Cloudera Hadoop Administrator Certification Certification Questions and Answer (Dumps and Practice Questions)
Question :
Select the correct statement which applies to "Fair Scheduler"

1. Fair Scheduler allows assigning guaranteed minimum shares to queues
2. queue does not need its full guaranteed share, the excess will not be splitted between other running apps.
3. Access Mostly Uused Products by 50000+ Subscribers
4. 1 and 3
5. 1,2 and 3
Correct Answer : Get Lastest Questions and Answer :
Exp: Fair scheduling is a method of assigning resources to applications such that all apps get, on average, an equal share of resources over time. Hadoop NextGen is capable of scheduling multiple resource types. By default, the Fair Scheduler bases scheduling fairness decisions only on memory. It can be configured to schedule with both memory and CPU, using the notion of Dominant Resource Fairness developed by Ghodsi et al. When there is a single app running, that app uses the entire cluster. When other apps are submitted, resources that free up are assigned to the new apps, so that each app eventually on gets roughly the same amount of resources. Unlike the default Hadoop scheduler, which forms a queue of apps, this lets short apps finish in reasonable time while not starving long-lived apps. It is also a reasonable way to share a cluster between a number of users. Finally, fair sharing can also work with app priorities - the priorities are used as weights to determine the fraction of total resources that each app should get.
The scheduler organizes apps further into "queues", and shares resources fairly between these queues. By default, all users share a single queue, named "default". If an app specifically lists a queue in a container resource request, the request is submitted to that queue. It is also possible to assign queues based on the user name included with the request through configuration. Within each queue, a scheduling policy is used to share resources between the running apps. The default is memory-based fair sharing, but FIFO and multi-resource with Dominant Resource Fairness can also be configured. Queues can be arranged in a hierarchy to divide resources and configured with weights to share the cluster in specific proportions.
In addition to providing fair sharing, the Fair Scheduler allows assigning guaranteed minimum shares to queues, which is useful for ensuring that certain users, groups or production applications always get sufficient resources. When a queue contains apps, it gets at least its minimum share, but when the queue does not need its full guaranteed share, the excess is split between other running apps. This lets the scheduler guarantee capacity for queues while utilizing resources efficiently when these queues don't contain applications.
The Fair Scheduler lets all apps run by default, but it is also possible to limit the number of running apps per user and per queue through the config file. This can be useful when a user must submit hundreds of apps at once, or in general to improve performance if running too many apps at once would cause too much intermediate data to be created or too much context-switching. Limiting the apps does not cause any subsequently submitted apps to fail, only to wait in the scheduler's queue until some of the user's earlier apps finish.
Question : In fair scheduler you have defined a Hierarchical queue named QueueC, whose parent is QueueB and QueueB's parent is QueueA. Which is the
correct name format to reffer the QueueB
1. root.QueueB
2. QueueC.QueueB
3. Access Mostly Uused Products by 50000+ Subscribers
4. leaf.QueueC.QueueB
Correct Answer : Get Lastest Questions and Answer :
Exp: The fair scheduler supports hierarchical queues. All queues descend from a queue named "root". Available resources are distributed among the children of the root queue in the typical fair scheduling fashion. Then, the children distribute the resources assigned to them to their children in the same fashion. Applications may only be scheduled on leaf queues. Queues can be specified as children of other queues by placing them as sub-elements of their parents in the fair scheduler allocation file.
A queue's name starts with the names of its parents, with periods as separators. So a queue named "queue1" under the root queue, would be referred to as "root.queue1", and a queue named "queue2" under a queue named "parent1" would be referred to as "root.parent1.queue2". When referring to queues, the root part of the name is optional, so queue1 could be referred to as just "queue1", and a queue2 could be referred to as just "parent1.queue2".
Additionally, the fair scheduler allows setting a different custom policy for each queue to allow sharing the queue's resources in any which way the user wants. A custom policy can be built by extending org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.SchedulingPolicy. FifoPolicy, FairSharePolicy (default), and DominantResourceFairnessPolicy are built-in and can be readily used.
Certain add-ons are not yet supported which existed in the original (MR1) Fair Scheduler. Among them, is the use of a custom policies governing priority "boosting" over certain apps.
Question : To use the Fair Scheduler first assign the appropriate scheduler class in yarn-site.xml:
Select the correct value which can be placed in the name field.

1. yarn.resourcemanager.scheduler
2. yarn.resourcemanager.class
3. Access Mostly Uused Products by 50000+ Subscribers
4. yarn.scheduler.class
Correct Answer : Get Lastest Questions and Answer :
Exp:
Related Questions
Question
What happens when you run the below job twice , having each input directory as one of the data file called data.csv.
with following command. Assuming there were no output directory exist
hadoop job HadoopExam.jar HadoopExam inputdata_1 output
hadoop job HadoopExam.jar HadoopExam inputdata_2 output
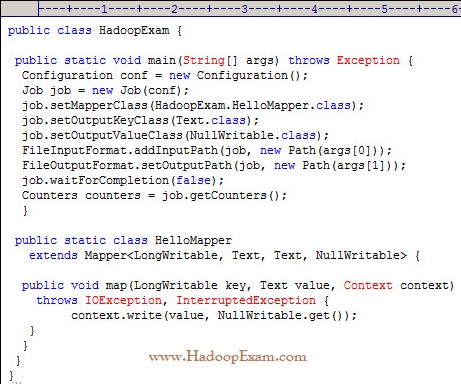
1. Both the job will write the output to output directoy and output will be appended
2. Both the job will fail, saying output directory does not exist.
3. Access Mostly Uused Products by 50000+ Subscribers
4. Both the job will successfully completes and second job will overwrite the output of first.
Ans : 3
Exp : First job will successfully run and second one will fail, because, if (output directory already exist then it will not run
and throws exception, complaining output directory already exist.
Question : You have a an EVENT table with following schema in the Oracle database.
PAGEID NUMBER
USER VARCHAR2
EVENTTIME DATE
PLACE VARCHAR2
Which of the following command creates the correct HIVE table named EVENT

1.
2.
3. Access Mostly Uused Products by 50000+ Subscribers
4.
Ans : 2
Exp : The above is correct because it correctly uses the Sqoop operation to create a Hive table that matches the database table.
Option 3rd is not correct because --hive-table option for Sqoop requires a parameter that names the target table in the database.
Question : Please find out the three correct functionalities of the ResourceManager in YARN or MRv Hadoop Cluster.
1. Monitoring the status of the ApplicationMaster container and restarting on failure
2. Negotiating cluster resource containers from the Scheduler, tracking containter status, and monitoring job progress
3. Monitoring and reporting container status for map and reduce tasks
4. Tracking heartbeats from the NodeManagers
5. Running a scheduler to determine how resources are allocated
6. Archiving the job history information and meta-data
1. 2,3,5
2. 3,4,5
3. Access Mostly Uused Products by 50000+ Subscribers
4. 1,4,5
5. 1,2,6
Question : In MRv YARN Hadoop Infrastructure where does MapReduce intermediate data as an output of Mappers will be stored.
1. In HDFS, in the job's output directory
2. In HDFS, in a temporary directory defined by mapred.tmp.dir
3. Access Mostly Uused Products by 50000+ Subscribers
4. On the underlying filesystem of the ResourceManager node
5. On the underlying filesystem of the local disk of the node on which the Reducer will run, as specified by the ResourceManager
Question : As part of QuickTechie Inc Hadoop Administrator you have upgraded your Hadoop cluster from MRv to MRv, Now you have
to report your manager that, how would you determine the number of Mappers required for a MapReduce job in a new cluster.
Select the correct one form below.
1. The number of Mappers is equal to the number of InputSplits calculated by the client submitting the job
2. The ApplicationMaster chooses the number based on the number of available nodes
3. Access Mostly Uused Products by 50000+ Subscribers
4. NodeManager where the job's HDFS blocks reside
5. The developer specifies the number in the job configuration
Question : Which of the following command will delete the Hive table nameed EVENTINFO
1. hive -e 'DROP TABLE EVENTINFO'
2. hive 'DROP TABLE EVENTINFO'
3. Access Mostly Uused Products by 50000+ Subscribers
4. hive -e 'TRASH TABLE EVENTINFO'

1.
2.
3. Access Mostly Uused Products by 50000+ Subscribers
4.
Ans :1
Exp : Sqoop does not offer a way to delete a table from Hive, although it will overwrite the table definition during
import if the table already exists and --hive-overwrite is specified. The correct HiveQL statement to drop a table
is "DROP TABLE tablename". In Hive, table names are all case insensitives
Question : There is no tables in Hive, which command will
import the entire contents of the EVENT table from
the database into a Hive table called EVENT
that uses commas (,) to separate the fields in the data files?

1.
2.
3. Access Mostly Uused Products by 50000+ Subscribers
4.
Ans :2
Exp : --fields-terminated-by option controls the character used to separate the fields in the Hive table's data files.
Question : You have a MapReduce job which is dependent on two external jdbc jars called ojdbc.jar and openJdbc.jar
which of the following command will correctly oncludes this external jars in the running Jobs classpath
1. hadoop jar job.jar HadoopExam -cp ojdbc6.jar,openJdbc6.jar
2. hadoop jar job.jar HadoopExam -libjars ojdbc6.jar,openJdbc6.jar
3. Access Mostly Uused Products by 50000+ Subscribers
4. hadoop jar job.jar HadoopExam -libjars ojdbc6.jar openJdbc6.jar
Ans : 2
Exp : The syntax for executing a job and including archives in the job's classpath is: hadoop jar -libjars ,[,...]
Question : You have a an EVENT table with following schema in the MySQL database.
PAGEID NUMBER
USER VARCHAR2
EVENTTIME DATE
PLACE VARCHAR2
Now that the database EVENT table has been imported and is stored in the dbimport directory in HDFS,
you would like to make the data available as a Hive table.
Which of the following statements is true? Assume that the data was imported in CSV format.
1. An Hive table can be created with the Hive CREATE command.
2. An external Hive table can be created with the Hive CREATE command that uses the data in the dbimport directory unchanged and in place.
3. Access Mostly Uused Products by 50000+ Subscribers
4. All of the above is correct.
Ans : 2
Exp : An external Hive table can be created that points to any file in HDFS.
The table can be configured to use arbitrary field and row delimeters or even extract fields via regular expressions.
Question : You have Sqoop to import the EVENT table from the database,
then write a Hadoop streaming job in Python to scrub the data,
and use Hive to write the new data into the Hive EVENT table.
How would you automate this data pipeline?
1. Using first Sqoop job and then remaining Part using MapReduce job chaining.
2. Define the Sqoop job, the MapReduce job, and the Hive job as an Oozie workflow job, and define an Oozie coordinator job to run the workflow job daily.
3. Access Mostly Uused Products by 50000+ Subscribers
4. Define the Sqoop job, the MapReduce job, and the Hive job as an Oozie workflow job,
and define an Zookeeper coordinator job to run the workflow job daily.
Ans :2
Exp : In Oozie, scheduling is the function of an Oozie coordinator job.
Oozie does not allow you to schedule workflow jobs
Oozie coordinator jobs cannot aggregate tasks or define workflows;
coordinator jobs are simple schedules of previously defined worksflows.
You must therefore assemble the various tasks into a single workflow
job and then use a coordinator job to execute the workflow job.
Question : Which of the following default character used by Sqoop as field delimiters in the Hive table data file?
1. 0x01
2. 0x001
3. Access Mostly Uused Products by 50000+ Subscribers
4. 0x011
Ans :1
Exp : By default Sqoop uses Hives default delimiters when doing a Hive table export, which is 0x01 (^A)
Question In a Sqoop job Assume $PREVIOUSREFRESH contains a date:time string for the last time the import was run, e.g., '-- ::'.
Which of the following import command control arguments prevent a repeating Sqoop job from downloading the entire EVENT table every day?
1. --incremental lastmodified --refresh-column lastmodified --last-value "$PREVIOUSREFRESH"
2. --incremental lastmodified --check-column lastmodified --last-time "$PREVIOUSREFRESH"
3. Access Mostly Uused Products by 50000+ Subscribers
4. --incremental lastmodified --check-column lastmodified --last-value "$PREVIOUSREFRESH"
Question : You have a log file loaded in HDFS, wich of of the folloiwng operation will allow you to create Hive table using this log file in HDFS.
1. Create an external table in the Hive shell to extract the column data from the logs
2. Create an external table in the Hive shell using org.apache.hadoop.hive.serde2.RegexSerDe to extract the column data from the logs
3. Access Mostly Uused Products by 50000+ Subscribers
4. Create an external table in the Hive shell using org.apache.hadoop.hive.serde2.CSVSerDe to extract the column data from the logs
Ans : 2
Exp : RegexSerDe uses regular expression (regex) to deserialize data.
It doesn't support data serialization. It can deserialize the data using regex and extracts groups as columns.
In deserialization stage, if a row does not match the regex, then all columns in the row will be NULL.
If a row matches the regex but has less than expected groups, the missing groups will be NULL.
If a row matches the regex but has more than expected groups, the additional groups are just ignored.
NOTE: Obviously, all columns have to be strings.
Users can use "CAST(a AS INT)" to convert columns to other types.
NOTE: This implementation is using String, and javaStringObjectInspector.
A more efficient implementation should use UTF-8 encoded Text and writableStringObjectInspector.
We should switch to that when we have a UTF-8 based Regex library.
When building a Hive table from log data, the column widths are not fixed,
so the only way to extract the data is with a regular expression.
The org.apache.hadoop.hive.serde2.RegexSerDe class reads data from a flat file and extracts column information
via a regular expression. The SerDe is specified as part of the table definition when the table is created.
Once the table is created, the LOAD command will add the log files to the table.
Question : You write a Sqoop job to pull the data from the USERS table, but your job pulls the
entire USERS table every day. Assume$LASTIMPORT contains a date:time string for the
last time the import was run, e.g., '2013-09-20 15:27:52'. Which import control
arguments prevent a repeating Sqoop job from downloading the entire USERS table every day?
1. --incremental lastmodified --last-value "$LASTIMPORT"
2. --incremental lastmodified --check-column lastmodified --last-value "$LASTIMPORT"
3. Access Mostly Uused Products by 50000+ Subscribers
4. --incremental "$LASTIMPORT" --check-column lastmodified --last-value "$LASTIMPORT"
Ans : 2
Exp : The --where import control argument lets you specify a select statement to use when importing data,
but it takes a full select statement and must include $CONDITIONS in the WHERE clause.
There is no --since option. The --incremental option does what we want.
Watch Module 22 : http://hadoopexam.com/index.html/#hadoop-training
And refer : http://sqoop.apache.org/docs/1.4.3/SqoopUserGuide.html
Question : Now that you have the USERS table imported into Hive, you need to make the log data available
to Hive so that you can perform a join operation. Assuming you have uploaded the log data into HDFS,
which approach creates a Hive table that contains the log data:
1. Create an external table in the Hive shell using org.apache.hadoop.hive.serde2.SerDeStatsStruct to extract the column data from the logs
2. Create an external table in the Hive shell using org.apache.hadoop.hive.serde2.RegexSerDe to extract the column data from the logs
3. Access Mostly Uused Products by 50000+ Subscribers
4. Create an external table in the Hive shell using org.apache.hadoop.hive.serde2.NullStructSerDe to extract the column data from the logs
Ans : 2
Exp : When building a Hive table from log data, the column widths are not fixed, so the only way to extract the data is with a regular expression. The org.apache.hadoop.hive.serde2.RegexSerDe class reads data from a flat file and extracts column information via a regular expression. The SerDe is specified as part of the table definition when the table is created. Once the table is created, the LOAD command will add the log files to the table. For more information about SerDes in Hive, see How-to: Use a SerDe in Apache Hive and chapter 12 in Hadoop: The Definitive Guide, 3rd Edition in the Tables: Storage Formats section.
Watch Module 12 and 13 : http://hadoopexam.com/index.html/#hadoop-training
And refer : https://hive.apache.org/javadocs/r0.10.0/api/org/apache/hadoop/hive/serde2/package-summary.html
Question :
The cluster block size is set to 128MB. The input file contains 170MB of valid input data
and is loaded into HDFS with the default block size. How many map tasks will be run during the execution of this job?
1. 1
2. 2
3. Access Mostly Uused Products by 50000+ Subscribers
4. 4
Question : For each YARN job, the Hadoop framework generates task log file. Where are Hadoop task log files stored?
1. Cached by the NodeManager managing the job containers, then written to a log directory on the NameNode
2. Cached in the YARN container running the task, then copied into HDFS on job completion
3. Access Mostly Uused Products by 50000+ Subscribers
4. On the local disk of the slave mode running the task