that uses it view source
public class DistributedCacheMapper extends Mapper(LongWritable, Text, Text, Text) {
Properties cache;
protected void setup(Context context) throws IOException, InterruptedException {
super.setup(context);
Path[] localCacheFiles = DistributedCache.getLocalCacheFiles(context.getConfiguration());
if(localCacheFiles != null) {
// expecting only single file here
for (int i = 0; i lessthan localCacheFiles.length; i++) {
Path localCacheFile = localCacheFiles[i];
cache = new Properties();
cache.load(new FileReader(localCacheFile.toString()));
}} else {
// do your error handling here
}}
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// use the cache here
// if value contains some attribute, cache.get(value)
// do some action or replace with something else
}}
Note:
* Distribute application-specific large, read-only files efficiently.
DistributedCache is a facility provided by the Map-Reduce framework to cache files (text, archives, jars etc.)
needed by applications.
Applications specify the files, via urls (hdfs:// or http://) to be cached via the JobConf. The DistributedCache
assumes that the files specified via hdfs:// urls are already present on the FileSystem at the path specified by
the url.
Question : In a MapReduce job, the reducer receives all values associated with same key. Which statement best
describes the ordering of these values?
1. The values are in sorted order.
2. The values are arbitrarily ordered, and the ordering may vary from run to run of the same MapReduce job.
3. Access Mostly Uused Products by 50000+ Subscribers
4. Since the values come from mapper outputs, the reducers will receive contiguous sections of sorted values.
Ans : 2
Exp :*Input to the Reducer is the sorted output of the mappers. *The framework calls the application's Reduce
function once for each unique key in the sorted order.
*Example:
For the given sample input the first map emits:
(Hello, 1)
( World, 1)
( Bye, 1)
( World, 1)
The second map emits:
( Hello, 1)
( Hadoop, 1)
( Goodbye, 1)
( Hadoop, 1)
Question : You need to create a job that does frequency analysis on input data. You will do this by writing a Mapper that
uses TextInputFormat and splits each value (a line of text from an input file) into individual characters. For
each one of these characters, you will emit the character as a key and an InputWritable as the value. As this
will produce proportionally more intermediate data than input data, which two resources should you expect to
be bottlenecks?
1. Processor and network I/O
2. Disk I/O and network I/O
3. Access Mostly Uused Products by 50000+ Subscribers
4. Processor and disk I/O
Ans : 2
Question : You want to count the number of occurrences for each unique word in the supplied input data. You've decided
to implement this by having your mapper tokenize each word and emit a literal value 1, and then have your
reducer increment a counter for each literal 1 it receives. After successful implementing this, it occurs to you
that you could optimize this by specifying a combiner. Will you be able to reuse your existing Reduces as your
combiner in this case and why or why not?
1. Yes, because the sum operation is both associative and commutative and the input and output types to the
reduce method match.
2. No, because the sum operation in the reducer is incompatible with the operation of a Combiner.
3. Access Mostly Uused Products by 50000+ Subscribers
4. No, because the Combiner is incompatible with a mapper which doesn't use the same data type for both
the key and value.
5. Yes, because Java is a polymorphic object-oriented language and thus reducer code can be reused as a
combiner.
Ans : 1
Exp :Combiners are used to increase the efficiency of a MapReduce program. They are used to aggregate
intermediate map output locally on individual mapper outputs. Combiners can help you reduce the amount of
data that needs to be transferred across to the reducers. You can useyour reducer code as a combiner if the
operation performed is commutative and associative. The execution of combiner is not guaranteed, Hadoop
may or may not execute a combiner. Also, if required it may execute it more then 1 times. Therefore your
MapReduce jobs should not depend on the combiners execution.
Question : Your client application submits a MapReduce job to your Hadoop cluster. Identify the Hadoop daemon on
which the Hadoop framework will look for an available slot schedule a MapReduce operation.
1. TaskTracker
2. NameNode
3. Access Mostly Uused Products by 50000+ Subscribers
4. JobTracker
5. Secondary NameNode
Ans : 4
Exp : JobTracker is the daemon service for submitting and tracking MapReduce jobs in Hadoop. There is only One
Job Tracker process run on any hadoop cluster. Job Tracker runs on its own JVM process. In a typical
production cluster its run on a separate machine. Each slave node is configured with job tracker node location.
The JobTracker is single point of failure for the Hadoop MapReduce service. If it goes down, all running jobs
are halted. JobTracker in Hadoop performs following actions(from Hadoop Wiki:)
Client applications submit jobs to the Job tracker.
The JobTracker talks to the NameNode to determine the location of the data The JobTracker locates
TaskTracker nodes with available slots at or near the data The JobTracker submits the work to the chosen
TaskTracker nodes. The TaskTracker nodes are monitored. If they do not submit heartbeat signals often
enough, they are deemed to have failed and the work is scheduled on a different TaskTracker. A TaskTracker
will notify the JobTracker when a task fails. The JobTracker decides what to do then: it may resubmit the job
elsewhere, it may mark that specific record as something to avoid, and it may may even blacklist the
TaskTracker as unreliable. When the work is completed, the JobTracker updates its status.
Client applications can poll the JobTracker for information.
Question : Which project gives you a distributed, Scalable, data store that allows you random, realtime read/write access
to hundreds of terabytes of data?
1. HBase
2. Hue
3. Access Mostly Uused Products by 50000+ Subscribers
4. Hive
5. Oozie
Ans : 1
Exp : Use Apache HBase when you need random, realtime read/write access to your Big Data.
This HBase goal is the hosting of very large tables
- billions of rows X millions of columns
- atop clusters of commodity hardware. Apache HBase is an open-source, distributed, versioned, columnoriented
store modeled after Google's Bigtable:
- A Distributed Storage System for Structured Data. Just as Bigtable leverages the distributed data storage provided by the Google File System, Apache HBase provides Bigtable-like capabilities on top of Hadoop and HDFS.
Features of HBases
- Linear and modular scalability.
- Strictly consistent reads and writes.
- Automatic and configurable sharding of tables
- Automatic failover support between RegionServers.
- Convenient base classes for backing Hadoop MapReduce jobs with Apache HBase tables.
- Easy to use Java API for client access.
- Block cache and Bloom Filters for real-time queries.
- Query predicate push down via server side Filters
- Thrift gateway and a REST-ful Web service that supports XML, Protobuf, and binary data encoding options
- Extensible jruby-based (JIRB) shell
- Support for exporting metrics via the Hadoop metrics subsystem to files or Ganglia; or via JMX
Question : Identify the tool best suited to import a portion of a relational database every day as files into HDFS, and
generate Java classes to interact with that imported data?
1. Oozie
2. Flume
3. Access Mostly Uused Products by 50000+ Subscribers
4. Hue
5. Sqoop
Ans : 5
Exp :Sqoop ("SQL-to-Hadoop") is a straightforward command-line tool with the following capabilities:
Imports individual tables or entire databases to files in HDFS Generates Java classes to allow you to interact
with your imported data Provides the ability to import from SQL databases straight into your Hive data
warehouse
Data Movement Between Hadoop and Relational Databases
Data can be moved between Hadoop and a relational database as a bulk data transfer, or relational tables can
be accessed from within a MapReduce map function.
Note:
* Cloudera's Distribution for Hadoop provides a bulk data transfer tool (i.e., Sqoop) that imports individual
tables or entire databases into HDFS files. The tool also generates Java classes that support interaction with
the imported data. Sqoop supports all relational databases over JDBC, and Quest Software provides a
connector (i.e., OraOop) that has been optimized for access to data residing in Oracle databases.
Question : You have a directory named jobdata in HDFS that contains four files: _first.txt, second.txt, .third.txt and #data.
txt. How many files will be processed by the FileInputFormat.setInputPaths () command when it's given a path
object representing this directory?
1. Four, all files will be processed
2. Three, the pound sign is an invalid character for HDFS file names
3. Access Mostly Uused Products by 50000+ Subscribers
4. None, the directory cannot be named jobdata
5. One, no special characters can prefix the name of an input file
Ans : 3
Exp :Files starting with '_' are considered 'hidden' like unix files startingwith '.'.
# characters are allowed in HDFS file names.
Question : You write MapReduce job to process files in HDFS. Your MapReduce algorithm uses TextInputFormat:
the mapper applies a regular expression over input values and emits key-values pairs with the key consisting
of the matching text, and the value containing the filename and byte offset. Determine the difference between
setting the number of reduces to one and settings the number of reducers to zero.
1. There is no difference in output between the two settings.
2. With zero reducers, no reducer runs and the job throws an exception. With one reducer, instances of
matching patterns are stored in a single file on HDFS.
3. Access Mostly Uused Products by 50000+ Subscribers
reducer, instances of matching patterns are stored in multiple files on HDFS.
4. With zero reducers, instances of matching patterns are stored in multiple files on HDFS. With one reducer,
all instances of matching patterns are gathered together in one file on HDFS.
Ans : 4
Exp :It is legal to set the number of reduce-tasks to zero if no reduction is desired.
In this case the outputs of the map-tasks go directly to the FileSystem, into the output path set by
setOutputPath(Path). The framework does not sort the map-outputs before writing them out to the FileSystem.
*Often, you may want to process input data using a map function only. To do this, simply set mapreduce.job.
reduces to zero. The MapReduce framework will not create any reducer tasks. Rather, the outputs of the
mapper tasks will be the final output of the job.
Reduce
In this phase the reduce(WritableComparable, Iterator, OutputCollector, Reporter) method is called for each
(key, (list of values)) pair in the grouped inputs.
The output of the reduce task is typically written to the FileSystem via OutputCollector.collect
(WritableComparable, Writable).
Applications can use the Reporter to report progress, set application-level status messages and update
Counters, or just indicate that they are alive.
The output of the Reducer is not sorted.
Question : In a MapReduce job with map tasks, how many map task attempts will there be?
1. It depends on the number of reduces in the job.
2. Between 500 and 1000.
3. Access Mostly Uused Products by 50000+ Subscribers
4. At least 500.
5. Exactly 500.
Ans : 4
Exp :
Task attempt is a particular instance of an attempt to execute a task ?
There will be at least as many task attempts as there are tasks
If a task attempt fails, another will be started by the JobTracker Speculative
execution can also result in more task attempts than completed tasks
Question : What types of algorithms are difficult to express in MapReduce v (MRv)?
1. Algorithms that require applying the same mathematical function to large numbers of individual binary records.
2. Relational operations on large amounts of structured and semi-structured data.
3. Access Mostly Uused Products by 50000+ Subscribers
4. Large-scale graph algorithms that require one-step link traversal.
5. Text analysis algorithms on large collections of unstructured text (e.g, Web crawls).
Ans : 3
Exp :
Limitations of Mapreduce whhere not to use Mapreduce
While very powerful and applicable to a wide variety of problems, MapReduce is not the answer to every
problem. Here are some problems I found where MapReudce is not suited and some papers that address the
limitations of MapReuce.
1. Computation depends on previously computed values
If the computation of a value depends on previously computed values, then MapReduce cannot be used. One
good example is the Fibonacci series where each value is summation of the previous two values. i.e., f(k+2) =
f(k+1) + f(k). Also, if the data set is small enough to be computed on a single machine, then it is better to do it
as a single reduce(map(data)) operation rather than going through the entire map reduce process.
2. Full-text indexing or ad hoc searching
The index generated in the Map step is one dimensional, and the Reduce step must not generate a large
amount of data or there will be a serious performance degradation. For example, CouchDB's MapReduce may
not be a good fit for full-text indexing or ad hoc searching. This is a problem better suited for a tool such as
Lucene.
3. Access Mostly Uused Products by 50000+ Subscribers
Solutions to many interesting problems in text processing do not require global synchronization. As a result,
they can be expressed naturally in MapReduce, since map and reduce tasks run independently and in
isolation. However, there are many examples of algorithms that depend crucially on the existence of shared
global state during processing, making them difficult to implement in MapReduce (since the single opportunity
for global synchronization in MapReduce is the barrier between the map and reduce phases of processing)
Question : In the reducer, the MapReduce API provides you with an iterator over Writable values. What does calling the
next () method return?
1. It returns a reference to a different Writable object time.
2. It returns a reference to a Writable object from an object pool.
3. Access Mostly Uused Products by 50000+ Subscribers
4. It returns a reference to a Writable object. The API leaves unspecified whether this is a reused object or a
new object.
5. It returns a reference to the same Writable object if the next value is the same as the previous value, or a
new Writable object otherwise.
Ans : 3
Exp :Calling Iterator.next() will always return the SAME EXACT instance of IntWritable, with the contents of that
instance replaced with the next value. manupulating iterator in mapreduce
Question : Table metadata in Hive is:
1. Stored as metadata on the NameNode.
2. Stored along with the data in HDFS.
3. Access Mostly Uused Products by 50000+ Subscribers
4. Stored in ZooKeeper.
Ans : 3
Exp :
By default, hive use an embedded Derby database to store metadata information. The metastore is the "glue"
between Hive and HDFS. It tells Hive where your data files live in HDFS, what type of data they contain, what
tables they belong to, etc.
The Metastore is an application that runs on an RDBMS and uses an open source ORM layer called
DataNucleus, to convert object representations into a relational schema and vice versa. They chose this
approach as opposed to storing this information in hdfs as they need the Metastore to be very low latency. The
DataNucleus layer allows them to plugin many different RDBMS technologies.
*By default, Hive stores metadata in an embedded Apache Derby database, and other client/server databases
like MySQL can optionally be used.
*features of Hiveinclude:
Metadata storage in an RDBMS, significantly reducing the time to perform semantic checks during query
execution.
Store Hive Metadata into RDBMS
Question : Analyze each scenario below and indentify which best describes the behavior of the default partitioner?
1. The default partitioner assigns key-values pairs to reduces based on an internal random number
generator.
2. The default partitioner implements a round-robin strategy, shuffling the key-value pairs to each reducer in
turn. This ensures an event partition of the key space.
3. Access Mostly Uused Products by 50000+ Subscribers
with different buckets, and each bucket is assigned to a specific reducer.
4. The default partitioner computers the hash of the key and divides that valule modulo the number of
reducers. The result determines the reducer assigned to process the key-value pair.
5. The default partitioner computers the hash of the value and takes the mod of that value with the number of
reducers. The result determines the reducer assigned to process the key-value pair.
Ans : 4
Exp :
The default partitioner computes a hash value for the key and assigns the partition based on this result.
The default Partitioner implementation is called HashPartitioner. It uses the hashCode() method of the key
objects modulo the number of partitions total to determine which partition to send a given (key, value) pair to.
In Hadoop, the default partitioner is HashPartitioner, which hashes a record's key to determine which partition
(and thus which reducer) the record belongs in.The number of partition is then equal to the number of reduce
tasks for the job.
Question : You need to move a file titled "weblogs" into HDFS. When you try to copy the file, you can't. You know you
have ample space on your DataNodes. Which action should you take to relieve this situation and store more
files in HDFS?
1. Increase the block size on all current files in HDFS.
2. Increase the block size on your remaining files.
3. Access Mostly Uused Products by 50000+ Subscribers
4. Increase the amount of memory for the NameNode.
5. Increase the number of disks (or size) for the NameNode.
Ans : 3
Exp :
*-put localSrc destCopies the file or directory from the local file system identified by localSrc to dest within the DFS.
*What is HDFS Block size? How is it different from traditional file system block size? In HDFS data is split into
blocks and distributed across multiple nodes in the cluster. Each block is typically 64Mb or 128Mb in size.
Each block is replicated multiple times. Default is to replicate each block three times. Replicas are stored on
different nodes. HDFS utilizes the local file system to store each HDFS block as a separate file. HDFS Block
size can not be compared with the traditional file system block size.
Question : In a large MapReduce job with m mappers and n reducers, how many distinct copy operations will there be in
the sort/shuffle phase?
1. mXn (i.e., m multiplied by n)
2. n
3. Access Mostly Uused Products by 50000+ Subscribers
4. m+n (i.e., m plus n)
5. E.mn(i.e., m to the power of n)
Ans : 1
Exp :A MapReduce job withm mappers and r reducers involves up to m*r distinct copy operations, since
eachmapper may have intermediate output going to every reducer.
Question : Workflows expressed in Oozie can contain:
1. Sequences of MapReduce and Pig. These sequences can be combined with other actions including forks,
decision points, and path joins.
2. Sequences of MapReduce job only; on Pig on Hive tasks or jobs. These MapReduce sequences can be
combined with forks and path joins.
3. Access Mostly Uused Products by 50000+ Subscribers
handlers but no forks.
4. Iterntive repetition of MapReduce jobs until a desired answer or state is reached.
Ans : 1
Exp :
Oozie workflow is a collection of actions (i.e. Hadoop Map/Reduce jobs, Pig jobs) arranged in a control
dependency DAG (Direct Acyclic Graph), specifying a sequence of actions execution. This graph is specified
in hPDL (a XML Process Definition Language). hPDL is a fairly compact language, using a limited amount of
flow control and action nodes. Control nodes define the flow of execution and include beginning and end of a
workflow (start, end and fail nodes) and mechanisms to control the workflow execution path ( decision, fork
and join nodes).
Workflow definitions Currently running workflow instances, including instance states and variables
Oozie is a Java Web-Application that runs in a Java servlet-container - Tomcat and uses a database to store
Question : Which best describes what the map method accepts and emits?
1. It accepts a single key-value pair as input and emits a single key and list of corresponding values as output.
2. It accepts a single key-value pairs as input and can emit only one key-value pair as output.
3. Access Mostly Uused Products by 50000+ Subscribers
4. It accepts a single key-value pairs as input and can emit any number of key-value pair as output, including zero.
Ans : 4
Exp :
public class Mapper(KEYIN,VALUEIN,KEYOUT,VALUEOUT)
extends Object
Maps input key/value pairs to a set of intermediate key/value pairs.
Maps are the individual tasks which transform input records into a intermediate records. The transformed
intermediate records need not be of the same type as the input records. A given input pair may map to zero or
many output pairs.
Question : When can a reduce class also serve as a combiner without affecting the output of a MapReduce program?
1. When the types of the reduce operation's input key and input value match the types of the reducer's output
key and output value and when the reduce operation is both communicative and associative.
2. When the signature of the reduce method matches the signature of the combine method.
3. Access Mostly Uused Products by 50000+ Subscribers
4. Always. The point of a combiner is to serve as a mini-reducer directly after the map phase to increase
performance.
5. Never. Combiners and reducers must be implemented separately because they serve different purposes.
Ans : 1
Exp : You can use your reducer code as a combiner if the operation performed is commutative and associative.
Question : You want to perform analysis on a large collection of images. You want to store this data in HDFS and process
it with MapReduce but you also want to give your data analysts and data scientists the ability to process the
data directly from HDFS with an interpreted high-level programming language like Python. Which format
should you use to store this data in HDFS?
1. SequenceFiles
2. Avro
3. Access Mostly Uused Products by 50000+ Subscribers
4. HTML
5. XML
Ans : 1
Exp :So what should we do in order to deal with huge amount of images? Use hadoop sequence files! Those are
map files that inherently can be read by map reduce applications ?there is an input format especially for
sequence files ?and are splitable by map reduce, so we can have one huge file that will be the input of many
map tasks.
By using those sequence files we are letting hadoop use its advantages. It can split the work into
chunks so the processing is parallel, but the chunks are big enough that the process stays efficient.
Since the sequence file are map file the desired format will be that the key will be text and hold the HDFS
filename and the value will be BytesWritable and will contain the image content of the file.
Hadoop binary files processing introduced by image duplicates finder
Question : You want to run Hadoop jobs on your development workstation for testing before you submit them to your
production cluster. Which mode of operation in Hadoop allows you to most closely simulate a production
cluster while using a single machine?
1. Run all the nodes in your production cluster as virtual machines on your development workstation
2. Run the hadoop command with the local and the .s file:///options
3. Access Mostly Uused Products by 50000+ Subscribers
4. Run simldooop, the Apache open-source software for simulating Hadoop clusters
Ans : 1
Exp :
As well as large-scale cloud infrastructures, there is another deployment pattern: local VMs on desktop
systems or other development machines. This is a good tactic if your physical machines run windows and you
need to bring up a Linux system running Hadoop, and/or you want to simulate the complexity of a small
Hadoop cluster.
Have enough RAM for the VM to not swap.
Don't try and run more than one VM per physical host, it will only make things slower. use file: URLs to access
persistent input and output data. consider making the default filesystem a file: URL so that all storage is really
on the physical host. It's often faster and preserves data better.
Question : in the standard word count MapReduce algorithm, why might using a combiner reduce the overall Job running time?
1. Because combiners perform local aggregation of word counts, thereby allowing the mappers to process input data faster.
2. Because combiners perform local aggregation of word counts, thereby reducing the number of mappers that need to run.
3. Access Mostly Uused Products by 50000+ Subscribers
reducers without writing the intermediate data to disk.
4. Because combiners perform local aggregation of word counts,
thereby reducing the number of key-value pairs that need to be snuff across the network to the reducers.
Ans : 4
Question : If you run the word count MapReduce program with m mappers and r reducers, how many output
files will you get at the end of the job? And how many key-value pairs will there be in each file?
Assume k is the number of unique words in the input files.
1. There will be r files, each with exactly k/r key-value pairs.
2. There will be r files, each with approximately k/m key-value pairs.
3. Access Mostly Uused Products by 50000+ Subscribers
4. There will be m files, each with exactly k/m key value pairs. E. There will be m files, each with approximately k/m key-value pairs.
Ans : 1
Question :
At line number 4 you replace
with
"this.conf= new Configuration(otherConf)"
where otherConf is an object
of Configuration class.

1. A new configuration with the same settings cloned from another.
2. It will give runtime error
3. Access Mostly Uused Products by 50000+ Subscribers
Ans : 1
Exp : A new configuration with the same settings cloned from another.
Configuration()
A new configuration.
Configuration(boolean loadDefaults)
A new configuration where the behavior of reading from the default resources can be turned off.
Configuration(Configuration other)
A new configuration with the same settings cloned from another.
Question :
At line number 6,
ABC should be replaced by which
of the following class to this
MapReduce Driver to work correctly
1. ABC. should be removed and nothing else is required.
2. Tool class
3. Access Mostly Uused Products by 50000+ Subscribers
4. Runner
5. Thread
Ans : 3
Exp : A utility to help run Tools.
ToolRunner can be used to run classes implementing Tool interface.
It works in conjunction with GenericOptionsParser to parse the generic hadoop command line arguments
and modifies the Configuration of the Tool. The application-specific options are passed along without being modified.
Question :
Which of the following could
be replaced safely at line number 9
1. Job job = new Job();
2. Job job = new Job(conf);
3. Access Mostly Uused Products by 50000+ Subscribers
4. You can not change this line from either 1 or 2
Ans : 3
Exp : All 1 and 2 are correct, however not having conf will ignore the custom configuration and 2nd argument present Custom job name.
If you dont provide it take default job name defined by framework.
Question :
If we are processing
input data from database
then at line 10 which of
the following is correct
InputFormat for reading from DB
1. DataBaseInputFormat
2. DBMSInputFormat
3. Access Mostly Uused Products by 50000+ Subscribers
4. Not Supported
Ans : 3
Exp : The DBInputFormat is an InputFormat class that allows you to read data from a database.
An InputFormat is Hadoops formalization of a data source; it can mean files formatted in a particular way,
data read from a database, etc. DBInputFormat provides a simple method of scanning entire tables from a database,
as well as the means to read from arbitrary SQL queries performed against the database.
Most queries are supported, subject to a few limitations
Question :
At line number 13 you
replace number of reducer to 1
and Setting Reducer class
as IdenityReducer then
which of the following
statement is correct
1. In both the cases behavious is same
2. With 0 reducer, reduce step will be skipped and mapper output will be the final out
3. Access Mostly Uused Products by 50000+ Subscribers
4. 1 and 3 both are correct
5. 2 and 3 both are correct
Ans : 5
Exp : If you do not need sorting of map results - you set 0 reduced,and the job is called map only.
If you need to sort the mapping results, but do not need any aggregation - you choose identity reducer.
we have a third case : we do need aggregation and, in this case we need reducer.
Question :
If we replace NullWritable.class
with new Text((String)null) at line number 15,
then which is correct
1. Both are same, program will give the same result
2. It will throw NullPointerException
3. Access Mostly Uused Products by 50000+ Subscribers
Ans : 3
Exp : Singleton Writable with no data.
NullWritable is a special type of Writable, as it has a zero length serialization. No bytes are written to, or read from, the stream.
It is used as a placeholder for example, in MapReduce, a key or a value can be declared as a NullWritable when you dont need to
use that position it effectively stores a constant empty value.
NullWritable can also be useful as a key in SequenceFile when you want to store a list of values,
as opposed to key value pairs. It is an immutable singleton the instance can be retrieved by calling NullWritable.get()
Question :
What is the use of
job.setJarByClass(NGramJob.class)
at line number 16
1. This method sets the jar file in which each node will look for the Mapper and Reducer classes
2. This is used to define which is the Driver class
3. Access Mostly Uused Products by 50000+ Subscribers
4. 1 and 2 both are correct
Ans : 1
Exp : This method sets the jar file in which each node will look for the Mapper and Reducer classes.
It does not create a jar from the given class. Rather, it identifies the jar containing the given class.
And yes, that jar file is "executed" (really the Mapper and Reducer in that jar file are executed) for the MapReduce job
Question :
At line number 18 if path "/out"
is already exist in HDFS then
1. Hadoop will delete this directory and create new empty directory and after processing put all output in this directory
2. It will write new data in existing directory and dont delete the existing data in this directory
3. Access Mostly Uused Products by 50000+ Subscribers
4. It will overwrite the existing content with new content
Ans : 3
Exp : It will throw exception, because hadoop will check the input and output specification before running any new job.
So it avoid already existing data being overwritten.
Question :
If you remove both
line 10 and 11 from
this code then what happen.
1. It will throw compile time error
2. Program will run successfully but Output file will not be created
3. Access Mostly Uused Products by 50000+ Subscribers
Ans : 3
Exp : As both are the defualt Input and Output format hence the program will run without any issue.
Question :
If you replace line 19
return job.waitForCompletion(true) ? 1 : 0;
with
job.submit();
then which is correct statement
1. In the cases MapReduce will run successfully
2. with waitForCompletion, Submit the job to the cluster and wait for it to finish
3. Access Mostly Uused Products by 50000+ Subscribers
4. All of the above correct
Question :
In above method at line 1 if you replace
context.write(new Text(gramBuilder.toString()), NullWritable.get());
with
context.write(gramBuilder.toString(), NullWritable.get());
what would happen

1. It would not work, because String is directly not supported
2. It would work, but it will not give good performence
3. Access Mostly Uused Products by 50000+ Subscribers
4. Code will not compile at all after this change
Ans : 2
Exp : Text class stores text using standard UTF8 encoding. It provides methods to serialize, deserialize,
and compare texts at byte level. The type of length is integer and is serialized using zero-compressed format.
In addition, it provides methods for string traversal without converting the byte array to a string.
Also includes utilities for serializing/deserialing a string, coding/decoding a string,
checking if a byte array contains valid UTF8 code, calculating the length of an encoded string.
Question :
If you have to use distributed cache for file
distribution then which is the right
place in above method to read the file

1. create new static method in the mapper and read the file in a variable and use that variable in map method
2. read the file in a setup() method and store in a variable and use that variable in map method
3. Access Mostly Uused Products by 50000+ Subscribers
4. read the file in a map() method and use that directly in map method
Ans:2
Question :
In above code we will replace
LongWritable with Long then what
would happen, the input to this
file from a file.
1. Code will run, but not produce result as expected
2. Code will not run as key has to be WritableComparable
3. Access Mostly Uused Products by 50000+ Subscribers
4. It will throw java.lang.ClassCastException
Ans : 4
Exp : The key class of a mapper that maps text files is always LongWritable.
That is because it contains the byte offset of the current
line and this could easily overflow an integer.

1. Only 1 first part with all even number
2. Only 2 files 1 is FILEA and other FILEB
3. Access Mostly Uused Products by 50000+ Subscribers
Ans : 3
Exp : Each reducer uses an OutputFormat to write records to. So that's why you are getting a set of odd and even files per reducer.
This is by design so that each reducer can perform writes in parallel.
If you want just a single odd and single even file, you'll need to set mapred.reduce.tasks to 1.
But performance will suffer, because all the mappers will be feeding into a single reducer.
Another option is to change the process the reads these files to accept multiple input files,
or write a separate process that merges these files together.
Question

1. This job will throw run time exception because no Mapper and Reducer Provided
2. Job will run and produce each line is an integer followed by a tab character, followed by the original line
3. Access Mostly Uused Products by 50000+ Subscribers
4. Job will run and produce original line in output files
Ans : 2
Exp : Each line is an integer followed by a tab character, followed by the original weather
data record. An InputFormat for plain text files. Files are broken into lines.
Either linefeed or carriage-return are used to signal end of line. Keys are the position in the file, and values are the line of text..
Because default input format is a TextInputFormat
Question

1. 1
2. 2
3. Access Mostly Uused Products by 50000+ Subscribers
4. 4
5. No output will be produced, because default Mapper and Reducer class is used
Ans : 3
Exp :The default mapper is just the Mapper class, which writes the input key and value unchanged
to the output, The default partitioner is HashPartitioner, which hashes a records key to determine
which partition the record belongs in. Each partition is processed by a reduce task, so
the number of partitions is equal to the number of reduce tasks for the job, The default reducer is Reducer,
again a generic type, which simply writes all its input to its output. If proper input is provided then Number of
Output files is equal to number of reducers.
Question

1. 1
2. 2
3. Access Mostly Uused Products by 50000+ Subscribers
Ans : 1
Exp : As you can see in 2nd option reducer does not have calculated max temprature for the year.
And in the 3rd option in the Map function, in the output temperature as key and year as a value, which does not fit
as per our algorithm. We have to get same year temperature in the same reducer to calculate maximum temperature. Hence
we have to have year as a key and temperature in the value field.
Question

1. 1
2. 2
3. Access Mostly Uused Products by 50000+ Subscribers
4. 4
5. 5
Ans : 1
Exp :Sqoop can generate a Hive table based on a table from an existing relational data source.
Since we have already imported the widgets data to HDFS, we can generate the Hive table
definition and then load in the HDFS-resident data:
% sqoop create-hive-table --connect jdbc:mysql://localhost/hadoopguide --table widgets --fields-terminated-by ','
...
10/06/23 18:05:34 INFO hive.HiveImport: OK
10/06/23 18:05:34 INFO hive.HiveImport: Time taken: 3.22 seconds
10/06/23 18:05:35 INFO hive.HiveImport: Hive import complete.
% hive
LOAD DATA INPATH "widgets" INTO TABLE widgets;
Loading data to table widgets
OK
Time taken: 3.265 seconds
When creating a Hive table definition with a specific already-imported dataset in mind,
we need to specify the delimiters used in that dataset. Otherwise, Sqoop will allow Hive
to use its default delimiters (which are different from Sqoops default delimiters).
Question

1. 1
2. 2
3. Access Mostly Uused Products by 50000+ Subscribers
4. 4
Ans : 4
Exp : In most cases, importing data into Hive is the same as running the import task and then using Hive to create
and load a certain table or partition. Doing this manually requires that you know the correct type mapping between
the data and other details like the serialization format and delimiters. Sqoop takes care of populating the Hive
metastore with the appropriate metadata for the table and also invokes the necessary commands to load the
table or partition as the case may be. All of this is done by simply specifying the option --hive-import with the import command.
sqoop import --connect jdbc:mysql://localhost/acmedb --table ORDERS --username test --password **** --hive-import
When you run a Hive import, Sqoop converts the data from the native datatypes within the external
datastore into the corresponding types within Hive. Sqoop automatically chooses the native delimiter
set used by Hive. If the data being imported has new line or other Hive delimiter characters in it,
Sqoop allows you to remove such characters and get the data correctly populated for consumption in Hive.
Question

1. 1,2,3,4
2. 2,1,3,4
3. Access Mostly Uused Products by 50000+ Subscribers
4. 1,4,3,2
Ans : 3
Exp : Maps input key/value pairs to a set of intermediate key/value pairs.
Maps are the individual tasks which transform input records into a intermediate records. The transformed intermediate records need not be of the same type as the input records. A given input pair may map to zero or many output pairs.
The Hadoop Map-Reduce framework spawns one map task for each InputSplit generated by the InputFormat for the job. Mapper implementations can access the Configuration for the job via the JobContext.getConfiguration().
The framework first calls setup(org.apache.hadoop.mapreduce.Mapper.Context), followed by map(Object, Object, Context) for each key/value pair in the InputSplit. Finally cleanup(Context) is called.
All intermediate values associated with a given output key are subsequently grouped by the framework, and passed to a Reducer to determine the final output. Users can control the sorting and grouping by specifying two key RawComparator classes.
The Mapper outputs are partitioned per Reducer. Users can control which keys (and hence records) go to which Reducer by implementing a custom Partitioner.
Users can optionally specify a combiner, via Job.setCombinerClass(Class), to perform local aggregation of the intermediate outputs, which helps to cut down the amount of data transferred from the Mapper to the Reducer.
Applications can specify if and how the intermediate outputs are to be compressed and which CompressionCodecs are to be used via the Configuration.
If the job has zero reduces then the output of the Mapper is directly written to the OutputFormat without sorting by keys.
Question : Which is the correct statement when you poorly define the Partioner
1. it has a direct impact on the overall performance of your job and can reduce the performance of the overall job
2. a poorly designed partitioning function will not evenly distributes the values over the reducers
3. Access Mostly Uused Products by 50000+ Subscribers
4. Both 1 and 2 are correct
5. All 1, 2 and 3 are correct
Ans : 4
Exp : First, it has a direct impact on the overall performance of your job: a poorly designed partitioning function will not evenly distributes
the charge over the reducers, potentially loosing all the interest of the map/reduce distributed infrastructure.
Question : Suppose that your jobs input is a (huge) set of word tokens and their number of occurrences (word count)
and that you want to sort them by number of occurrences. Then which one of the following class will help you to get globally sorted file
1. Combiner
2. Partitioner
3. Access Mostly Uused Products by 50000+ Subscribers
4. By Default all the files are sorted.
Ans : 2
Exp : it is possible to produce a set of sorted files that, if concatenated,
would form a globally sorted file. The secret to doing this is to use a partitioner that
respects the total order of the output. For example, if we had four partitions, we could put keys
for temperatures less than negative 10 C in the first partition, those between negative 10 C and 0 C in the second,
those between 0 C and 10 C in the third, and those over 10C in the fourth.
Question : When you are implementing the secondary sort (Sorting based on values) like, following output is produced as Key Part of the Mapper
2001 24.3
2002 25.5
2003 23.6
2004 29.4
2001 21.3
2002 24.5
2003 25.6
2004 26.4
.
.
2014 21.0
Now you want same year output goes to the same reducer, whic of the following will help yoo to do so;
1. CustomPartitioner
2. Group Comparator
3. Access Mostly Uused Products by 50000+ Subscribers
4. By Implemeting Custom WritableComparator
5. Or using Single Reducer
Ans : 2
Exp : Map output key is year and temperature to achieve sorting.
Unless you define a grouping comparator that uses only the year part of the map output key,
you can nott make all records of the same year go to same reduce method call
Youre right that by partitioning on the year youll get all the data for
a year in the same reducer,
so the comparator will effectively sort the data for each year by the temperature
Question

1. A
2. B
3. Access Mostly Uused Products by 50000+ Subscribers
Ans : 1
Exp : Check the URL http://oozie.apache.org/docs/3.1.3-incubating/WorkflowFunctionalSpec.html
Question Which of the following is possible as part of Oozie workflow

1. Running Multiple Jobs in Parallel
2. Output of all the Parallel Jobs can be used as an Input to next job
3. Access Mostly Uused Products by 50000+ Subscribers
4. You can include Hive Jobs as well as Pig Jobs as part of OOzie workdflow
5. All 1,2 and 5 are correct
Ans : 5
Exp : Check the URL http://oozie.apache.org/docs/3.1.3-incubating/WorkflowFunctionalSpec.html
Question Select the correct statement for OOzie workflow
1. OOzie workflow runs on a server which is typically outside of Hadoop Cluster
2. OOzie workflow definition are submitted via HTTP.
3. Access Mostly Uused Products by 50000+ Subscribers
4. All 1,2 and 3 are correct
5. Only 1 and 3 are correct
Ans : 4
Exp : Check the URL http://oozie.apache.org/docs/3.1.3-incubating/WorkflowFunctionalSpec.html
Question Which of the following is correct for the OOzie control nodes
1. fork splits the execution path
2. join waits for all concurrent execution paths to complete before proceeding
3. Access Mostly Uused Products by 50000+ Subscribers
4. Only 1 and 3 are correct
5. All 1,2 and 3 are correct
Ans : 5
Exp : Check the URL http://oozie.apache.org/docs/3.1.3-incubating/WorkflowFunctionalSpec.html
Question Which of the following is correct for the OOzie control nodes
1. fork splits the execution path
2. join waits for all concurrent execution paths to complete before proceeding
3. Access Mostly Uused Products by 50000+ Subscribers
4. Only 1 and 3 are correct
5. All 1,2 and 3 are correct
Ans : 5
Exp : Check the URL http://oozie.apache.org/docs/3.1.3-incubating/WorkflowFunctionalSpec.html
Question

1. A
2. B
3. Access Mostly Uused Products by 50000+ Subscribers
Ans : 3
Exp : Check the URL http://oozie.apache.org/docs/3.1.3-incubating/WorkflowFunctionalSpec.html
Question

1. A
2. B
3. Access Mostly Uused Products by 50000+ Subscribers
Ans : 2
Exp : Check the URL http://oozie.apache.org/docs/3.1.3-incubating/WorkflowFunctionalSpec.html
Question Select the correct statement which applies to Distributed cache
1. Transfer happens behind the scenes before any task is executed
2. Distributed Cache is read/only
3. Access Mostly Uused Products by 50000+ Subscribers
4. As soon as tasks starts the Cached file is copied from Central Location to Task Node.
5. 1,2 and 3 are correct
Ans : 5
Question Select the correct statement which applies to Distributed cache
1. Transfer happens behind the scenes before any task is executed
2. Distributed Cache is read/only
3. Access Mostly Uused Products by 50000+ Subscribers
4. As soon as tasks starts the Cached file is copied from Central Location to Task Node.
5. 1,2 and 3 are correct
Ans : 5
Question

1. 1
2. 2
3. Access Mostly Uused Products by 50000+ Subscribers
Ans : 1
Question Which is the correct statement for RecordReader
1. RecordReader, typically, converts the byte-oriented view of the input,
provided by the InputSplit, and presents a record-oriented view
for the Mapper and Reducer tasks for processing.
2. It assumes the responsibility of processing record boundaries and presenting the tasks with keys and values.
3. Access Mostly Uused Products by 50000+ Subscribers
4. 1,3 are correct
5. 1,2 are correct
Ans : 5
Question

1. A
2. B
3. Access Mostly Uused Products by 50000+ Subscribers
Ans : 1
Question

1. A
2. B
3. Access Mostly Uused Products by 50000+ Subscribers
Ans : 1
Question

1. A
2. B
3. Access Mostly Uused Products by 50000+ Subscribers
Ans : 1
Question

1. A
2. B
3. Access Mostly Uused Products by 50000+ Subscribers
Ans : 2
Question

1. A
2. B
3. Access Mostly Uused Products by 50000+ Subscribers
Ans : 3
Question
Suppose you have input file that contains the following data
Name:Dash
Age:27
Name:Nish
Age:29
.
.
.
.
And you want to produce the two file as an output of MapReduce Job then which is the Best Output format class you will use and override
1. TextOutputFormat
2. SequenceFileOutputFormat
3. Access Mostly Uused Products by 50000+ Subscribers
4. MultipleTextOutputFormat
Ans : 4
Question : You have millions of user in QuickTechie.com website as sample given in the image.
This all information is stored in the Backend MySQL database. Which of the given command will
help you to copy this MAINPROFILE table into the Hive MAINPROFILE table,
Which Hadoop command creates a Hive table called LOGIN equivalent to the LOGIN database table?
1. sqoop create-hive-table --connect jdbc:mysql://dbhost/db --table MAINPROFILE
2. hive -e 'CREATE TABLE MAINPROFILE (USERID int, FIRST_NAME string, LAST_NAME string, CITY string);'
3. Access Mostly Uused Products by 50000+ Subscribers
4. sqoop create-hive-table --connect jdbc:mysql://dbhost/db --table MAINPROFILE --hive-table
5. sqoop import --hive-import --connect jdbc:mysql://dbhost/db --table MAINPROFILE --hive-create-table
Ans : 1
Exp : Here, you import all of the Service Order Database directly from MySQL into Hive and run a HiveQL query against the newly imported database on Apache Hadoop. The following listing shows you how it's done.hive> create database serviceorderdb;
hive> use serviceorderdb;
$ sqoop import --connect jdbc:mysql://localhost/serviceorderdb --username root -P --table productinfo --hive-import --hive-table serviceorderdb.productinfo -m 1
$ sqoop import --connect jdbc:mysql://localhost/serviceorderdb --username root -P --table customercontactinfo --hive-import --hive-table serviceorderdb.customercontactinfo -m 1
13/08/16 17:21:35 INFO hive.HiveImport: Hive import complete.
$ sqoop import --connect jdbc:mysql://localhost/serviceorderdb --username root -P --table serviceorders --hive-import --hive-table serviceorderdb.serviceorders -m 1
When the import operations are complete, you run the show tables command to list the newly imported tables (see the following listing):
hive> show tables;
customercontactinfo
productinfo
serviceorders
Then run a Hive query to show which Apache Hadoop technologies have open service orders in the database: hive> SELECT productdesc FROM productinfo
> INNER JOIN serviceorders > ON productinfo.productnum = serviceorders.productnum;
HBase Support Product
Hive Support Product
Sqoop Support Product
Pig Support Product
You can confirm the results. You have four open service orders on the products in bold. The Sqoop Hive import operation worked, and now the service company can leverage Hive to query, analyze, and transform its service order structured data. Additionally, the company can now combine its relational data with other data types (perhaps unstructured) as part of any new Hadoop analytics applications. Many possibilities now exist with Apache Hadoop being part of the overall IT strategy!% hive -e 'CREATE TABLE MAINPROFILE ((USERID int, FIRST_NAME string, LAST_NAME string, CITY string);' % hive -e 'CREATE EXTERNAL TABLE IF NOT EXISTS MAINPROFILE (USERID int, FIRST_NAME string, LAST_NAME string, CITY string)' Both of the above both create the time column as a data type, which cannot store the information from the time field about the time. The hour, minute, and second information would be dropped.
% sqoop create-hive-table --connect jdbc:mysql://dbhost/db --table MAINPROFILE
The above is correct because it correctly uses the Sqoop operation to create a Hive table that matches the database table.
% sqoop create-hive-table --connect jdbc:mysql://dbhost/db --table MAINPROFILE --hive-table
The above is incorrect because the --hive-table option for Sqoop requires a parameter that names the target table in the database.
% sqoop import --hive-import --connect jdbc:mysql://dbhost/db --table MAINPROFILE --hive-create-table
The above is incorrect because the Sqoop import command has no --hive-create-table option
Question : You have millions of user in QuickTechie.com website as sample given in the image.
This all information is stored in the Backend MySQL database. Which of the given command will
help you to copy this MAINPROFILE table into the Hive MAINPROFILE table,
Which command will delete the Hive LOGIN table you just created MAINPROFILE ?
1. hive -e 'DELETE TABLE MAINPROFILE'
2. hive -e 'TRUNCATE TABLE MAINPROFILE'
3. Access Mostly Uused Products by 50000+ Subscribers
4. All 1,2 and 3 are similar
5. Once table is created it can not be deleteds
Ans : 3
Exp : DROP TABLE [IF EXISTS] table_name DROP TABLE removes metadata and data for this table. The data is actually moved to the .Trash/Current directory if Trash is configured. The metadata is completely lost. When dropping an EXTERNAL table, data in the table will NOT be deleted from the file system. When dropping a table referenced by views, no warning is given (the views are left dangling as invalid and must be dropped or recreated by the user). Otherwise, the table information is removed from the metastore and the raw data is removed as if by 'hadoop dfs -rm'. In many cases, this results in the table data being moved into the user's .Trash folder in their home directory; users who mistakenly DROP TABLEs mistakenly may thus be able to recover their lost data by re-creating a table with the same schema, re-creating any necessary partitions, and then moving the data back into place manually using Hadoop. This solution is subject to change over time or across installations as it relies on the underlying implementation; users are strongly encouraged not to drop tables capriciously. In Hive 0.7.0 or later, DROP returns an error if the table doesn't exist, unless IF EXISTS is specified or the configuration variable hive.exec.drop.ignorenonexistent is set to true. Sqoop does not offer a way to delete a table from Hive, although it will overwrite the table definition during import if the table already exists and --hive-overwrite is specified. The correct HiveQL statement to drop a table is"DROP TABLE tablename". In Hive, table names are all case insensitive.
Its suggested , please read Hive Language Document from : https://cwiki.apache.org/confluence/display/Hive/LanguageManual
Question : You have millions of user in QuickTechie.com website as sample given in the image.
This all information is stored in the Backend MySQL database. Which of the given command will
help you to copy this MAINPROFILE table into the Hive MAINPROFILE table,
Which command will delete the Hive MAINPROFILE table you just created ?
Select the command that will delete all the rows of with userid 1000 from Hive MAINPROFILE table,
where userid column is partitioned you just created?
1. TRUNCATE TABLE MAINPROFILE WHERE userid = 1000;
2. TRUNCATE TABLE MAINPROFILE PARTITION (userid = 1000);
3. Access Mostly Uused Products by 50000+ Subscribers
4. DELETE FROM MAINPROFILE WHERE PARTITION = 1000;
Ans : 2
Exp : Hive is a good tool for performing queries on large datasets, especially datasets that require full table scans. But quite often there are instances where users need to filter the data on specific column values. Generally, Hive users know about the domain of the data that they deal with. With this knowledge they can identify common columns that are frequently queried in order to identify columns with low cardinality which can be used to organize data using the partitioning feature of Hive. In non-partitioned tables, Hive would have to read all the files in a table's data directory and subsequently apply filters on it. This is slow and expensive-especially in cases of large tables.
The concept of partitioning is not new for folks who are familiar with relational databases. Partitions are essentially horizontal slices of data which allow larger sets of data to be separated into more manageable chunks. TRUNCATE TABLE table_name [PARTITION partition_spec];In Hive, partitioning is supported for both managed and external tables in the table definition as seen below. CREATE TABLE REGISTRATION DATA ( userid BIGINT, First_Name STRING,
Last_Name STRING, address1 STRING, address2 STRING, city STRING, zip_code STRING,
state STRING )
PARTITION BY ( REGION STRING, COUNTRY STRING )
partition_spec:
: (partition_col = partition_col_value, partition_col = partiton_col_value, ...)
Removes all rows from a table or partition(s). Currently target table should be native/managed table or exception will be thrown. User can specify partial partition_spec for truncating multiple partitions at once and omitting partition_spec will truncate all partitions in the table.
Its suggested , please read Hive Language Document from : https://cwiki.apache.org/confluence/display/Hive/LanguageManual
Question : You have millions of user in QuickTechie.com website as sample given in the image.
This all information is stored in the Backend MySQL database. Which of the given command will
help you to copy this MAINPROFILE table into the Hive MAINPROFILE table,
Which command will import the entire contents of the MAINPROFILE table
from the database into a Hive table called MAINPROFILE that uses commas (,) to separate the fields in the data files?
1. hive import --connect jdbc:mysql://dbhost/db --table MAINPROFILE --terminated-by ',' --hive-import
2. hive import --connect jdbc:mysql://dbhost/db --table MAINPROFILE --fields-terminated-by ',' --hive-import
3. Access Mostly Uused Products by 50000+ Subscribers
4. sqoop import --connect jdbc:mysql://dbhost/db --table MAINPROFILE --fields-terminated-by ',' --hive-import
Ans : 4 Exp : Here, you import all of the Service Order Database directly from MySQL into Hive and run a HiveQL query against the newly imported database on Apache Hadoop. The following listing shows you how it's done.hive> create database serviceorderdb;
hive> use serviceorderdb;
$ sqoop import --connect jdbc:mysql://localhost/serviceorderdb --username root -P --table productinfo --hive-import --hive-table serviceorderdb.productinfo -m 1
$ sqoop import --connect jdbc:mysql://localhost/serviceorderdb --username root -P --table customercontactinfo --hive-import --hive-table serviceorderdb.customercontactinfo -m 1
13/08/16 17:21:35 INFO hive.HiveImport: Hive import complete.
$ sqoop import --connect jdbc:mysql://localhost/serviceorderdb --username root -P --table serviceorders --hive-import --hive-table serviceorderdb.serviceorders -m 1
When the import operations are complete, you run the show tables command to list the newly imported tables (see the following listing):
hive> show tables;
customercontactinfo
productinfo
serviceorders
Then run a Hive query to show which Apache Hadoop technologies have open service orders in the database: hive> SELECT productdesc FROM productinfo
> INNER JOIN serviceorders > ON productinfo.productnum = serviceorders.productnum;
HBase Support Product
Hive Support Product
Sqoop Support Product
Pig Support Product You can confirm the results. You have four open service orders on the products in bold. The Sqoop Hive import operation worked, and now the service company can leverage Hive to query, analyze, and transform its service order structured data. Additionally, the company can now combine its relational data with other data types (perhaps unstructured) as part of any new Hadoop analytics applications. Many possibilities now exist with Apache Hadoop being part of the overall IT strategy!% hive -e 'CREATE TABLE MAINPROFILE ((USERID int, FIRST_NAME string, LAST_NAME string, CITY string);' % hive -e 'CREATE EXTERNAL TABLE IF NOT EXISTS MAINPROFILE (USERID int, FIRST_NAME string, LAST_NAME string, CITY string)' Both of the above both create the time column as a data type, which cannot store the information from the time field about the time. The hour, minute, and second information would be dropped. Sqoop import to a Hive table requires the import option followed by the --table option to specify the database table name and the --hive-import option. If --hive-table is not specified, the Hive table will have the same name as the imported database table. If --hive-overwrite is specified, the Hive table will be overwritten if it exists. If the --fields-terminated-by option is set, it controls the character used to separate the fields in the Hive table's data files.
Watch Hadoop Professional training Module : 22 by www.HadoopExam.com
http://hadoopexam.com/index.html/#hadoop-training
Question : For transferring all the stored user profile of QuickTechie.com websites in Oracle Database under table called MAIN.PROFILE
to HDFS you wrote a Sqoop job, Assume $LASTFETCH contains a date:time string for the last time the import was run, e.g., '2015-01-01 12:00:00'.
Finally you have the MAIN.PROFILE table imported into Hive using Sqoop, you need to make this log data available to Hive to perform a join operation.
Assuming you have uploaded the MAIN.PROFILE.log into HDFS, select the appropriate way to creates a Hive table that contains the log data:

1. Create an external table in the Hive shell using org.apache.hadoop.hive.serde2.SerDeStatsStruct to extract the column data from the logs
2. Create an external table in the Hive shell using org.apache.hadoop.hive.serde2.RegexSerDe to extract the column data from the logs
3. Access Mostly Uused Products by 50000+ Subscribers
4. Create an external table in the Hive shell using org.apache.hadoop.hive.serde2.NullStructSerDe to extract the column data from the logs
Ans : 2
Exp : External Tables
The EXTERNAL keyword lets you create a table and provide a LOCATION so that Hive does not use a default location for this table. This comes in handy if you already have data generated. When dropping an EXTERNAL table, data in the table is NOT deleted from the file system.
An EXTERNAL table points to any HDFS location for its storage, rather than being stored in a folder specified by the configuration property hive.metastore.warehouse.dir.
CREATE EXTERNAL TABLE page_view(viewTime INT, userid BIGINT,
page_url STRING, referrer_url STRING,
ip STRING COMMENT 'IP Address of the User',
country STRING COMMENT 'country of origination')
COMMENT 'This is the staging page view table'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\054'
STORED AS TEXTFILE
LOCATION '(hdfs_location)';
You can use the above statement to create a page_view table which points to any hdfs location for its storage. But you still have to make sure that the data is delimited as specified in the CREATE statement above.When building a Hive table from log data, the column widths are not fixed, so the only way to extract the data is with a regular expression. The org.apache.hadoop.hive.serde2.RegexSerDe class reads data from a flat file and extracts column information via a regular expression. The SerDe is specified as part of the table definition when the table is created. Once the table is created, the LOAD command will add the log files to the table. For more information about SerDes in Hive, see How-to: Use a SerDe in Apache Hive and chapter 12 in Hadoop: The Definitive Guide, 3rd Edition in the Tables: Storage Formats section. RegexSerDe uses regular expression (regex) to serialize/deserialize.
It can deserialize the data using regex and extracts groups as columns. It can also serialize the row object using a format string. In deserialization stage, if a row does not match the regex, then all columns in the row will be NULL. If a row matches the regex but has less than expected groups, the missing groups will be NULL. If a row matches the regex but has more than expected groups, the additional groups are just ignored. In serialization stage, it uses java string formatter to format the columns into a row. If the output type of the column in a query is not a string, it will be automatically converted to String by Hive.
Watch Module 12 and 13 : http://hadoopexam.com/index.html/#hadoop-training
And refer : https://hive.apache.org/javadocs/r0.10.0/api/org/apache/hadoop/hive/serde2/package-summary.html
Question : You habe written an ETL job, however while processing the data it also depend on some other classes, which is packaged under two seperate jars TimeSeries.jar and other one is HOC.jar.
Now you want these two jars should also be distributed and must be used during the Job Executions. Refer the sample snippet of driver code as below which is bundeled under the QTETL.jar file.
Select the correct command which execute QTETLDataLoad MapReduce jobs with the HOC.jar and TimeSeries.jar will be distributed to the node where job will be executed.
public class QTETLDataLoad extends Configured implements Tool {
public static void main(final String[] args) throws Exception {
Configuration conf = new Configuration();
int res = ToolRunner.run(conf, new Example(), args);
System.exit(res); }
public int run(String[] args) throws Exception { Job job = new Job(super.getConf());
//remove the detailed code for keeping the code short
job.waitForCompletion(true);
}}
1. hadoop jar QTETL.jar Example -includes TimeSeries.jar , HOC.jar
2. hadoop jar QTETL.jar Example -libjars TimeSeries.jar , HOC.jar
3. Access Mostly Uused Products by 50000+ Subscribers
4. hadoop jar QTETL.jar Example -dist TimeSeries.jar , HOC.jar
5. hadoop jar QTETL.jar Example -classpath TimeSeries.jar , HOC.jar
Ans : 2 Exp : When working with MapReduce one of the challenges that is encountered early-on is determining how to make your third-part JAR's available to the map and reduce tasks. One common approach is to create a fat jar, which is a JAR that contains your classes as well as your third-party classes (see this Cloudera blog post for more details). A more elegant solution is to take advantage of the libjars option in the hadoop jar command, also mentioned in the Cloudera post at a high level. Here I'll go into detail on the three steps required to make this work. Add libjars to the options It can be confusing to know exactly where to put libjars when running the hadoop jar command. The following example shows the correct position of this option:
$ export LIBJARS=/path/jar1,/path/jar2
$ hadoop jar my-example.jar com.example.MyTool -libjars ${LIBJARS} -mytoolopt value
It's worth noting in the above example that the JAR's supplied as the value of the libjar option are comma-separated, and not separated by your O.S. path delimiter (which is how a Java classpath is delimited). You may think that you're done, but often times this step alone may not be enough - read on for more details!
Make sure your code is using GenericOptionsParser The Java class that's being supplied to the hadoop jar command should use the GenericOptionsParser class to parse the options being supplied on the CLI. The easiest way to do that is demonstrated with the following code, which leverages the ToolRunner class to parse-out the options:
public static void main(final String[] args) throws Exception {
Configuration conf = new Configuration();
int res = ToolRunner.run(conf, new com.example.MyTool(), args);
System.exit(res); } It is crucial that the configuration object being passed into the ToolRunner.run method is the same one that you're using when setting-up your job. To guarantee this, your class should use the getConf() method defined in Configurable (and implemented in Configured) to access the configuration:
public class SmallFilesMapReduce extends Configured implements Tool {
public final int run(final String[] args) throws Exception {
Job job = new Job(super.getConf());
job.waitForCompletion(true);
return ...; }
If you don't leverage the Configuration object supplied to the ToolRunner.run method in your MapReduce driver code, then your job won't be correctly configured and your third-party JAR's won't be copied to the Distributed Cache or loaded in the remote task JVM's.The syntax for executing a job and including archives in the job's classpath is: hadoop jar -libjars ,[,...]
Watch Hadoop Training Module 9 from : http://hadoopexam.com/index.html/#hadoop-training
Question : From the Acmeshell.com website you have your all the data stored in Oracle database table called MAIN.PROFILES table. In HDFS you already
have your Apache WebServer log file stored called users_activity.log . Now you want to combine/join both the data users_activity.log file and MAIN.PROFILES
table. Initailly, you want to import the table data from the database into HDFS. Select the most suitable way to copy all of the data in the MAIN.PROFILES table into a file in HDFS?
1. Use Hive with the Oracle connector to import the database table to HDFS.
2. Use Sqoop with the Oracle connector to import the database table to HDFS.
3. Access Mostly Uused Products by 50000+ Subscribers
4. Use Custom SerDe with the Oracle connector to import the database table to HDFS.
5. None of the above (It is not possible)
Ans : 2 Exp : training Module : 22 Apache Sqoop (SQL To Hadoop) by http://hadoopexam.com/index.html/#hadoop-training
$ sqoop import (generic-args) (import-args)
$ sqoop-import (generic-args) (import-args)
While the Hadoop generic arguments must precede any import arguments, you can type the import arguments in any order with respect to one another.
Argument Description
--connect jdbc-uri Specify JDBC connect string
--connection-manager class-name Specify connection manager class to use
--driver class-name Manually specify JDBC driver class to use
--hadoop-mapred-home dir Override $HADOOP_MAPRED_HOME
--help Print usage instructions
--password-file Set path for a file containing the authentication password
-P Read password from console
--password password Set authentication password
--username username Set authentication username
--verbose Print more information while working
--connection-param-file filename Optional properties file that provides connection parameters
The most efficient approach will be to use Sqoop with the MySQL connector. Beneath the covers it uses the mysqldump command to achieve rapid data export in parallel. The next most efficient approach will be to use Sqoop with the JDBC driver. The JDBC driver uses a JDBC connection, which is not as efficient as mysqldump. The next most efficient approach will be to use the DBInputFormat class. The results will be similar to using Sqoop with the JDBC driver, but the Sqoop jobs are more optimized. The least efficient approach will be to usemysqldump directly as the dump and subsequent upload are not parallelized operations. There is noPigJDBCConnector class.
Further Reading
For more information on Sqoop, see the Sqoop Users Guide or chapter 15 in Hadoop: The Definitive Guide, 3rd Edition. For information about using the DBInputFormat class, see Database Access with Apache Hadoop. For information about Hive, see the Hive Wiki or chapter 12 in Hadoop: The Definitive Guide, 3rd Edition.
Question : From the Acmeshell.com website you have your all the data stored in Oracle database table called MAIN.PROFILES table. In HDFS you already
have your Apache WebServer log file stored called users_activity.log . Now you want to combine/join both the data users_activity.log file and MAIN.PROFILES
table. Initailly, you want to import the table data from the database into HDFS. Now that the database MAIN.PROFILES table has been imported (CSV format)
in the /user/acmeshell directory in HDFS. Select the most suitable way so that this data will be available as Hive table.

1. By default this data will be available in Hive table format as already loaded in HDFS.
2. You have to create internal Hive table
3. Access Mostly Uused Products by 50000+ Subscribers
4. Both 1 and 2 are possible way.
Ans : 3 Exp : Watch Module 12 and 13 for full Hive Internal and External table from : http://hadoopexam.com/index.html/#hadoop-training
Hive has a relational database on the master node it uses to keep track of state. For instance, when you CREATE TABLE FOO(foo string) LOCATION 'hdfs://tmp/';, this table schema is stored in the database. If you have a partitioned table, the partitions are stored in the database(this allows hive to use lists of partitions without going to the filesystem and finding them, etc). These sorts of things are the 'metadata'. When you drop an internal table, it drops the data, and it also drops the metadata. When you drop an external table, it only drops the meta data. That means hive is ignorant of that data now. It does not touch the data itself.
An external Hive table can be created that points to any file in HDFS. The table can be configured to use arbitrary field and row delimeters or even extract fields via regular expressions.
Question : From the Acmeshell.com website you have your all the data stored in Oracle database table called MAIN.PROFILES table. In HDFS you already
have your Apache WebServer log file stored called users_activity.log . Now you want to combine/join both the data users_activity.log file and MAIN.PROFILES
table. Initailly, you want to import the table data from the database into HDFS and used the Sqoop tool for doing this. You already have one of the Python script
to scrub this joined data. After scrubing this data you will use Hive to write output in a new table called MAIN.SCRUBBED_PROFILE
Select the suitable way of doing this activity.
1. Using the OOZIE workflow engine you have to create workflow with Sqoop job, the MapReduce job, and the Hive, and schedule this workflow job to run daily.
2. Using the OOZIE workflow engine you have to create workflow with Sqoop job, the MapReduce job, and the Hive job, and define an MapReduce chanin job to run this workflow job daily.
3. Access Mostly Uused Products by 50000+ Subscribers
4. Using the OOZIE workflow engine you have to create workflow with Sqoop job, the MapReduce job, and the Hive job , and define an Oozie coordinator job to run the workflow daily.
5. None of the above.
Ans : 4
Exp : Users typically run map-reduce, hadoop-streaming, hdfs and/or Pig jobs on the grid. Multiple of these jobs can be combined to form a workflow job. Oozie, Hadoop Workflow System defines a workflow system that runs such jobs. Commonly, workflow jobs are run based on regular time intervals and/or data availability. And, in some cases, they can be triggered by an external event. Expressing the condition(s) that trigger a workflow job can be modeled as a predicate that has to be satisfied. The workflow job is started after the predicate is satisfied. A predicate can reference to data, time and/or external events. In the future, the model can be extended to support additional event types. It is also necessary to connect workflow jobs that run regularly, but at different time intervals. The outputs of multiple subsequent runs of a workflow become the input to the next workflow. For example, the outputs of last 4 runs of a workflow that runs every 15 minutes become the input of another workflow that runs every 60 minutes. Chaining together these workflows result it is referred as a data application pipeline.The Oozie Coordinator system allows the user to define and execute recurrent and interdependent workflow jobs (data application pipelines). Real world data application pipelines have to account for reprocessing, late processing, catchup, partial processing, monitoring, notification and SLAs. This document defines the functional specification for the Oozie Coordinator system.Oozie does not allow you to schedule workflow jobs; in Oozie, scheduling is the function of an Oozie coordinator job. Conversely, Oozie coordinator jobs cannot aggregate tasks or define workflows; coordinator jobs are simple schedules of previously defined worksflows. You must therefore assemble the various tasks into a single workflow job and then use a coordinator job to execute the workflow job. For more information about Oozie.
Here are some typical use cases for the Oozie Coordinator Engine.
You want to run your workflow once a day at 2PM (similar to a CRON).
You want to run your workflow every hour and you also want to wait for specific data feeds to be available on HDFS
You want to run a workflow that depends on other workflows.
Benefits
Easily define all your requirements for triggering your workflow in an XML file
Avoid running multiple crontabs to trigger your workflows.
Avoid writing custom scripts that poll HDFS to check for input data and trigger workflows.
Oozie is provided as a service by the Grid Operations Team. You do not need to install software to start using Oozie on the Grid.
Question : From the Acmeshell.com website you have your all the data stored in Oracle database table called MAIN.PROFILES table. In HDFS you already
have your Apache WebServer log file stored called users_activity.log . Now you want to combine/join both the data users_activity.log file and MAIN.PROFILES
table. Initailly, you want to import the table data from the database into Hive using Sqoop with the default setting. Select the correct statement for this import
to HIve table.
1. It will use default delimiter 0x01 (^B)
2. It will use default delimiter 0x01 (^A)
3. Access Mostly Uused Products by 50000+ Subscribers
4. It will use default delimiter 0x01 (,)
5. None of the above
Ans : 2
Exp : Even though Hive supports escaping characters, it does not handle escaping of new-line character. Also, it does not support the notion of enclosing characters that may include field delimiters in the enclosed string. It is therefore recommended that you choose unambiguous field and record-terminating delimiters without the help of escaping and enclosing characters when working with Hive; this is due to limitations of Hive's input parsing abilities. If you do use --escaped-by, --enclosed-by, or --optionally-enclosed-by when importing data into Hive, Sqoop will print a warning message. Hive will have problems using Sqoop-imported data if your database's rows contain string fields that have Hive's default row delimiters (\n and \r characters) or column delimiters (\01 characters) present in them. You can use the --hive-drop-import-delims option to drop those characters on import to give Hive-compatible text data. Alternatively, you can use the --hive-delims-replacement option to replace those characters with a user-defined string on import to give Hive-compatible text data. These options should only be used if you use Hive's default delimiters and should not be used if different delimiters are specified.
Sqoop will pass the field and record delimiters through to Hive. If you do not set any delimiters and do use --hive-import, the field delimiter will be set to ^A and the record delimiter will be set to \n to be consistent with Hive's defaults.By default Sqoop uses Hive's default delimiters when doing a Hive table export, which is 0x01 (^A). The table name used in Hive is, by default, the same as that of the source table. You can control the output table name with the --hive-table option. Hive can put data into partitions for more efficient query performance. You can tell a Sqoop job to import data for Hive into a particular partition by specifying the --hive-partition-key and --hive-partition-value arguments. The partition value must be a string. Please see the Hive documentation for more details on partitioning.
Question
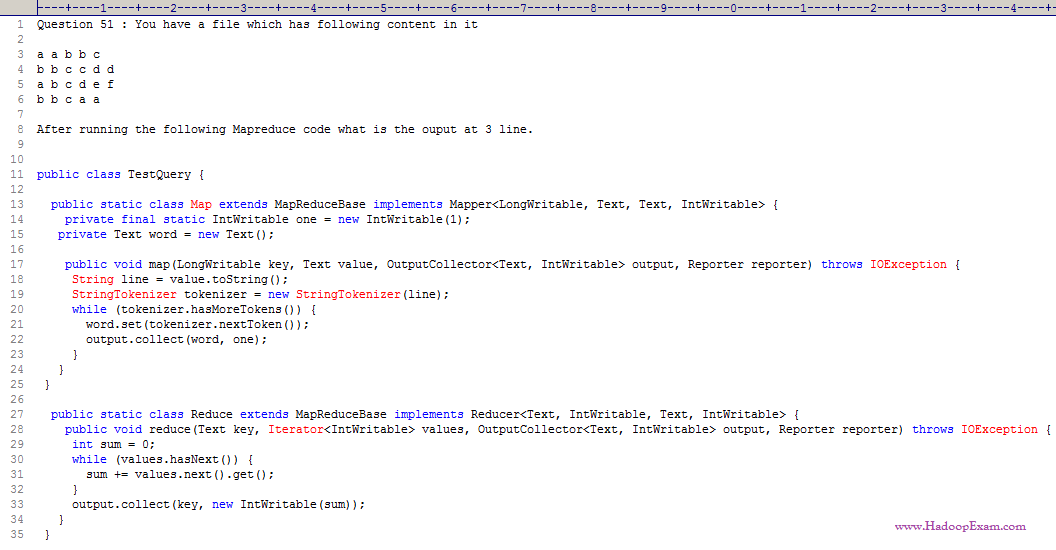
1. a 5
2. 5 a
3. Access Mostly Uused Products by 50000+ Subscribers
4. c 5
5. 5 c
Ans : 4
Exp : This is an example of Word Count code.
Note : Dont Remember Answers, please understand MapReduce in Depth. It is needed to clear live Question Exam Pattern
Question
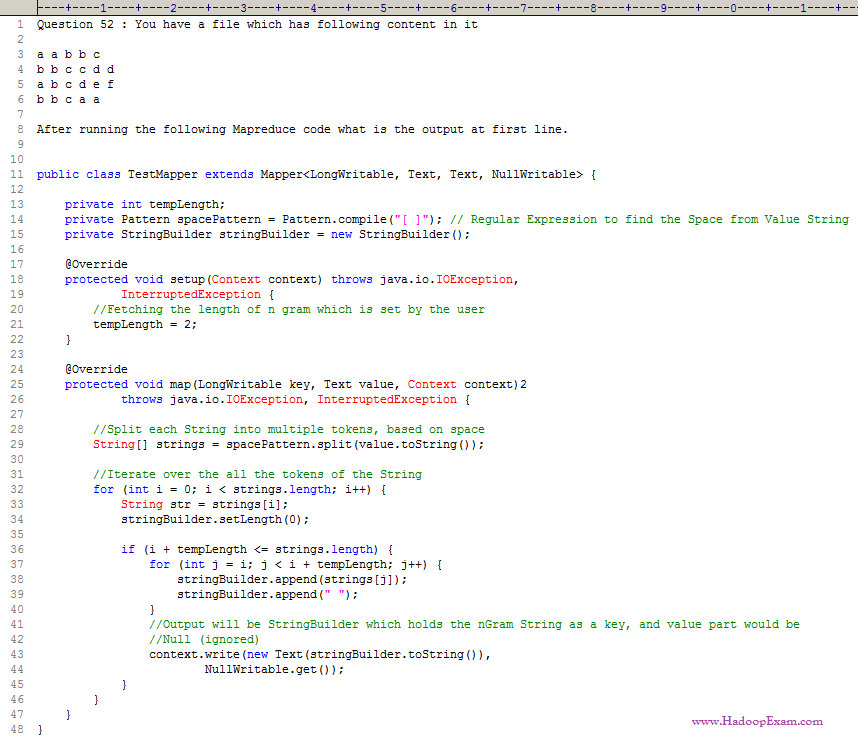
1. a a
2. b b
3. Access Mostly Uused Products by 50000+ Subscribers
4. d d
Ans : 1
Exp : This is an example of BiGram Implementation. Training Module 15 of HadoopExam.com
An n-gram is a contiguous sequence of n items from a given sequence of text or speech.
An n-gram of size 1 is referred to as a "unigram"
size 2 is a "bigram" (or, less commonly, a "digram")
size 3 is a "trigram".
Larger sizes are sometimes referred to by the value of n, e.g., "four-gram", "five-gram", and so on.
Note : Dont Remember Answers, please understand MapReduce in Depth. It is needed to clear live Question Exam Pattern
Question
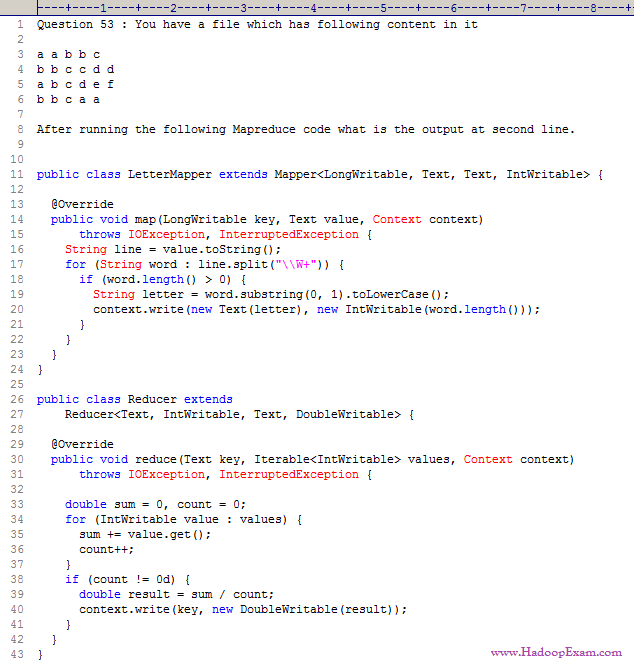
1. a 1
2. b 1
3. Access Mostly Uused Products by 50000+ Subscribers
4. d 1
Ans : 2
Exp : This is the code for calculating average length of each word starting with a unique character.
Each word here is single character, hence the average length for each character is 1 only.
Dont Remember Answers, please understand MapReduce in Depth. It is needed to clear live Question Exam Pattern
Question
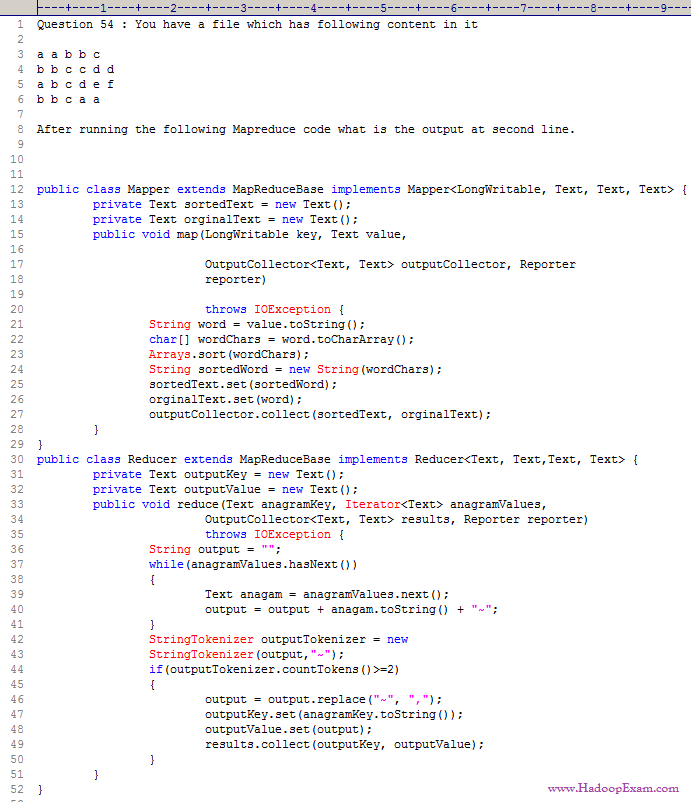
1. a a b b c , b b c a a
2. a a b b c, b b c c d d
3. Access Mostly Uused Products by 50000+ Subscribers
4. b b c a a, b b c a a
Ans : 1 Exp :
The Anagram mapper class gets a word as a line from the HDFS input and sorts the
letters in the word and writes its back to the output collector as
Key : sorted word (letters in the word sorted)
Value: the word itself as the value.
When the reducer runs then we can group anagrams togather based on the sorted key.
The Anagram reducer class groups the values of the sorted keys that came in and
checks to see if the values iterator contains more than one word. if the values
contain more than one word we have spotted a anagram.
Question

1.
2.
3. Access Mostly Uused Products by 50000+ Subscribers