Mapr (HP) Hadoop Developer Certification Questions and Answers (Dumps and Practice Questions)
Question : What of the following can be done using MapReduce?

1. We can count and index group of data
2. Filter the data and fetching top n records
3. Access Mostly Uused Products by 50000+ Subscribers
4. 2,3
5. 1,2,3
Correct Answer : Get Lastest Questions and Answer :
Explanation:
Question : Select the correct order of the MapReduce program flow
A. Data Fed from input file to Mapper
C. shuffling of data
B. transformation of data
D. data written to the file
1. D,B,C,A
2. C,D,B,A
3. Access Mostly Uused Products by 50000+ Subscribers
4. B,A,C,D
5. A,D,B,C
Correct Answer : Get Lastest Questions and Answer :
Explanation:
Question : You have a ma () method in a Mapper class as below.
public void map(LongWritable key, Text value, Context context){}
What is the use of context object here?
A. It keeps Job configuration information
B. It gives currently running mapper to input split
C. It only contains the next record pointer to input split
D. A,B
E. A,B,C
1. It keeps Job configuration information
2. It gives currently running mapper to input split
3. Access Mostly Uused Products by 50000+ Subscribers
4. 1,2
5. 1,2,3
Correct Answer : Get Lastest Questions and Answer :
Explanation: Context object: allows the Mapper/Reducer to interact with the rest of the Hadoop system. It includes configuration data for the
job as well as interfaces which allow it to emit output.
Applications can use the Context:
to report progress
to set application-level status messages
update Counters
indicate they are alive
to get the values that are stored in job configuration across map/reduce phase.
context which encapsulates the Hadoop job running context (configura3on, record reader, record writer, status reporter, input split, and output committer)
The new API makes extensive use of Context objects that allow the user code to communicate with MapRduce system.
It unifies the role of JobConf, OutputCollector, and Reporter from old API.
Related Questions
Question

1. This job will throw run time exception because no Mapper and Reducer Provided
2. Job will run and produce each line is an integer followed by a tab character, followed by the original line
3. Access Mostly Uused Products by 50000+ Subscribers
4. Job will run and produce original line in output files
Ans : 2
Exp : Each line is an integer followed by a tab character, followed by the original weather
data record. An InputFormat for plain text files. Files are broken into lines.
Either linefeed or carriage-return are used to signal end of line. Keys are the position in the file, and values are the line of text..
Because default input format is a TextInputFormat
Question

1. 1
2. 2
3. Access Mostly Uused Products by 50000+ Subscribers
4. 4
5. No output will be produced, because default Mapper and Reducer class is used
Ans : 3
Exp :The default mapper is just the Mapper class, which writes the input key and value unchanged
to the output, The default partitioner is HashPartitioner, which hashes a records key to determine
which partition the record belongs in. Each partition is processed by a reduce task, so
the number of partitions is equal to the number of reduce tasks for the job, The default reducer is Reducer,
again a generic type, which simply writes all its input to its output. If proper input is provided then Number of
Output files is equal to number of reducers.
Question

1. 1
2. 2
3. Access Mostly Uused Products by 50000+ Subscribers
Ans : 1
Exp : As you can see in 2nd option reducer does not have calculated max value for the year.
And in the 3rd option in the Map function, in the output value as key and year as a value, which does not fit
as per our algorithm. We have to get same year value in the same reducer to calculate maximum value. Hence
we have to have year as a key and value in the value field.
Question

1. 1,2,3,4
2. 2,1,3,4
3. Access Mostly Uused Products by 50000+ Subscribers
4. 1,4,3,2
Ans : 3
Exp : Maps input key/value pairs to a set of intermediate key/value pairs.
Maps are the individual tasks which transform input records into a intermediate records. The transformed intermediate records need not be of the same type as the input records. A
given input pair may map to zero or many output pairs.
The Hadoop Map-Reduce framework spawns one map task for each InputSplit generated by the InputFormat for the job. Mapper implementations can access the Configuration for the job via
the JobContext.getConfiguration().
The framework first calls setup(org.apache.hadoop.mapreduce.Mapper.Context), followed by map(Object, Object, Context) for each key/value pair in the InputSplit. Finally
cleanup(Context) is called.
All intermediate values associated with a given output key are subsequently grouped by the framework, and passed to a Reducer to determine the final output. Users can control the
sorting and grouping by specifying two key RawComparator classes.
The Mapper outputs are partitioned per Reducer. Users can control which keys (and hence records) go to which Reducer by implementing a custom Partitioner.
Users can optionally specify a combiner, via Job.setCombinerClass(Class), to perform local aggregation of the intermediate outputs, which helps to cut down the amount of data
transferred from the Mapper to the Reducer.
Applications can specify if and how the intermediate outputs are to be compressed and which CompressionCodecs are to be used via the Configuration.
If the job has zero reduces then the output of the Mapper is directly written to the OutputFormat without sorting by keys.
Question :
If you have to use distributed cache for file
distribution then which is the right
place in above method to read the file

1. create new static method in the mapper and read the file in a variable and use that variable in map method
2. read the file in a setup() method and store in a variable and use that variable in map method
3. Access Mostly Uused Products by 50000+ Subscribers
4. read the file in a map() method and use that directly in map method
Ans:2
Question :
At line number 6,
ABC should be replaced by which
of the following class to this
MapReduce Driver to work correctly

1. ABC. should be removed and nothing else is required.
2. Tool class
3. Access Mostly Uused Products by 50000+ Subscribers
4. Runner
5. Thread
Ans : 3
Exp : A utility to help run Tools.
ToolRunner can be used to run classes implementing Tool interface.
It works in conjunction with GenericOptionsParser to parse the generic hadoop command line arguments
and modifies the Configuration of the Tool. The application-specific options are passed along without being modified.
Question :
If we replace NullWritable.class
with new Text((String)null) at line number 15,
then which is correct
1. Both are same, program will give the same result
2. It will throw NullPointerException
3. Access Mostly Uused Products by 50000+ Subscribers
Ans : 3
Exp : Singleton Writable with no data.
NullWritable is a special type of Writable, as it has a zero length serialization. No bytes are written to, or read from, the stream.
It is used as a placeholder for example, in MapReduce, a key or a value can be declared as a NullWritable when you dont need to
use that position it effectively stores a constant empty value.
NullWritable can also be useful as a key in SequenceFile when you want to store a list of values,
as opposed to key value pairs. It is an immutable singleton the instance can be retrieved by calling NullWritable.get()
Question

1. A
2. B
3. Access Mostly Uused Products by 50000+ Subscribers
Ans : 1
Exp : Check the URL http://oozie.apache.org/docs/3.1.3-incubating/WorkflowFunctionalSpec.html
Question Which of the following is possible as part of Oozie workflow

1. Running Multiple Jobs in Parallel
2. Output of all the Parallel Jobs can be used as an Input to next job
3. Access Mostly Uused Products by 50000+ Subscribers
4. You can include Hive Jobs as well as Pig Jobs as part of OOzie workflow
5. All 1,2 and 5 are correct
Ans : 5
Exp : Check the URL http://oozie.apache.org/docs/3.1.3-incubating/WorkflowFunctionalSpec.html
Question Select the correct statement for OOzie workflow
1. OOzie workflow runs on a server which is typically outside of Hadoop Cluster
2. OOzie workflow definition are submitted via HTTP.
3. Access Mostly Uused Products by 50000+ Subscribers
4. All 1,2 and 3 are correct
5. Only 1 and 3 are correct
Ans : 4
Exp : Check the URL http://oozie.apache.org/docs/3.1.3-incubating/WorkflowFunctionalSpec.html
Question Which of the following is correct for the OOzie control nodes
1. fork splits the execution path
2. join waits for all concurrent execution paths to complete before proceeding
3. Access Mostly Uused Products by 50000+ Subscribers
4. Only 1 and 3 are correct
5. All 1,2 and 3 are correct
Ans : 5
Exp : Check the URL http://oozie.apache.org/docs/3.1.3-incubating/WorkflowFunctionalSpec.html
Question Which of the following is correct for the OOzie control nodes
1. fork splits the execution path
2. join waits for all concurrent execution paths to complete before proceeding
3. Access Mostly Uused Products by 50000+ Subscribers
4. Only 1 and 3 are correct
5. All 1,2 and 3 are correct
Ans : 5
Exp : Check the URL http://oozie.apache.org/docs/3.1.3-incubating/WorkflowFunctionalSpec.html
Question

1. A
2. B
3. Access Mostly Uused Products by 50000+ Subscribers
Ans : 3
Exp : Check the URL http://oozie.apache.org/docs/3.1.3-incubating/WorkflowFunctionalSpec.html
Question

1. A
2. B
3. Access Mostly Uused Products by 50000+ Subscribers
Ans : 2
Exp : Check the URL http://oozie.apache.org/docs/3.1.3-incubating/WorkflowFunctionalSpec.html
Question Select the correct statement which applies to Distributed cache
1. Transfer happens behind the scenes before any task is executed
2. Distributed Cache is read/only
3. Access Mostly Uused Products by 50000+ Subscribers
4. As soon as tasks starts the Cached file is copied from Central Location to Task Node.
5. 1,2 and 3 are correct
Ans : 5
Question

1. 1
2. 2
3. Access Mostly Uused Products by 50000+ Subscribers
Ans : 1
Question Which is the correct statement for RecordReader
1. RecordReader, typically, converts the byte-oriented view of the input,
provided by the InputSplit, and presents a record-oriented view
for the Mapper and Reducer tasks for processing.
2. It assumes the responsibility of processing record boundaries and presenting the tasks with keys and values.
3. Access Mostly Uused Products by 50000+ Subscribers
4. 1,3 are correct
5. 1,2 are correct
Ans : 5
Question

1. A
2. B
3. Access Mostly Uused Products by 50000+ Subscribers
Ans : 1
Question

1. A
2. B
3. Access Mostly Uused Products by 50000+ Subscribers
Ans : 1
Question

1. A
2. B
3. Access Mostly Uused Products by 50000+ Subscribers
Ans : 1
Question

1. A
2. B
3. Access Mostly Uused Products by 50000+ Subscribers
Ans : 2
Question

1. A
2. B
3. Access Mostly Uused Products by 50000+ Subscribers
Ans : 3
Question
Suppose you have input file that contains the following data
Name:Dash
Age:27
Name:Nish
Age:29
.
.
.
.
And you want to produce the two file as an output of MapReduce Job then which is the Best Output format class you will use and override
1. TextOutputFormat
2. SequenceFileOutputFormat
3. Access Mostly Uused Products by 50000+ Subscribers
4. MultipleTextOutputFormat
Ans : 4
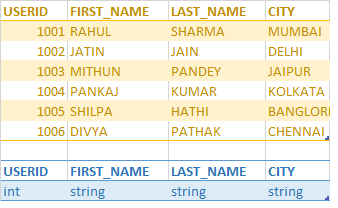
Question : You have millions of user in QuickTechie.com website as sample given in the image.
This all information is stored in the Backend MySQL database. Which of the given command will
help you to copy this MAINPROFILE table into the Hive MAINPROFILE table,
Which Hadoop command creates a Hive table called LOGIN equivalent to the LOGIN database table?
1. sqoop create-hive-table --connect jdbc:mysql://dbhost/db --table MAINPROFILE
2. hive -e 'CREATE TABLE MAINPROFILE (USERID int, FIRST_NAME string, LAST_NAME string, CITY string);'
3. Access Mostly Uused Products by 50000+ Subscribers
4. sqoop create-hive-table --connect jdbc:mysql://dbhost/db --table MAINPROFILE --hive-table
5. sqoop import --hive-import --connect jdbc:mysql://dbhost/db --table MAINPROFILE --hive-create-table
Ans : 1
Exp : Here, you import all of the Service Order Database directly from MySQL into Hive and run a HiveQL query against the newly imported database on Apache Hadoop. The following
listing shows you how it's done.hive> create database serviceorderdb;
hive> use serviceorderdb;
$ sqoop import --connect jdbc:mysql://localhost/serviceorderdb --username root -P --table productinfo --hive-import --hive-table serviceorderdb.productinfo -m 1
$ sqoop import --connect jdbc:mysql://localhost/serviceorderdb --username root -P --table customercontactinfo --hive-import --hive-table serviceorderdb.customercontactinfo -m 1
13/08/16 17:21:35 INFO hive.HiveImport: Hive import complete.
$ sqoop import --connect jdbc:mysql://localhost/serviceorderdb --username root -P --table serviceorders --hive-import --hive-table serviceorderdb.serviceorders -m 1
When the import operations are complete, you run the show tables command to list the newly imported tables (see the following listing):
hive> show tables;
customercontactinfo
productinfo
serviceorders
Then run a Hive query to show which Apache Hadoop technologies have open service orders in the database: hive> SELECT productdesc FROM productinfo
> INNER JOIN serviceorders > ON productinfo.productnum = serviceorders.productnum;
HBase Support Product
Hive Support Product
Sqoop Support Product
Pig Support Product
You can confirm the results. You have four open service orders on the products in bold. The Sqoop Hive import operation worked, and now the service company can leverage Hive to
query, analyze, and transform its service order structured data. Additionally, the company can now combine its relational data with other data types (perhaps unstructured) as part of
any new Hadoop analytics applications. Many possibilities now exist with Apache Hadoop being part of the overall IT strategy!% hive -e 'CREATE TABLE MAINPROFILE ((USERID int,
FIRST_NAME string, LAST_NAME string, CITY string);' % hive -e 'CREATE EXTERNAL TABLE IF NOT EXISTS MAINPROFILE (USERID int, FIRST_NAME string, LAST_NAME string, CITY string)' Both of
the above both create the time column as a data type, which cannot store the information from the time field about the time. The hour, minute, and second information would be
dropped.
% sqoop create-hive-table --connect jdbc:mysql://dbhost/db --table MAINPROFILE
The above is correct because it correctly uses the Sqoop operation to create a Hive table that matches the database table.
% sqoop create-hive-table --connect jdbc:mysql://dbhost/db --table MAINPROFILE --hive-table
The above is incorrect because the --hive-table option for Sqoop requires a parameter that names the target table in the database.
% sqoop import --hive-import --connect jdbc:mysql://dbhost/db --table MAINPROFILE --hive-create-table
The above is incorrect because the Sqoop import command has no --hive-create-table option
Question : You have millions of user in QuickTechie.com website as sample given in the image.
This all information is stored in the Backend MySQL database. Which of the given command will
help you to copy this MAINPROFILE table into the Hive MAINPROFILE table,
Which command will delete the Hive LOGIN table you just created MAINPROFILE ?
1. hive -e 'DELETE TABLE MAINPROFILE'
2. hive -e 'TRUNCATE TABLE MAINPROFILE'
3. Access Mostly Uused Products by 50000+ Subscribers
4. All 1,2 and 3 are similar
5. Once table is created it can not be deleted
Ans : 3
Exp : DROP TABLE [IF EXISTS] table_name DROP TABLE removes metadata and data for this table. The data is actually moved to the .Trash/Current directory if Trash is configured. The
metadata is completely lost. When dropping an EXTERNAL table, data in the table will NOT be deleted from the file system. When dropping a table referenced by views, no warning is
given (the views are left dangling as invalid and must be dropped or recreated by the user). Otherwise, the table information is removed from the metastore and the raw data is
removed as if by 'hadoop dfs -rm'. In many cases, this results in the table data being moved into the user's .Trash folder in their home directory; users who mistakenly DROP TABLEs
mistakenly may thus be able to recover their lost data by re-creating a table with the same schema, re-creating any necessary partitions, and then moving the data back into place
manually using Hadoop. This solution is subject to change over time or across installations as it relies on the underlying implementation; users are strongly encouraged not to drop
tables capriciously. In Hive 0.7.0 or later, DROP returns an error if the table doesn't exist, unless IF EXISTS is specified or the configuration variable
hive.exec.drop.ignorenonexistent is set to true. Sqoop does not offer a way to delete a table from Hive, although it will overwrite the table definition during import if the table
already exists and --hive-overwrite is specified. The correct HiveQL statement to drop a table is"DROP TABLE tablename". In Hive, table names are all case insensitive.
Its suggested , please read Hive Language Document from : https://cwiki.apache.org/confluence/display/Hive/LanguageManual
Question : You have millions of user in QuickTechie.com website as sample given in the image.
This all information is stored in the Backend MySQL database. Which of the given command will
help you to copy this MAINPROFILE table into the Hive MAINPROFILE table,
Which command will delete the Hive MAINPROFILE table you just created ?
Select the command that will delete all the rows of with userid 1000 from Hive MAINPROFILE table,
where userid column is partitioned you just created?
1. TRUNCATE TABLE MAINPROFILE WHERE userid = 1000;
2. TRUNCATE TABLE MAINPROFILE PARTITION (userid = 1000);
3. Access Mostly Uused Products by 50000+ Subscribers
4. DELETE FROM MAINPROFILE WHERE PARTITION = 1000;
Ans : 2
Exp : Hive is a good tool for performing queries on large datasets, especially datasets that require full table scans. But quite often there are instances where users need to filter
the data on specific column values. Generally, Hive users know about the domain of the data that they deal with. With this knowledge they can identify common columns that are
frequently queried in order to identify columns with low cardinality which can be used to organize data using the partitioning feature of Hive. In non-partitioned tables, Hive would
have to read all the files in a table's data directory and subsequently apply filters on it. This is slow and expensive-especially in cases of large tables.
The concept of partitioning is not new for folks who are familiar with relational databases. Partitions are essentially horizontal slices of data which allow larger sets of data to
be separated into more manageable chunks. TRUNCATE TABLE table_name [PARTITION partition_spec];In Hive, partitioning is supported for both managed and external tables in the table
definition as seen below. CREATE TABLE REGISTRATION DATA ( userid BIGINT, First_Name STRING,
Last_Name STRING, address1 STRING, address2 STRING, city STRING, zip_code STRING,
state STRING )
PARTITION BY ( REGION STRING, COUNTRY STRING )
partition_spec:
: (partition_col = partition_col_value, partition_col = partiton_col_value, ...)
Removes all rows from a table or partition(s). Currently target table should be native/managed table or exception will be thrown. User can specify partial partition_spec for
truncating multiple partitions at once and omitting partition_spec will truncate all partitions in the table.
Its suggested , please read Hive Language Document from : https://cwiki.apache.org/confluence/display/Hive/LanguageManual
Question : You have millions of user in QuickTechie.com website as sample given in the image.
This all information is stored in the Backend MySQL database. Which of the given command will
help you to copy this MAINPROFILE table into the Hive MAINPROFILE table,
Which command will import the entire contents of the MAINPROFILE table
from the database into a Hive table called MAINPROFILE that uses commas (,) to separate the fields in the data files?
1. hive import --connect jdbc:mysql://dbhost/db --table MAINPROFILE --terminated-by ',' --hive-import
2. hive import --connect jdbc:mysql://dbhost/db --table MAINPROFILE --fields-terminated-by ',' --hive-import
3. Access Mostly Uused Products by 50000+ Subscribers
4. sqoop import --connect jdbc:mysql://dbhost/db --table MAINPROFILE --fields-terminated-by ',' --hive-import
Ans : 4 Exp : Here, you import all of the Service Order Database directly from MySQL into Hive and run a HiveQL query against the newly imported database on Apache Hadoop. The
following listing shows you how it's done.hive> create database serviceorderdb;
hive> use serviceorderdb;
$ sqoop import --connect jdbc:mysql://localhost/serviceorderdb --username root -P --table productinfo --hive-import --hive-table serviceorderdb.productinfo -m 1
$ sqoop import --connect jdbc:mysql://localhost/serviceorderdb --username root -P --table customercontactinfo --hive-import --hive-table serviceorderdb.customercontactinfo -m 1
13/08/16 17:21:35 INFO hive.HiveImport: Hive import complete.
$ sqoop import --connect jdbc:mysql://localhost/serviceorderdb --username root -P --table serviceorders --hive-import --hive-table serviceorderdb.serviceorders -m 1
When the import operations are complete, you run the show tables command to list the newly imported tables (see the following listing):
hive> show tables;
customercontactinfo
productinfo
serviceorders
Then run a Hive query to show which Apache Hadoop technologies have open service orders in the database: hive> SELECT productdesc FROM productinfo
> INNER JOIN serviceorders > ON productinfo.productnum = serviceorders.productnum;
HBase Support Product
Hive Support Product
Sqoop Support Product
Pig Support Product You can confirm the results. You have four open service orders on the products in bold. The Sqoop Hive import operation worked, and now the service company can
leverage Hive to query, analyze, and transform its service order structured data. Additionally, the company can now combine its relational data with other data types (perhaps
unstructured) as part of any new Hadoop analytics applications. Many possibilities now exist with Apache Hadoop being part of the overall IT strategy!% hive -e 'CREATE TABLE
MAINPROFILE ((USERID int, FIRST_NAME string, LAST_NAME string, CITY string);' % hive -e 'CREATE EXTERNAL TABLE IF NOT EXISTS MAINPROFILE (USERID int, FIRST_NAME string, LAST_NAME
string, CITY string)' Both of the above both create the time column as a data type, which cannot store the information from the time field about the time. The hour, minute, and
second information would be dropped. Sqoop import to a Hive table requires the import option followed by the --table option to specify the database table name and the --hive-import
option. If --hive-table is not specified, the Hive table will have the same name as the imported database table. If --hive-overwrite is specified, the Hive table will be overwritten
if it exists. If the --fields-terminated-by option is set, it controls the character used to separate the fields in the Hive table's data files.
Watch Hadoop Professional training Module : 22 by www.HadoopExam.com
http://hadoopexam.com/index.html/#hadoop-training
Question : For transferring all the stored user profile of QuickTechie.com websites in Oracle Database under table called MAIN.PROFILE
to HDFS you wrote a Sqoop job, Assume $LASTFETCH contains a date:time string for the last time the import was run, e.g., '2015-01-01 12:00:00'.
Finally you have the MAIN.PROFILE table imported into Hive using Sqoop, you need to make this log data available to Hive to perform a join operation.
Assuming you have uploaded the MAIN.PROFILE.log into HDFS, select the appropriate way to creates a Hive table that contains the log data:

1. Create an external table in the Hive shell using org.apache.hadoop.hive.serde2.SerDeStatsStruct to extract the column data from the logs
2. Create an external table in the Hive shell using org.apache.hadoop.hive.serde2.RegexSerDe to extract the column data from the logs
3. Access Mostly Uused Products by 50000+ Subscribers
4. Create an external table in the Hive shell using org.apache.hadoop.hive.serde2.NullStructSerDe to extract the column data from the logs
Ans : 2
Exp : External Tables
The EXTERNAL keyword lets you create a table and provide a LOCATION so that Hive does not use a default location for this table. This comes in handy if you already have data
generated. When dropping an EXTERNAL table, data in the table is NOT deleted from the file system.
An EXTERNAL table points to any HDFS location for its storage, rather than being stored in a folder specified by the configuration property hive.metastore.warehouse.dir.
CREATE EXTERNAL TABLE page_view(viewTime INT, userid BIGINT,
page_url STRING, referrer_url STRING,
ip STRING COMMENT 'IP Address of the User',
country STRING COMMENT 'country of origination')
COMMENT 'This is the staging page view table'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\054'
STORED AS TEXTFILE
LOCATION '(hdfs_location)';
You can use the above statement to create a page_view table which points to any hdfs location for its storage. But you still have to make sure that the data is delimited as specified
in the CREATE statement above.When building a Hive table from log data, the column widths are not fixed, so the only way to extract the data is with a regular expression. The
org.apache.hadoop.hive.serde2.RegexSerDe class reads data from a flat file and extracts column information via a regular expression. The SerDe is specified as part of the table
definition when the table is created. Once the table is created, the LOAD command will add the log files to the table. For more information about SerDes in Hive, see How-to: Use a
SerDe in Apache Hive and chapter 12 in Hadoop: The Definitive Guide, 3rd Edition in the Tables: Storage Formats section. RegexSerDe uses regular expression (regex) to
serialize/deserialize.
It can deserialize the data using regex and extracts groups as columns. It can also serialize the row object using a format string. In deserialization stage, if a row does not
match the regex, then all columns in the row will be NULL. If a row matches the regex but has less than expected groups, the missing groups will be NULL. If a row matches the
regex but has more than expected groups, the additional groups are just ignored. In serialization stage, it uses java string formatter to format the columns into a row. If the
output type of the column in a query is not a string, it will be automatically converted to String by Hive.
Watch Module 12 and 13 : http://hadoopexam.com/index.html/#hadoop-training
And refer : https://hive.apache.org/javadocs/r0.10.0/api/org/apache/hadoop/hive/serde2/package-summary.html
Question : You have written an ETL job, however while processing the data it also depend on some other classes, which is packaged under two separate jars TimeSeries.jar
and other one is HOC.jar.
Now you want these two jars should also be distributed and must be used during the Job Executions. Refer the sample snippet of driver code as below which is bundled under the
QTETL.jar file.
Select the correct command which execute QTETLDataLoad MapReduce jobs with the HOC.jar and TimeSeries.jar will be distributed to the node where job will be executed.
public class QTETLDataLoad extends Configured implements Tool {
public static void main(final String[] args) throws Exception {
Configuration conf = new Configuration();
int res = ToolRunner.run(conf, new Example(), args);
System.exit(res); }
public int run(String[] args) throws Exception { Job job = new Job(super.getConf());
//remove the detailed code for keeping the code short
job.waitForCompletion(true);
}}
1. hadoop jar QTETL.jar Example -includes TimeSeries.jar , HOC.jar
2. hadoop jar QTETL.jar Example -libjars TimeSeries.jar , HOC.jar
3. Access Mostly Uused Products by 50000+ Subscribers
4. hadoop jar QTETL.jar Example -dist TimeSeries.jar , HOC.jar
5. hadoop jar QTETL.jar Example -classpath TimeSeries.jar , HOC.jar
Ans : 2 Exp : When working with MapReduce one of the challenges that is encountered early-on is determining how to make your third-part JAR's available to the map and reduce tasks.
One common approach is to create a fat jar, which is a JAR that contains your classes as well as your third-party classes . A more elegant solution is to take advantage of the
libjars option in the hadoop jar command. Here I'll go into detail on the three steps required to make this work. Add libjars to the options It can be confusing to know exactly where
to put libjars when running the hadoop jar command. The following example shows the correct position of this option:
$ export LIBJARS=/path/jar1,/path/jar2
$ hadoop jar my-example.jar com.example.MyTool -libjars ${LIBJARS} -mytoolopt value
It's worth noting in the above example that the JAR's supplied as the value of the libjar option are comma-separated, and not separated by your O.S. path delimiter (which is how a
Java classpath is delimited). You may think that you're done, but often times this step alone may not be enough - read on for more details!
Make sure your code is using GenericOptionsParser The Java class that's being supplied to the hadoop jar command should use the GenericOptionsParser class to parse the options being
supplied on the CLI. The easiest way to do that is demonstrated with the following code, which leverages the ToolRunner class to parse-out the options:
public static void main(final String[] args) throws Exception {
Configuration conf = new Configuration();
int res = ToolRunner.run(conf, new com.example.MyTool(), args);
System.exit(res); } It is crucial that the configuration object being passed into the ToolRunner.run method is the same one that you're using when setting-up your job. To guarantee
this, your class should use the getConf() method defined in Configurable (and implemented in Configured) to access the configuration:
public class SmallFilesMapReduce extends Configured implements Tool {
public final int run(final String[] args) throws Exception {
Job job = new Job(super.getConf());
job.waitForCompletion(true);
return ...; }
If you don't leverage the Configuration object supplied to the ToolRunner.run method in your MapReduce driver code, then your job won't be correctly configured and your third-party
JAR's won't be copied to the Distributed Cache or loaded in the remote task JVM's. The syntax for executing a job and including archives in the job's classpath is: hadoop jar
-libjars ,[,...]
Watch Hadoop Training Module 9 from : http://hadoopexam.com/index.html/#hadoop-training
Question : From the Acmeshell.com website you have your all the data stored in Oracle database table called MAIN.PROFILES table. In HDFS you already
have your Apache WebServer log file stored called users_activity.log . Now you want to combine/join both the data users_activity.log file and MAIN.PROFILES
table. Initially, you want to import the table data from the database into HDFS. Select the most suitable way to copy all of the data in the MAIN.PROFILES table into a file in HDFS?
1. Use Hive with the Oracle connector to import the database table to HDFS.
2. Use Sqoop with the Oracle connector to import the database table to HDFS.
3. Access Mostly Uused Products by 50000+ Subscribers
4. Use Custom SerDe with the Oracle connector to import the database table to HDFS.
5. None of the above (It is not possible)
Ans : 2 Exp : training Module : 22 Apache Sqoop (SQL To Hadoop) by http://hadoopexam.com/index.html/#hadoop-training
$ sqoop import (generic-args) (import-args)
$ sqoop-import (generic-args) (import-args)
While the Hadoop generic arguments must precede any import arguments, you can type the import arguments in any order with respect to one another.
Argument Description
--connect jdbc-uri Specify JDBC connect string
--connection-manager class-name Specify connection manager class to use
--driver class-name Manually specify JDBC driver class to use
--hadoop-mapred-home dir Override $HADOOP_MAPRED_HOME
--help Print usage instructions
--password-file Set path for a file containing the authentication password
-P Read password from console
--password password Set authentication password
--username username Set authentication username
--verbose Print more information while working
--connection-param-file filename Optional properties file that provides connection parameters
The most efficient approach will be to use Sqoop with the MySQL connector. Beneath the covers it uses the mysqldump command to achieve rapid data export in parallel. The next most
efficient approach will be to use Sqoop with the JDBC driver. The JDBC driver uses a JDBC connection, which is not as efficient as mysqldump. The next most efficient approach will
be to use the DBInputFormat class. The results will be similar to using Sqoop with the JDBC driver, but the Sqoop jobs are more optimized. The least efficient approach will be to
usemysqldump directly as the dump and subsequent upload are not parallelized operations. There is noPigJDBCConnector class.
Further Reading
For more information on Sqoop, see the Sqoop Users Guide or chapter 15 in Hadoop: The Definitive Guide, 3rd Edition. For information about using the DBInputFormat class, see
Database Access with Apache Hadoop. For information about Hive, see the Hive Wiki or chapter 12 in Hadoop: The Definitive Guide, 3rd Edition.
Question : From the Acmeshell.com website you have your all the data stored in Oracle database table called MAIN.PROFILES table. In HDFS you already
have your Apache WebServer log file stored called users_activity.log . Now you want to combine/join both the data users_activity.log file and MAIN.PROFILES
table. Initailly, you want to import the table data from the database into HDFS. Now that the database MAIN.PROFILES table has been imported (CSV format)
in the /user/acmeshell directory in HDFS. Select the most suitable way so that this data will be available as Hive table.

1. By default this data will be available in Hive table format as already loaded in HDFS.
2. You have to create internal Hive table
3. Access Mostly Uused Products by 50000+ Subscribers
4. Both 1 and 2 are possible way.
Ans : 3 Exp : Watch Module 12 and 13 for full Hive Internal and External table from : http://hadoopexam.com/index.html/#hadoop-training
Hive has a relational database on the master node it uses to keep track of state. For instance, when you CREATE TABLE FOO(foo string) LOCATION 'hdfs://tmp/';, this table schema is
stored in the database. If you have a partitioned table, the partitions are stored in the database(this allows hive to use lists of partitions without going to the filesystem and
finding them, etc). These sorts of things are the 'metadata'. When you drop an internal table, it drops the data, and it also drops the metadata. When you drop an external table, it
only drops the meta data. That means hive is ignorant of that data now. It does not touch the data itself.
An external Hive table can be created that points to any file in HDFS. The table can be configured to use arbitrary field and row delimiters or even extract fields via regular
expressions.
Question : From the Acmeshell.com website you have your all the data stored in Oracle database table called MAIN.PROFILES table. In HDFS you already
have your Apache WebServer log file stored called users_activity.log . Now you want to combine/join both the data users_activity.log file and MAIN.PROFILES
table. Initially, you want to import the table data from the database into HDFS and used the Sqoop tool for doing this. You already have one of the Python script
to scrub this joined data. After scrubbing this data you will use Hive to write output in a new table called MAIN.SCRUBBED_PROFILE
Select the suitable way of doing this activity.
1. Using the OOZIE workflow engine you have to create workflow with Sqoop job, the MapReduce job, and the Hive, and schedule this workflow job to run daily.
2. Using the OOZIE workflow engine you have to create workflow with Sqoop job, the MapReduce job, and the Hive job, and define an MapReduce chaining job to run this workflow job daily.
3. Access Mostly Uused Products by 50000+ Subscribers
4. Using the OOZIE workflow engine you have to create workflow with Sqoop job, the MapReduce job, and the Hive job , and define an Oozie coordinator job to run the workflow daily.
5. None of the above.
Ans : 4
Exp : Users typically run map-reduce, hadoop-streaming, hdfs and/or Pig jobs on the grid. Multiple of these jobs can be combined to form a workflow job. Oozie, Hadoop Workflow System
defines a workflow system that runs such jobs. Commonly, workflow jobs are run based on regular time intervals and/or data availability. And, in some cases, they can be triggered by
an external event. Expressing the condition(s) that trigger a workflow job can be modeled as a predicate that has to be satisfied. The workflow job is started after the predicate is
satisfied. A predicate can reference to data, time and/or external events. In the future, the model can be extended to support additional event types. It is also necessary to connect
workflow jobs that run regularly, but at different time intervals. The outputs of multiple subsequent runs of a workflow become the input to the next workflow. For example, the
outputs of last 4 runs of a workflow that runs every 15 minutes become the input of another workflow that runs every 60 minutes. Chaining together these workflows result it is
referred as a data application pipeline.The Oozie Coordinator system allows the user to define and execute recurrent and interdependent workflow jobs (data application pipelines).
Real world data application pipelines have to account for reprocessing, late processing, catchup, partial processing, monitoring, notification and SLAs. This document defines the
functional specification for the Oozie Coordinator system.Oozie does not allow you to schedule workflow jobs; in Oozie, scheduling is the function of an Oozie coordinator job.
Conversely, Oozie coordinator jobs cannot aggregate tasks or define workflows; coordinator jobs are simple schedules of previously defined worksflows. You must therefore assemble the
various tasks into a single workflow job and then use a coordinator job to execute the workflow job. For more information about Oozie.
Here are some typical use cases for the Oozie Coordinator Engine.
You want to run your workflow once a day at 2PM (similar to a CRON).
You want to run your workflow every hour and you also want to wait for specific data feeds to be available on HDFS
You want to run a workflow that depends on other workflows.
Benefits
Easily define all your requirements for triggering your workflow in an XML file
Avoid running multiple crontabs to trigger your workflows.
Avoid writing custom scripts that poll HDFS to check for input data and trigger workflows.
Oozie is provided as a service by the Grid Operations Team. You do not need to install software to start using Oozie on the Grid.
Question : From the Acmeshell.com website you have your all the data stored in Oracle database table called MAIN.PROFILES table. In HDFS you already
have your Apache WebServer log file stored called users_activity.log . Now you want to combine/join both the data users_activity.log file and MAIN.PROFILES
table. Initailly, you want to import the table data from the database into Hive using Sqoop with the default setting. Select the correct statement for this import
to HIve table.
1. It will use default delimiter 0x01 (^B)
2. It will use default delimiter 0x01 (^A)
3. Access Mostly Uused Products by 50000+ Subscribers
4. It will use default delimiter 0x01 (,)
5. None of the above
Ans : 2
Exp : Even though Hive supports escaping characters, it does not handle escaping of new-line character. Also, it does not support the notion of enclosing characters that may include
field delimiters in the enclosed string. It is therefore recommended that you choose unambiguous field and record-terminating delimiters without the help of escaping and enclosing
characters when working with Hive; this is due to limitations of Hive's input parsing abilities. If you do use --escaped-by, --enclosed-by, or --optionally-enclosed-by when importing
data into Hive, Sqoop will print a warning message. Hive will have problems using Sqoop-imported data if your database's rows contain string fields that have Hive's default row
delimiters (\n and \r characters) or column delimiters (\01 characters) present in them. You can use the --hive-drop-import-delims option to drop those characters on import to give
Hive-compatible text data. Alternatively, you can use the --hive-delims-replacement option to replace those characters with a user-defined string on import to give Hive-compatible
text data. These options should only be used if you use Hive's default delimiters and should not be used if different delimiters are specified.
Sqoop will pass the field and record delimiters through to Hive. If you do not set any delimiters and do use --hive-import, the field delimiter will be set to ^A and the record
delimiter will be set to \n to be consistent with Hive's defaults.By default Sqoop uses Hive's default delimiters when doing a Hive table export, which is 0x01 (^A). The table name
used in Hive is, by default, the same as that of the source table. You can control the output table name with the --hive-table option. Hive can put data into partitions for more
efficient query performance. You can tell a Sqoop job to import data for Hive into a particular partition by specifying the --hive-partition-key and --hive-partition-value arguments.
The partition value must be a string. Please see the Hive documentation for more details on partitioning.
Question
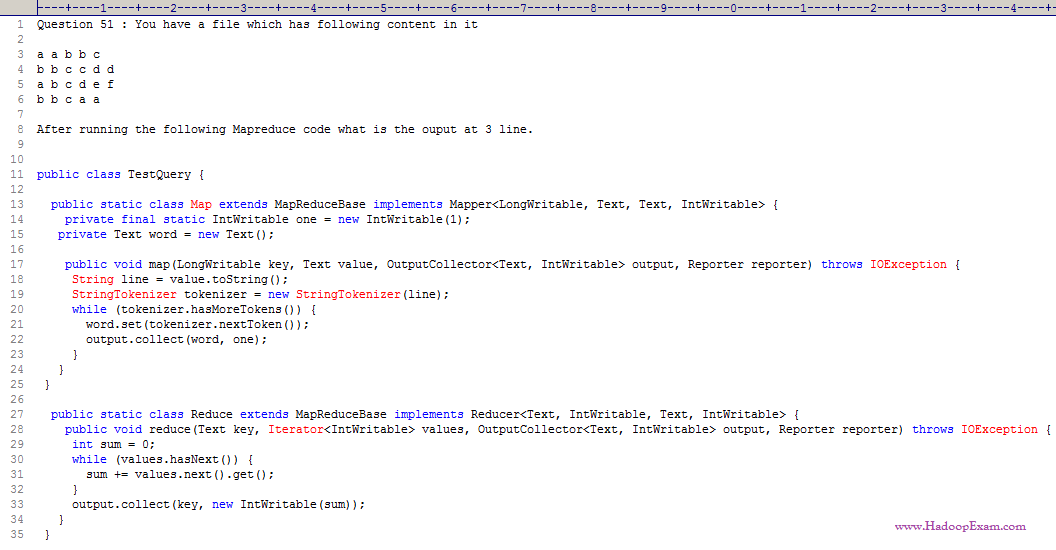
1. a 5
2. 5 a
3. Access Mostly Uused Products by 50000+ Subscribers
4. c 5
5. 5 c
Ans : 4
Exp : This is an example of Word Count code.
Note : Dont Remember Answers, please understand MapReduce in Depth. It is needed to clear live Question Exam Pattern
Question
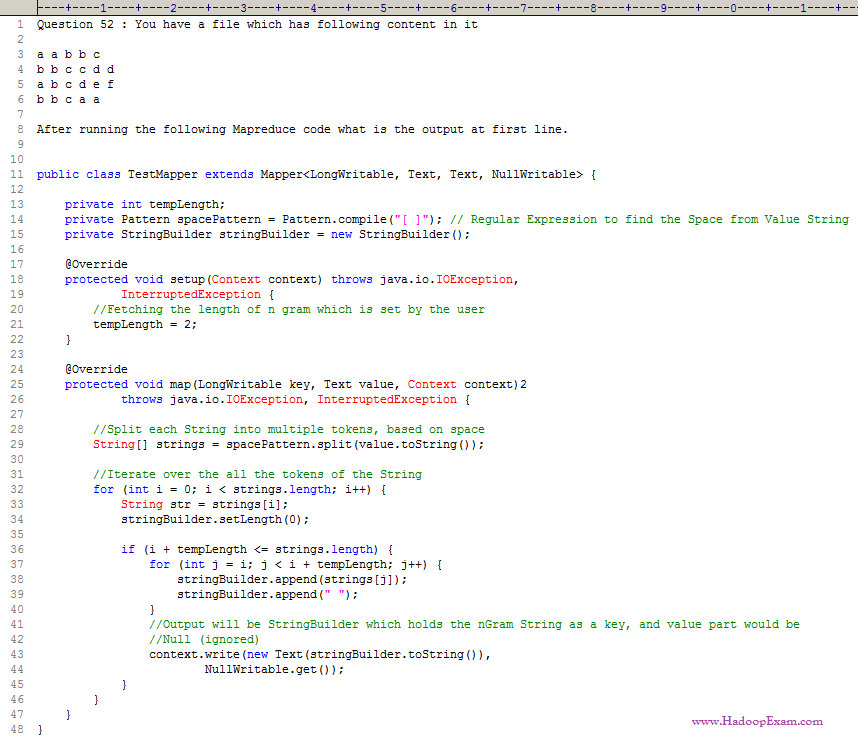
1. a a
2. b b
3. Access Mostly Uused Products by 50000+ Subscribers
4. d d
Ans : 1
Exp : This is an example of BiGram Implementation. Training Module 15 of HadoopExam.com
An n-gram is a contiguous sequence of n items from a given sequence of text or speech.
An n-gram of size 1 is referred to as a "unigram"
size 2 is a "bigram" (or, less commonly, a "digram")
size 3 is a "trigram".
Larger sizes are sometimes referred to by the value of n, e.g., "four-gram", "five-gram", and so on.
Note : Dont Remember Answers, please understand MapReduce in Depth. It is needed to clear live Question Exam Pattern
Question
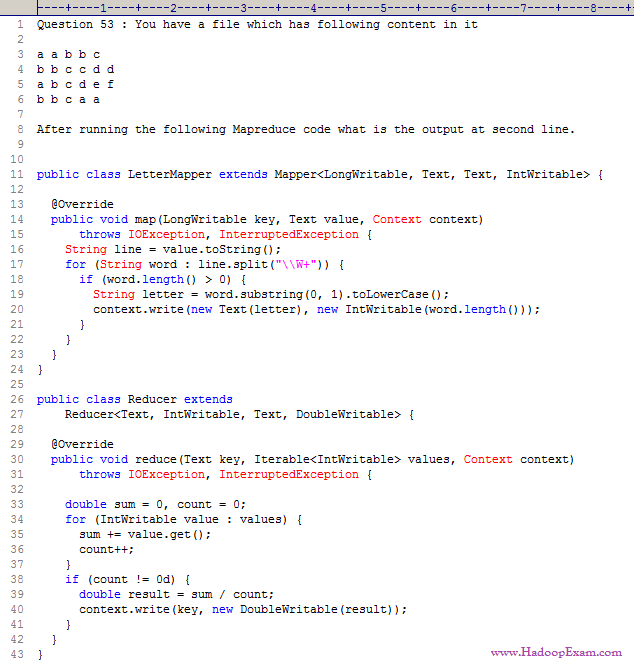
1. a 1
2. b 1
3. Access Mostly Uused Products by 50000+ Subscribers
4. d 1
Ans : 2
Exp : This is the code for calculating average length of each word starting with a unique character.
Each word here is single character, hence the average length for each character is 1 only.
Dont Remember Answers, please understand MapReduce in Depth. It is needed to clear live Question Exam Pattern
Question
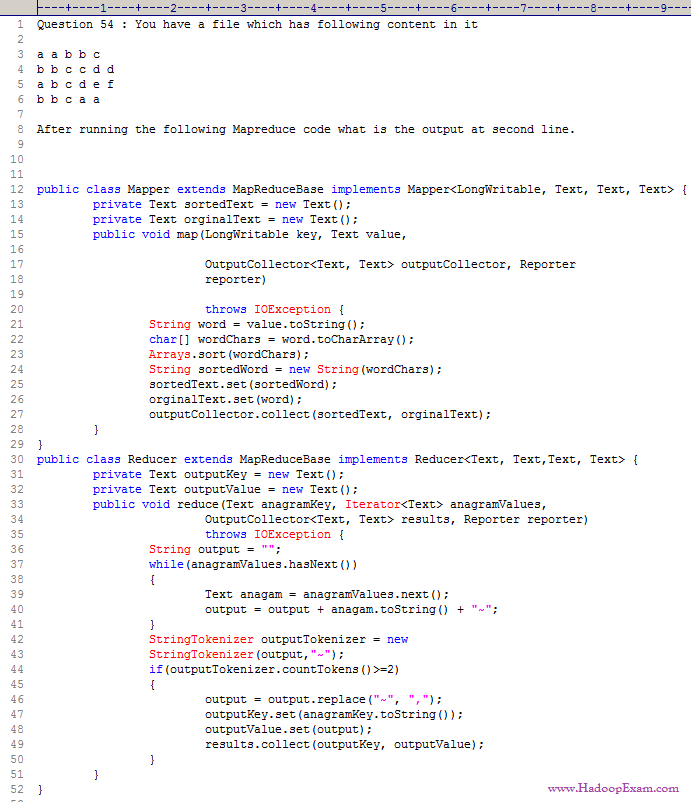
1. a a b b c , b b c a a
2. a a b b c, b b c c d d
3. Access Mostly Uused Products by 50000+ Subscribers
4. b b c a a, b b c a a
Ans : 1 Exp :
The Anagram mapper class gets a word as a line from the HDFS input and sorts the
letters in the word and writes its back to the output collector as
Key : sorted word (letters in the word sorted)
Value: the word itself as the value.
When the reducer runs then we can group anagrams together based on the sorted key.
The Anagram reducer class groups the values of the sorted keys that came in and
checks to see if the values iterator contains more than one word. if the values
contain more than one word we have spotted a anagram.
Question

1.
2.
3. Access Mostly Uused Products by 50000+ Subscribers
Please find the answer to this Question at following URL in detail with explanation.
www.hadoopexam.com/P5_A55.jpg
Dont Remember Answers, please understand MapReduce in Depth. It is needed to clear live Question Exam Pattern
Question You have given following input file data..
119:12,Hadoop,Exam,ccd410
312:44,Pappu,Pass,cca410
441:53,"HBasa","Pass","ccb410"
5611:01',"No Event",
7881:12,Hadoop,Exam,ccd410
3451:12,HadoopExam
Special characters . * + ? ^ $ { [ ( | ) \ have special meaning and must be escaped with \ to be used without the special meaning : \. \* \+ \? \^ \$ \{ \[ \( \| \) \\Consider the
meaning of regular expression as well
. any char, exactly 1 time
* any char, 0-8 times
+ any char, 1-8 times
? any char, 0-1 time
^ start of string (or line if multiline mode)
$ end of string (or line if multiline mode)
| equivalent to OR (there is no AND, check the reverse of what you need for AND)
After running the following MapReduce job what will be the output printed at console

1. 2 , 3
2. 2 , 4
3. Access Mostly Uused Products by 50000+ Subscribers
4. 5 , 1
5. 0 , 6
Correct Ans : 5
Exp : Meaning of regex as . any char, exactly 1 time (Please remember the regex)
* any char, 0-8 times
+ any char, 1-8 times
? any char, 0-1 time
^ start of string (or line if multiline mode)
$ end of string (or line if multiline mode)
| equivalent to OR (there is no AND, check the reverse of what you need for AND). First Record passed the regular expression
Second record also pass the expression
third record does not pass the expression, because hours part is in single digit as you can see in the expression
first two d's are there.
It is expected that each record should have at least all five character as digit. Which no record suffice.
Hence in total matching records are 0 and non-matching records are 6
Please learn java regular expression it is mandatory. Consider using Hadoop Professional Training Provided by HadoopExam.com if you face the problem.
Question
What happens when you run the below job twice , having each input directory as one of the data file called data.csv.
with following command. Assuming there were no output directory exist
hadoop job HadoopExam.jar HadoopExam inputdata_1 output
hadoop job HadoopExam.jar HadoopExam inputdata_2 output
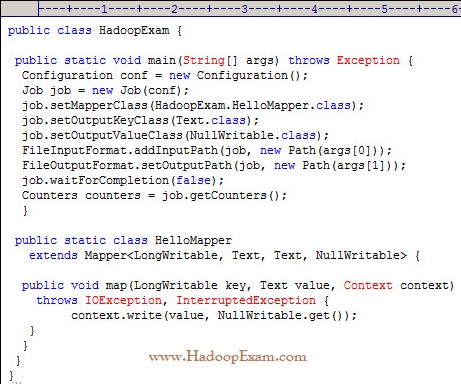
1. Both the job will write the output to output directory and output will be appended
2. Both the job will fail, saying output directory does not exist.
3. Access Mostly Uused Products by 50000+ Subscribers
4. Both the job will successfully complete and second job will overwrite the output of first.
Ans : 3
Exp : First job will successfully run and second one will fail, because, if (output directory already exist then it will not run
and throws exception, complaining output directory already exist.
Question : Which of the following utilities allows you to create and run MapReduce jobs with any executable or script
as the mapper and or the reducer?
1. Oozie
2. Sqoop
3. Access Mostly Uused Products by 50000+ Subscribers
4. Hadoop Streaming
Question : You need a distributed, scalable, data Store that allows you random, real-time read-write access to hundreds of terabytes of data.
Which of the following would you use?
1. Hue
2. Pig
3. Access Mostly Uused Products by 50000+ Subscribers
4. Oozie
5. HBase
Question : Workflows expressed in Oozie can contain:
1. Iterative repetition of MapReduce jobs until a desired answer or state is reached.
2. Sequences of MapReduce and Pig jobs. These are limited to linear sequences of actions with exception handlers but no forks.
3. Access Mostly Uused Products by 50000+ Subscribers
4. Sequences of MapReduce and Pig. These sequences can be combined with other actions including forks, decision points, and path joins.
Question : You have an employee who is a Date Analyst and is very comfortable with SQL.
He would like to run ad-hoc analysis on data in your HDFS duster.
Which of the following is a data warehousing software built on top of
Apache Hadoop that defines a simple SQL-like query language well-suited for this kind of user?
A. Pig B. Hue C. Hive D. Sqoop E. Oozie
1. A
2. B
3. Access Mostly Uused Products by 50000+ Subscribers
4. D
5. E
Question : You need to import a portion of a relational database every day as files to HDFS,
and generate Java classes to Interact with your imported data. Which of the following tools should you use to accomplish this?
A. Pig B. Hue C. Hive D. Flume E. Sqoop F. Oozie G. fuse-dfs
1. A,B
2. B,C
3. Access Mostly Uused Products by 50000+ Subscribers
4. F,G