SAS Certified BI Content Developer for SAS 9 and Business Analytics Questions and Answer (Dumps and Practice Questions)
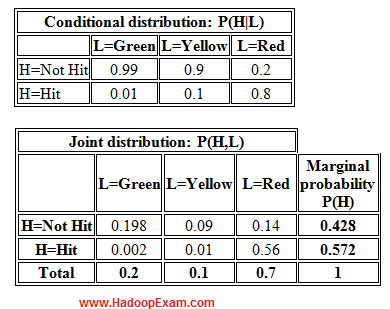
Question : Assume a $ cost for soliciting a non-responder and a $ profit for soliciting a responder.
The logistic regression model gives a probability score named P_R on a SAS data set called VALID. The VALID
data set contains the responder variable Pinch, a 1/0 variable coded as 1 for responder. Customers will
be solicited when their probability score is more than 0.05. Which SAS program computes the profit for
each customer in the data set VALID?
1. A
2. B
3. C
4. D
Correct Answer : 1
Question : In order to perform honest assessment on a predictive model, what is an acceptable division between training, validation, and testing data?

1. Training: 50% Validation: 0% Testing: 50%
2. Training: 100% Validation: 0% Testing: 0%
3. Training: 0% Validation: 100% Testing: 0%
4. Training: 50% Validation: 50% Testing: 0%
Correct Answer : 4
The acronym SEMMA - sample, explore, modify, model, assess - refers to the core process of conducting data mining. Beginning with a statistically representative sample of your data, SEMMA makes it easy to apply exploratory statistical and visualization techniques, select and transform the most significant predictive variables, model the variables to predict outcomes, and confirm a model's accuracy.
Before examining each stage of SEMMA, a common misunderstanding is to refer to SEMMA as a data mining methodology. SEMMA is not a data mining methodology but rather a logical organization of the functional tool set of SAS Enterprise Miner for carrying out the core tasks of data mining. Enterprise Miner can be used as part of any iterative data mining methodology adopted by the client. Naturally steps such as formulating a well defined business or research problem and assembling quality representative data sources are critical to the overall success of any data mining project. SEMMA is focused on the model development aspects of data mining:
* Sample (optional) your data by extracting a portion of a large data set big enough to contain the significant information, yet small enough to manipulate
quickly. For optimal cost and performance, SAS Institute advocates a sampling strategy, which applies a reliable, statistically representative sample of large full detail data sources. Mining a representative sample instead of the whole volume reduces the processing time required to get crucial business information. If general patterns appear in the data as a whole, these will be traceable in a representative sample. If a niche is so tiny that it's not represented in a sample and yet so important that it influences the big picture, it can be discovered using summary methods. We also advocate creating partitioned data sets with the Data Partition node:
* Training - used for model fitting.
* Validation - used for assessment and to prevent over fitting.
* Test - used to obtain an honest assessment of how well a model generalizes.
* Explore your data by searching for unanticipated trends and anomalies in order to gain understanding and ideas. Exploration helps refine the discovery process. If visual exploration doesn't reveal clear trends, you can explore the data through statistical techniques including factor analysis, correspondence analysis, and clustering. For example, in data mining for a direct mail campaign, clustering might reveal groups of customers with distinct ordering patterns. Knowing these patterns creates opportunities for personalized mailings or promotions.
* Modify your data by creating, selecting, and transforming the variables to focus the model selection process. Based on your discoveries in the exploration phase, you may need to manipulate your data to include information such as the grouping of customers and significant subgroups, or to introduce new variables. You may also need to look for outliers and reduce the number of variables, to narrow them down to the most significant ones. You may also need to modify data when the "mined" data change. Because data mining is a dynamic, iterative process, you can update data mining methods or models when new information is available.
* Model your data by allowing the software to search automatically for a combination of data that reliably predicts a desired outcome. Modeling techniques in
data mining include neural networks, tree-based models, logistic models, and other statistical models - such as time series analysis, memory-based
reasoning, and principal components. Each type of model has particular strengths, and is appropriate within specific data mining situations depending on
the data. For example, neural networks are very good at fitting highly complex nonlinear relationships.
* Assess your data by evaluating the usefulness and reliability of the findings from the data mining process and estimate how well it performs. A common
means of assessing a model is to apply it to a portion of data set aside during the sampling stage. If the model is valid, it should work for this reserved
sample as well as for the sample used to construct the model. Similarly, you can test the model against known data. For example, if you know which
customers in a file had high retention rates and your model predicts retention, you can check to see whether the model selects these customers
accurately. In addition, practical applications of the model, such as partial mailings in a direct mail campaign, help prove its validity.
By assessing the results gained from each stage of the SEMMA process, you can determine how to model new questions raised by the previous results, and thus
proceed back to the exploration phase for additional refinement of the data. Once you have developed the champion model using the SEMMA based mining approach, it then needs to be deployed to score new customer cases. Model deployment is the end result of data mining - the final phase in which the ROI from the mining process is realized. Enterprise Miner automates the deployment phase by supplying scoring code in SAS, C, Java, and PMML. It not only captures the code for of analytic models but also captures the code for preprocessing activities. You can seamlessly score your production data on a different machine, and deploy the scoring code in batch or real-time on the Web or in directly in relational databases. This results in faster implementation and frees you to spend more time evaluating existing models and developing new ones.
Question : Refer to the exhibit:
Based upon the comparative ROC plot for two competing models,
which is the champion model and why?

1. Candidate 1, because the area outside the curve is greater
2. Candidate 2, because the area under the curve is greater
3. Candidate 1, because it is closer to the diagonal reference curve
4. Candidate 2, because it shows less over fit than Candidate 1
Correct Answer : 2
The Gini (ROC and Trend) reports show you the predictive accuracy of a model that has a binary target. The plot displays sensitivity information about the y-axis and 1-Specificity information about the x-axis. Sensitivity is the proportion of true positive events. Specificity is the proportion of true negative events. The Gini index is calculated for each ROC curve. The Gini coefficient, which represents the area under the ROC curve, is a benchmark statistic that can be used to summarize the predictive accuracy of a model.
Refer study notes as well.
Related Questions
Question : An analyst fits a logistic regression model to predict whether
or not a client will default on a loan. One of the predictors
in the model is agent, and each agent serves 15-20 clients each.
The model fails to converge. The analyst prints the summarized data,
showing the number of defaulted loans per agent. See the partial output below:
What is the most likely reason that the model fails to converge?

1. There is quasi-complete separation in the data.
2. There is collinearity among the predictors.
3. There are missing values in the data
4. There are too many observations in the data.
Question : An analyst knows that the categorical predictor, storeId, is an important
predictor of the target.However, store_Id has too many levels to be a feasible predictor in the model.
The analyst wants to combine stores and treat them as members of the same class level.
What are the two most effective ways to address the problem?
A. Eliminate store_id as a predictor in the model because it has too many levels to be feasible.
B. Cluster by using Greenacre's method to combine stores that are similar.
C. Use subject matter expertise to combine stores that are similar.
D. Randomly combine the stores into five groups to keep the stochastic variation among the observations intact.
1. A,B
2. B,C
3. C,D
4. A,D
Question :
Including redundant input variables in a regression model can:
1. Stabilize parameter estimates and increase the risk of overfitting.
2. Destabilize parameter estimates and increase the risk of overfitting.
3. Stabilize parameter estimates and decrease the risk of overfitting.
4. Destabilize parameter estimates and decrease the risk of overfitting.
Question : An analyst investigates Region (A, B, or C) as an input variable in a logistic regression model.
The analyst discovers that the probability of purchasing a certain item when Region = A is 1. What problem does this illustrate?

1. Collinearity
2. Influential observations
3. Quasi-complete separation
4. Problems that arise due to missing values
Question : Refer to the following exhibit:
What is a correct interpretation of this graph?

1. The association between the continuous predictor and the binary response is quadratic.
2. The association between the continuous predictor and the log-odds is quadratic.
3. Access Mostly Uused Products by 50000+ Subscribers
4. The association between the binary predictor and the log-odds is quadratic.
Question : This question will ask you to provide a missing option.
Given the following SAS program:
What option must be added to the program to obtain a
data set containing Pearson statistics?

1. OUTPUT=estimates
2. OUTP=estimates
3. Access Mostly Uused Products by 50000+ Subscribers
4. OUTCORR=estimates